 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Marketplace for AI-Generated Adult Content and Deepfakes
Jan 14, 2026Generative AI systems increasingly enable the production of highly realistic synthetic media. Civitai, a popular community-driven platform for AI-generated content, operates a monetized feature called Bounties, which allows users to commission the generation of content in exchange for payment. To examine how this mechanism is used and what content it incentivizes, we conduct a longitudinal analysis of all publicly available bounty requests collected over a 14-month period following the platform's launch. We find that the bounty marketplace is dominated by tools that let users steer AI models toward content they were not trained to generate. At the same time, requests for content that is "Not Safe For Work" are widespread and have increased steadily over time, now comprising a majority of all bounties. Participation in bounty creation is uneven, with 20% of requesters accounting for roughly half of requests. Requests for "deepfake" - media depicting identifiable real individuals - exhibit a higher concentration than other types of bounties. A nontrivial subset of these requests involves explicit deepfakes despite platform policies prohibiting such content. These bounties disproportionately target female celebrities, revealing a pronounced gender asymmetry in social harm. Together, these findings show how monetized, community-driven generative AI platforms can produce gendered harms, raising questions about consent, governance, and enforcement.
An Unsupervised Normalization Algorithm for Noisy Text: A Case Study for Information Retrieval and Stance Detection
Jan 09, 2021
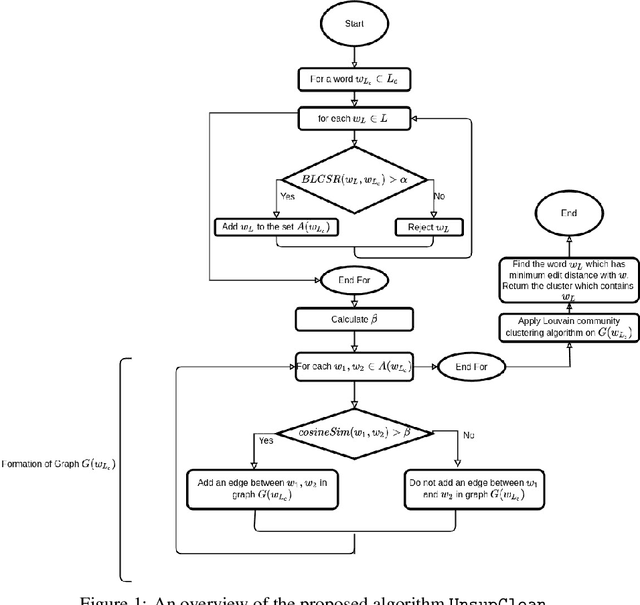
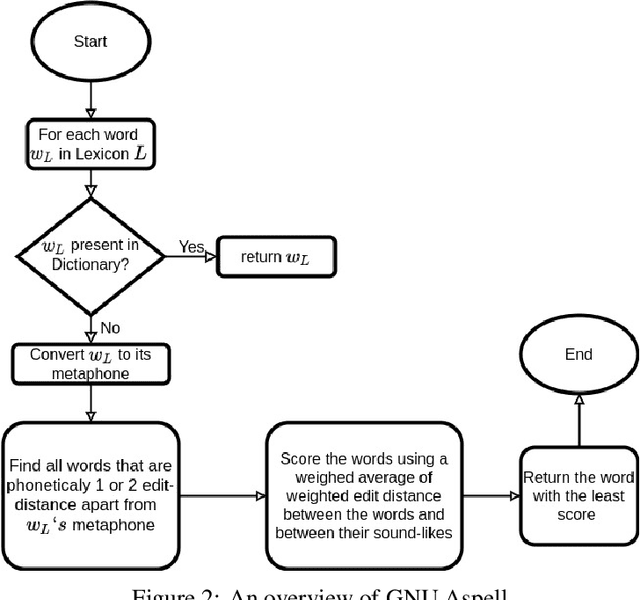

A large fraction of textual data available today contains various types of 'noise', such as OCR noise in digitized documents, noise due to informal writing style of users on microblogging sites, and so on. To enable tasks such as search/retrieval and classification over all the available data, we need robust algorithms for text normalization, i.e., for cleaning different kinds of noise in the text. There have been several efforts towards cleaning or normalizing noisy text; however, many of the existing text normalization methods are supervised and require language-dependent resources or large amounts of training data that is difficult to obtain. We propose an unsupervised algorithm for text normalization that does not need any training data / human intervention. The proposed algorithm is applicable to text over different languages, and can handle both machine-generated and human-generated noise. Experiments over several standard datasets show that text normalization through the proposed algorithm enables better retrieval and stance detection, as compared to that using several baseline text normalization methods. Implementation of our algorithm can be found at https://github.com/ranarag/UnsupClean.
