 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConversational Prompt Engineering
Aug 08, 2024



Prompts are how humans communicate with LLMs. Informative prompts are essential for guiding LLMs to produce the desired output. However, prompt engineering is often tedious and time-consuming, requiring significant expertise, limiting its widespread use. We propose Conversational Prompt Engineering (CPE), a user-friendly tool that helps users create personalized prompts for their specific tasks. CPE uses a chat model to briefly interact with users, helping them articulate their output preferences and integrating these into the prompt. The process includes two main stages: first, the model uses user-provided unlabeled data to generate data-driven questions and utilize user responses to shape the initial instruction. Then, the model shares the outputs generated by the instruction and uses user feedback to further refine the instruction and the outputs. The final result is a few-shot prompt, where the outputs approved by the user serve as few-shot examples. A user study on summarization tasks demonstrates the value of CPE in creating personalized, high-performing prompts. The results suggest that the zero-shot prompt obtained is comparable to its - much longer - few-shot counterpart, indicating significant savings in scenarios involving repetitive tasks with large text volumes.
Stay Tuned: An Empirical Study of the Impact of Hyperparameters on LLM Tuning in Real-World Applications
Jul 25, 2024



Fine-tuning Large Language Models (LLMs) is an effective method to enhance their performance on downstream tasks. However, choosing the appropriate setting of tuning hyperparameters (HPs) is a labor-intensive and computationally expensive process. Here, we provide recommended HP configurations for practical use-cases that represent a better starting point for practitioners, when considering two SOTA LLMs and two commonly used tuning methods. We describe Coverage-based Search (CBS), a process for ranking HP configurations based on an offline extensive grid search, such that the top ranked configurations collectively provide a practical robust recommendation for a wide range of datasets and domains. We focus our experiments on Llama-3-8B and Mistral-7B, as well as full fine-tuning and LoRa, conducting a total of > 10,000 tuning experiments. Our results suggest that, in general, Llama-3-8B and LoRA should be preferred, when possible. Moreover, we show that for both models and tuning methods, exploring only a few HP configurations, as recommended by our analysis, can provide excellent results in practice, making this work a valuable resource for practitioners.
VIRATrustData: A Trust-Annotated Corpus of Human-Chatbot Conversations About COVID-19 Vaccines
May 24, 2022
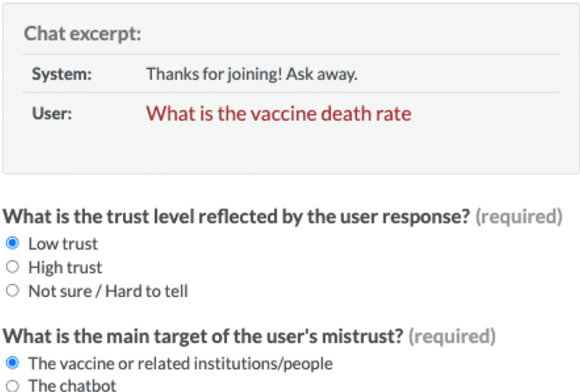
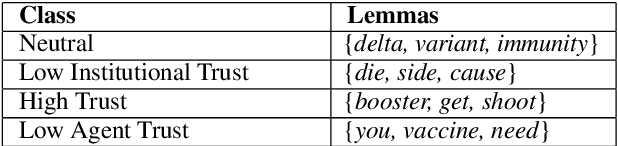
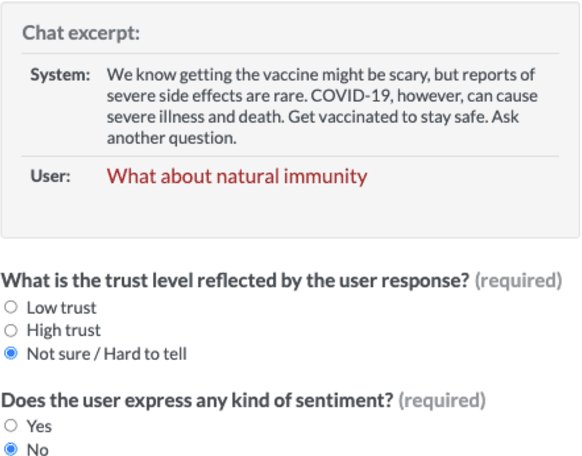
Public trust in medical information is crucial for successful application of public health policies such as vaccine uptake. This is especially true when the information is offered remotely, by chatbots, which have become increasingly popular in recent years. Here, we explore the challenging task of human-bot turn-level trust classification. We rely on a recently released data of observationally-collected (rather than crowdsourced) dialogs with VIRA chatbot, a COVID-19 Vaccine Information Resource Assistant. These dialogs are centered around questions and concerns about COVID-19 vaccines, where trust is particularly acute. We annotated $3k$ VIRA system-user conversational turns for Low Institutional Trust or Low Agent Trust vs. Neutral or High Trust. We release the labeled dataset, VIRATrustData, the first of its kind to the best of our knowledge. We demonstrate how this task is non-trivial and compare several models that predict the different levels of trust.
