 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairness in Reinforcement Learning
Aug 06, 2017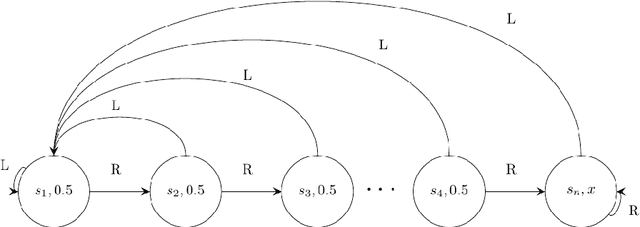

We initiate the study of fairness in reinforcement learning, where the actions of a learning algorithm may affect its environment and future rewards. Our fairness constraint requires that an algorithm never prefers one action over another if the long-term (discounted) reward of choosing the latter action is higher. Our first result is negative: despite the fact that fairness is consistent with the optimal policy, any learning algorithm satisfying fairness must take time exponential in the number of states to achieve non-trivial approximation to the optimal policy. We then provide a provably fair polynomial time algorithm under an approximate notion of fairness, thus establishing an exponential gap between exact and approximate fairness
A Convex Framework for Fair Regression
Jun 07, 2017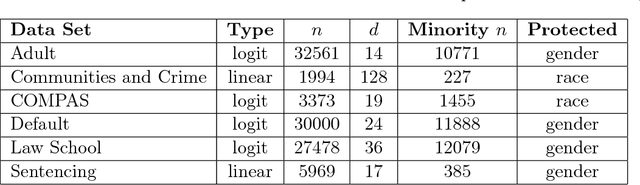
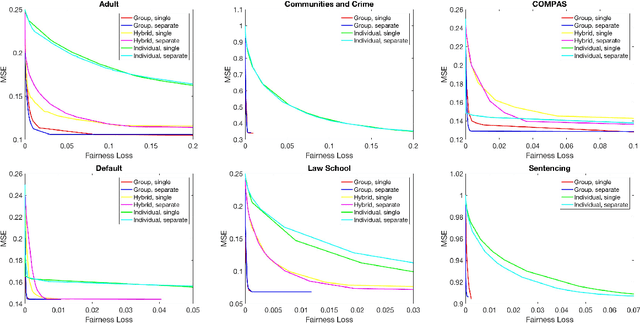
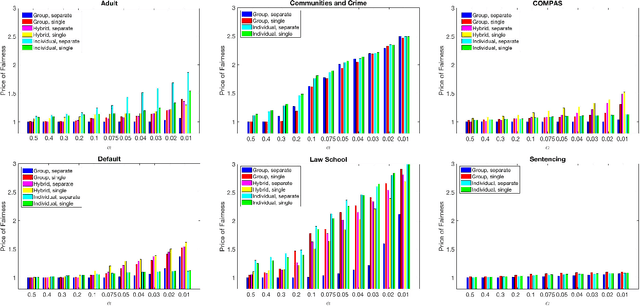
We introduce a flexible family of fairness regularizers for (linear and logistic) regression problems. These regularizers all enjoy convexity, permitting fast optimization, and they span the rang from notions of group fairness to strong individual fairness. By varying the weight on the fairness regularizer, we can compute the efficient frontier of the accuracy-fairness trade-off on any given dataset, and we measure the severity of this trade-off via a numerical quantity we call the Price of Fairness (PoF). The centerpiece of our results is an extensive comparative study of the PoF across six different datasets in which fairness is a primary consideration.
Fairness in Criminal Justice Risk Assessments: The State of the Art
May 28, 2017
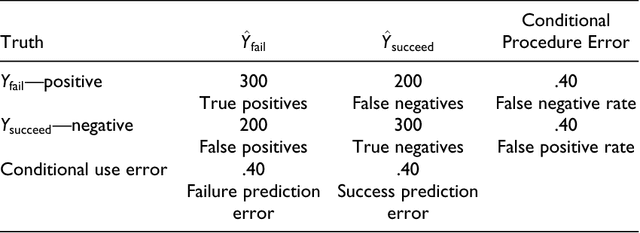
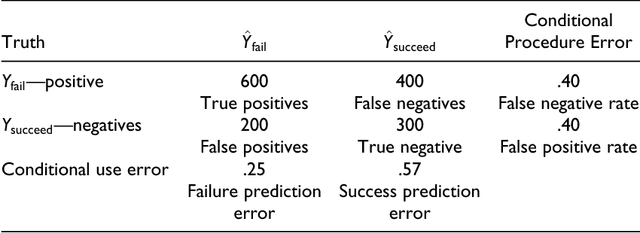
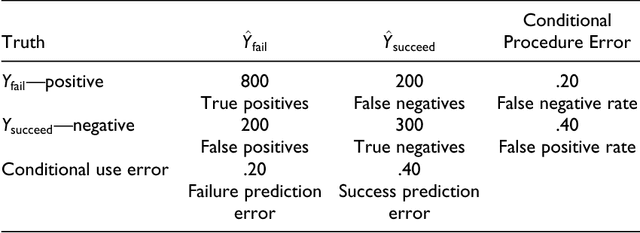
Objectives: Discussions of fairness in criminal justice risk assessments typically lack conceptual precision. Rhetoric too often substitutes for careful analysis. In this paper, we seek to clarify the tradeoffs between different kinds of fairness and between fairness and accuracy. Methods: We draw on the existing literatures in criminology, computer science and statistics to provide an integrated examination of fairness and accuracy in criminal justice risk assessments. We also provide an empirical illustration using data from arraignments. Results: We show that there are at least six kinds of fairness, some of which are incompatible with one another and with accuracy. Conclusions: Except in trivial cases, it is impossible to maximize accuracy and fairness at the same time, and impossible simultaneously to satisfy all kinds of fairness. In practice, a major complication is different base rates across different legally protected groups. There is a need to consider challenging tradeoffs.
Learning from Rational Behavior: Predicting Solutions to Unknown Linear Programs
Oct 26, 2016
We define and study the problem of predicting the solution to a linear program (LP) given only partial information about its objective and constraints. This generalizes the problem of learning to predict the purchasing behavior of a rational agent who has an unknown objective function, that has been studied under the name "Learning from Revealed Preferences". We give mistake bound learning algorithms in two settings: in the first, the objective of the LP is known to the learner but there is an arbitrary, fixed set of constraints which are unknown. Each example is defined by an additional known constraint and the goal of the learner is to predict the optimal solution of the LP given the union of the known and unknown constraints. This models the problem of predicting the behavior of a rational agent whose goals are known, but whose resources are unknown. In the second setting, the objective of the LP is unknown, and changing in a controlled way. The constraints of the LP may also change every day, but are known. An example is given by a set of constraints and partial information about the objective, and the task of the learner is again to predict the optimal solution of the partially known LP.