Stance Detection in Web and Social Media: A Comparative Study
Jul 12, 2020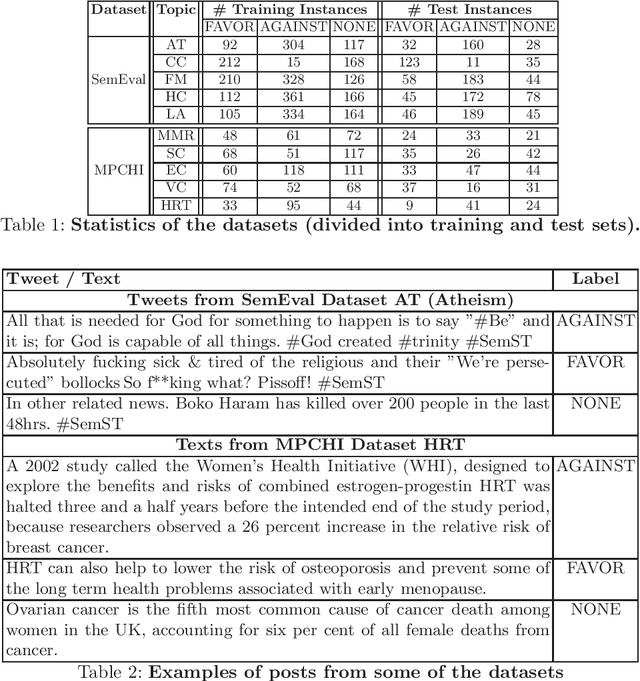

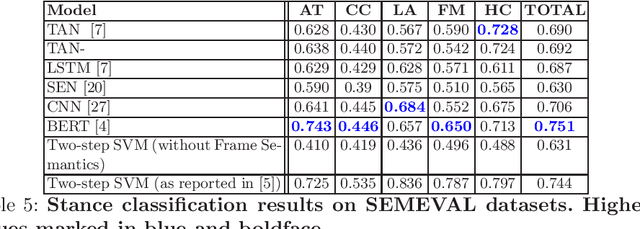
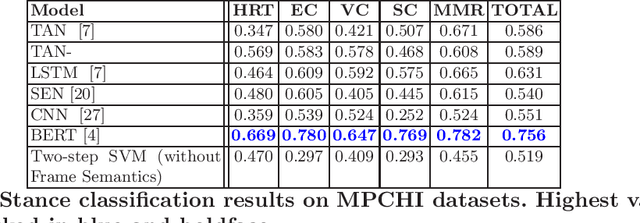
Online forums and social media platforms are increasingly being used to discuss topics of varying polarities where different people take different stances. Several methodologies for automatic stance detection from text have been proposed in literature. To our knowledge, there has not been any systematic investigation towards their reproducibility, and their comparative performances. In this work, we explore the reproducibility of several existing stance detection models, including both neural models and classical classifier-based models. Through experiments on two datasets -- (i)~the popular SemEval microblog dataset, and (ii)~a set of health-related online news articles -- we also perform a detailed comparative analysis of various methods and explore their shortcomings. Implementations of all algorithms discussed in this paper are available at https://github.com/prajwal1210/Stance-Detection-in-Web-and-Social-Media.