Benchmark Data and Evaluation Framework for Intent Discovery Around COVID-19 Vaccine Hesitancy
May 24, 2022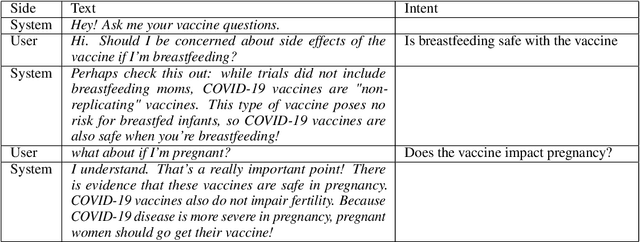
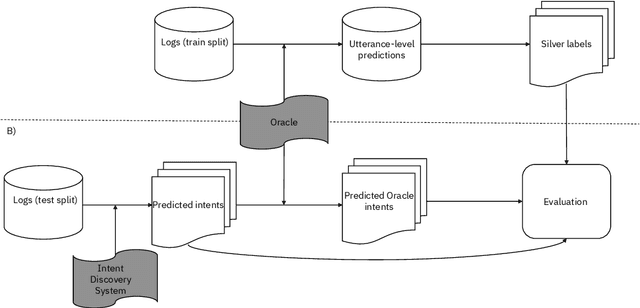

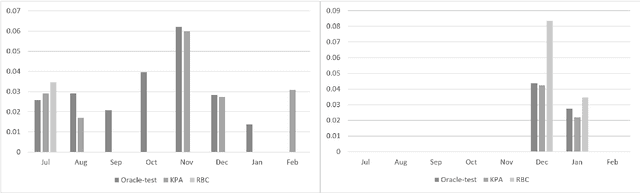
The COVID-19 pandemic has made a huge global impact and cost millions of lives. As COVID-19 vaccines were rolled out, they were quickly met with widespread hesitancy. To address the concerns of hesitant people, we launched VIRA, a public dialogue system aimed at addressing questions and concerns surrounding the COVID-19 vaccines. Here, we release VIRADialogs, a dataset of over 8k dialogues conducted by actual users with VIRA, providing a unique real-world conversational dataset. In light of rapid changes in users' intents, due to updates in guidelines or as a response to new information, we highlight the important task of intent discovery in this use-case. We introduce a novel automatic evaluation framework for intent discovery, leveraging the existing intent classifier of a given dialogue system. We use this framework to report baseline intent-discovery results over VIRADialogs, that highlight the difficulty of this task.
