 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Frames in News Headlines and Lead Images in U.S. Gun Violence Coverage
Jun 25, 2024



News media structure their reporting of events or issues using certain perspectives. When describing an incident involving gun violence, for example, some journalists may focus on mental health or gun regulation, while others may emphasize the discussion of gun rights. Such perspectives are called \say{frames} in communication research. We study, for the first time, the value of combining lead images and their contextual information with text to identify the frame of a given news article. We observe that using multiple modes of information(article- and image-derived features) improves prediction of news frames over any single mode of information when the images are relevant to the frames of the headlines. We also observe that frame image relevance is related to the ease of conveying frames via images, which we call frame concreteness. Additionally, we release the first multimodal news framing dataset related to gun violence in the U.S., curated and annotated by communication researchers. The dataset will allow researchers to further examine the use of multiple information modalities for studying media framing.
The Machine Learning for Combinatorial Optimization Competition (ML4CO): Results and Insights
Mar 17, 2022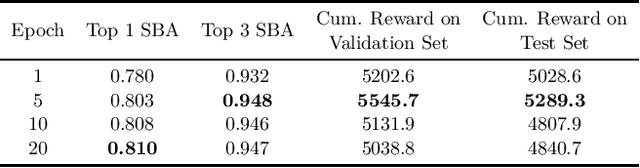

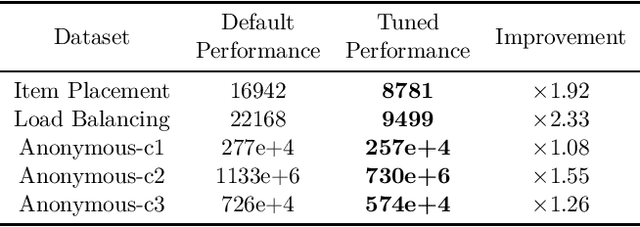
Combinatorial optimization is a well-established area in operations research and computer science. Until recently, its methods have focused on solving problem instances in isolation, ignoring that they often stem from related data distributions in practice. However, recent years have seen a surge of interest in using machine learning as a new approach for solving combinatorial problems, either directly as solvers or by enhancing exact solvers. Based on this context, the ML4CO aims at improving state-of-the-art combinatorial optimization solvers by replacing key heuristic components. The competition featured three challenging tasks: finding the best feasible solution, producing the tightest optimality certificate, and giving an appropriate solver configuration. Three realistic datasets were considered: balanced item placement, workload apportionment, and maritime inventory routing. This last dataset was kept anonymous for the contestants.
BUOCA: Budget-Optimized Crowd Worker Allocation
Jan 11, 2019
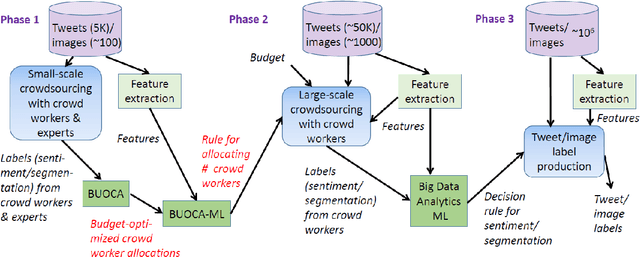
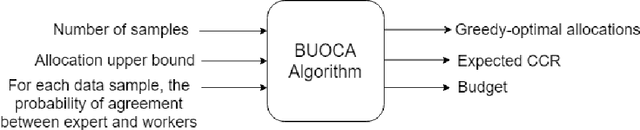

Due to concerns about human error in crowdsourcing, it is standard practice to collect labels for the same data point from multiple internet workers. We here show that the resulting budget can be used more effectively with a flexible worker assignment strategy that asks fewer workers to analyze easy-to-label data and more workers to analyze data that requires extra scrutiny. Our main contribution is to show how the allocations of the number of workers to a task can be computed optimally based on task features alone, without using worker profiles. Our target tasks are delineating cells in microscopy images and analyzing the sentiment toward the 2016 U.S. presidential candidates in tweets. We first propose an algorithm that computes budget-optimized crowd worker allocation (BUOCA). We next train a machine learning system (BUOCA-ML) that predicts an optimal number of crowd workers needed to maximize the accuracy of the labeling. We show that the computed allocation can yield large savings in the crowdsourcing budget (up to 49 percent points) while maintaining labeling accuracy. Finally, we envisage a human-machine system for performing budget-optimized data analysis at a scale beyond the feasibility of crowdsourcing.