The workweek is the best time to start a family -- A Study of GPT-2 Based Claim Generation
Oct 13, 2020
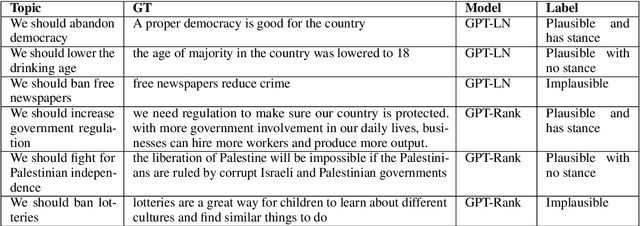


Argument generation is a challenging task whose research is timely considering its potential impact on social media and the dissemination of information. Here we suggest a pipeline based on GPT-2 for generating coherent claims, and explore the types of claims that it produces, and their veracity, using an array of manual and automatic assessments. In addition, we explore the interplay between this task and the task of Claim Retrieval, showing how they can complement one another.
What if we had no Wikipedia? Domain-independent Term Extraction from a Large News Corpus
Sep 17, 2020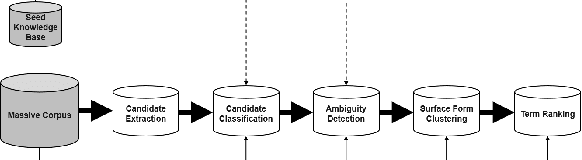
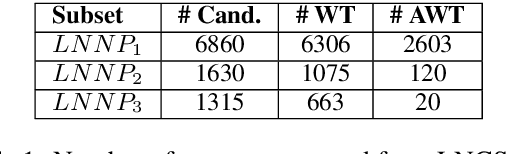
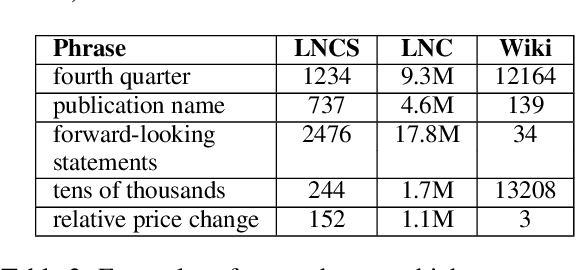
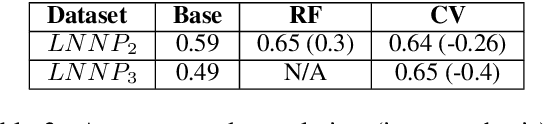
One of the most impressive human endeavors of the past two decades is the collection and categorization of human knowledge in the free and accessible format that is Wikipedia. In this work we ask what makes a term worthy of entering this edifice of knowledge, and having a page of its own in Wikipedia? To what extent is this a natural product of on-going human discourse and discussion rather than an idiosyncratic choice of Wikipedia editors? Specifically, we aim to identify such "wiki-worthy" terms in a massive news corpus, and see if this can be done with no, or minimal, dependency on actual Wikipedia entries. We suggest a five-step pipeline for doing so, providing baseline results for all five, and the relevant datasets for benchmarking them. Our work sheds new light on the domain-specific Automatic Term Extraction problem, with the problem at hand being a domain-independent variant of it.
A Large-scale Dataset for Argument Quality Ranking: Construction and Analysis
Nov 26, 2019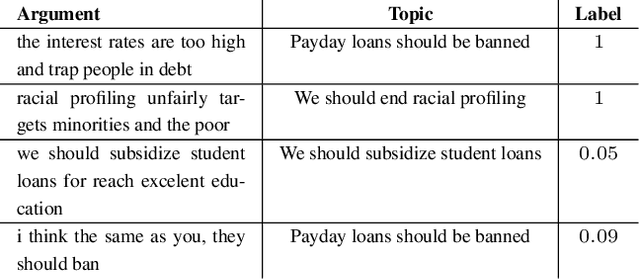
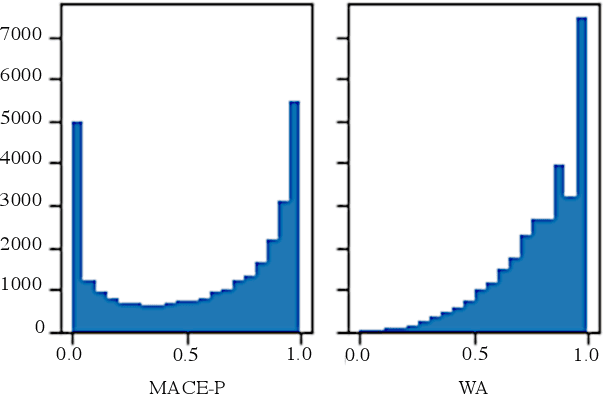

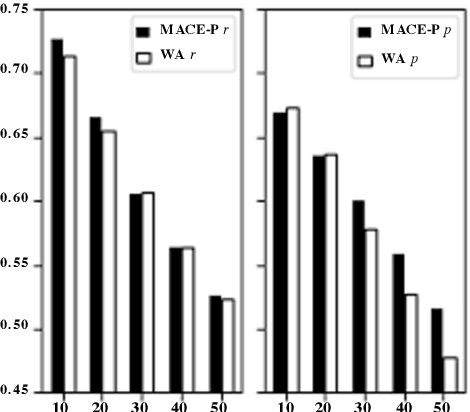
Identifying the quality of free-text arguments has become an important task in the rapidly expanding field of computational argumentation. In this work, we explore the challenging task of argument quality ranking. To this end, we created a corpus of 30,497 arguments carefully annotated for point-wise quality, released as part of this work. To the best of our knowledge, this is the largest dataset annotated for point-wise argument quality, larger by a factor of five than previously released datasets. Moreover, we address the core issue of inducing a labeled score from crowd annotations by performing a comprehensive evaluation of different approaches to this problem. In addition, we analyze the quality dimensions that characterize this dataset. Finally, we present a neural method for argument quality ranking, which outperforms several baselines on our own dataset, as well as previous methods published for another dataset.
Automatic Argument Quality Assessment -- New Datasets and Methods
Sep 03, 2019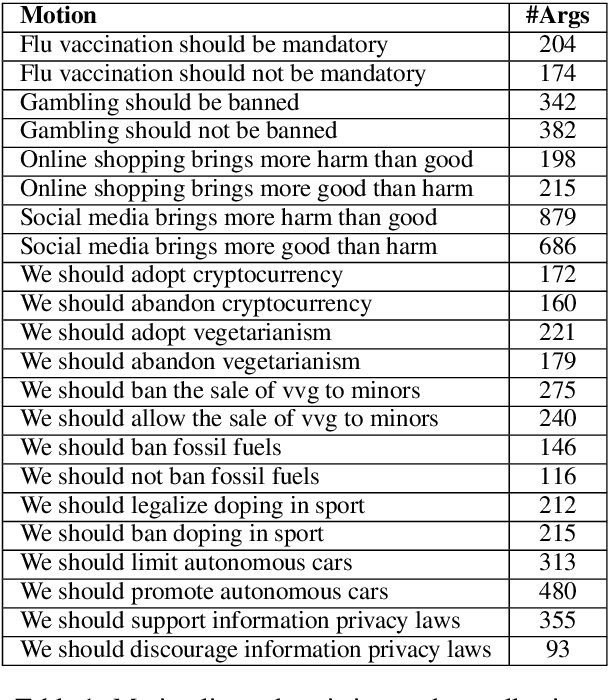
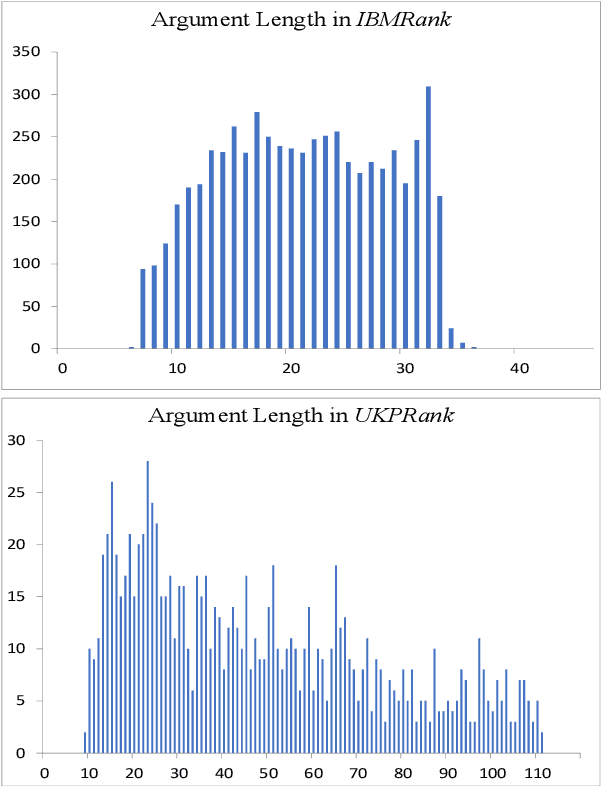
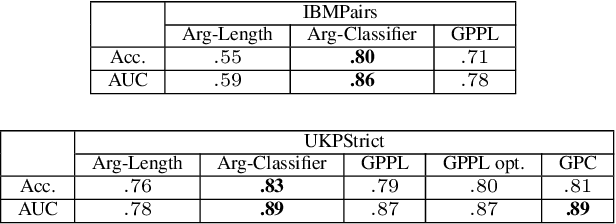
We explore the task of automatic assessment of argument quality. To that end, we actively collected 6.3k arguments, more than a factor of five compared to previously examined data. Each argument was explicitly and carefully annotated for its quality. In addition, 14k pairs of arguments were annotated independently, identifying the higher quality argument in each pair. In spite of the inherent subjective nature of the task, both annotation schemes led to surprisingly consistent results. We release the labeled datasets to the community. Furthermore, we suggest neural methods based on a recently released language model, for argument ranking as well as for argument-pair classification. In the former task, our results are comparable to state-of-the-art; in the latter task our results significantly outperform earlier methods.
Towards Effective Rebuttal: Listening Comprehension using Corpus-Wide Claim Mining
Jul 27, 2019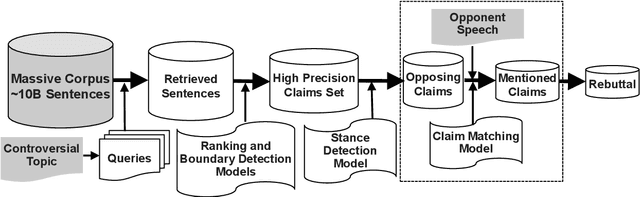
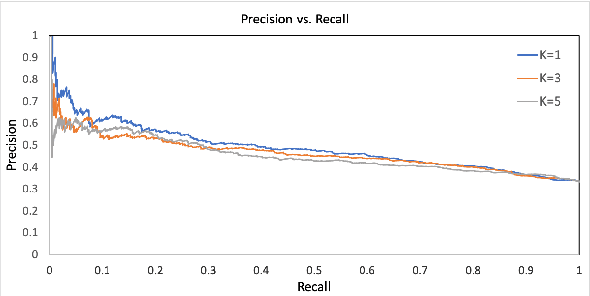
Engaging in a live debate requires, among other things, the ability to effectively rebut arguments claimed by your opponent. In particular, this requires identifying these arguments. Here, we suggest doing so by automatically mining claims from a corpus of news articles containing billions of sentences, and searching for them in a given speech. This raises the question of whether such claims indeed correspond to those made in spoken speeches. To this end, we collected a large dataset of $400$ speeches in English discussing $200$ controversial topics, mined claims for each topic, and asked annotators to identify the mined claims mentioned in each speech. Results show that in the vast majority of speeches debaters indeed make use of such claims. In addition, we present several baselines for the automatic detection of mined claims in speeches, forming the basis for future work. All collected data is freely available for research.