 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtificial Text Boundary Detection with Topological Data Analysis and Sliding Window Techniques
Nov 14, 2023



Due to the rapid development of text generation models, people increasingly often encounter texts that may start out as written by a human but then continue as machine-generated results of large language models. Detecting the boundary between human-written and machine-generated parts of such texts is a very challenging problem that has not received much attention in literature. In this work, we consider and compare a number of different approaches for this artificial text boundary detection problem, comparing several predictors over features of different nature. We show that supervised fine-tuning of the RoBERTa model works well for this task in general but fails to generalize in important cross-domain and cross-generator settings, demonstrating a tendency to overfit to spurious properties of the data. Then, we propose novel approaches based on features extracted from a frozen language model's embeddings that are able to outperform both the human accuracy level and previously considered baselines on the Real or Fake Text benchmark. Moreover, we adapt perplexity-based approaches for the boundary detection task and analyze their behaviour. We analyze the robustness of all proposed classifiers in cross-domain and cross-model settings, discovering important properties of the data that can negatively influence the performance of artificial text boundary detection algorithms.
Machine Learning for SAT: Restricted Heuristics and New Graph Representations
Jul 18, 2023



Boolean satisfiability (SAT) is a fundamental NP-complete problem with many applications, including automated planning and scheduling. To solve large instances, SAT solvers have to rely on heuristics, e.g., choosing a branching variable in DPLL and CDCL solvers. Such heuristics can be improved with machine learning (ML) models; they can reduce the number of steps but usually hinder the running time because useful models are relatively large and slow. We suggest the strategy of making a few initial steps with a trained ML model and then releasing control to classical heuristics; this simplifies cold start for SAT solving and can decrease both the number of steps and overall runtime, but requires a separate decision of when to release control to the solver. Moreover, we introduce a modification of Graph-Q-SAT tailored to SAT problems converted from other domains, e.g., open shop scheduling problems. We validate the feasibility of our approach with random and industrial SAT problems.
Intrinsic Dimension Estimation for Robust Detection of AI-Generated Texts
Jun 07, 2023



Rapidly increasing quality of AI-generated content makes it difficult to distinguish between human and AI-generated texts, which may lead to undesirable consequences for society. Therefore, it becomes increasingly important to study the properties of human texts that are invariant over text domains and various proficiency of human writers, can be easily calculated for any language, and can robustly separate natural and AI-generated texts regardless of the generation model and sampling method. In this work, we propose such an invariant of human texts, namely the intrinsic dimensionality of the manifold underlying the set of embeddings of a given text sample. We show that the average intrinsic dimensionality of fluent texts in natural language is hovering around the value $9$ for several alphabet-based languages and around $7$ for Chinese, while the average intrinsic dimensionality of AI-generated texts for each language is $\approx 1.5$ lower, with a clear statistical separation between human-generated and AI-generated distributions. This property allows us to build a score-based artificial text detector. The proposed detector's accuracy is stable over text domains, generator models, and human writer proficiency levels, outperforming SOTA detectors in model-agnostic and cross-domain scenarios by a significant margin.
Searching by Code: a New SearchBySnippet Dataset and SnippeR Retrieval Model for Searching by Code Snippets
May 19, 2023



Code search is an important task that has seen many developments in recent years. However, previous attempts have mostly considered the problem of searching for code by a text query. We argue that using a code snippet (and possibly an associated traceback) as a query and looking for answers with bugfixing instructions and code samples is a natural use case that is not covered by existing approaches. Moreover, existing datasets use comments extracted from code rather than full-text descriptions as text, making them unsuitable for this use case. We present a new SearchBySnippet dataset implementing the search-by-code use case based on StackOverflow data; it turns out that in this setting, existing architectures fall short of the simplest BM25 baseline even after fine-tuning. We present a new single encoder model SnippeR that outperforms several strong baselines on the SearchBySnippet dataset with a result of 0.451 Recall@10; we propose the SearchBySnippet dataset and SnippeR as a new important benchmark for code search evaluation.
CCT-Code: Cross-Consistency Training for Multilingual Clone Detection and Code Search
May 19, 2023We consider the clone detection and information retrieval problems for source code, well-known tasks important for any programming language. Although it is also an important and interesting problem to find code snippets that operate identically but are written in different programming languages, to the best of our knowledge multilingual clone detection has not been studied in literature. In this work, we formulate the multilingual clone detection problem and present XCD, a new benchmark dataset produced from the CodeForces submissions dataset. Moreover, we present a novel training procedure, called cross-consistency training (CCT), that we apply to train language models on source code in different programming languages. The resulting CCT-LM model, initialized with GraphCodeBERT and fine-tuned with CCT, achieves new state of the art, outperforming existing approaches on the POJ-104 clone detection benchmark with 95.67\% MAP and AdvTest code search benchmark with 47.18\% MRR; it also shows the best results on the newly created multilingual clone detection benchmark XCD across all programming languages.
STIR: Siamese Transformer for Image Retrieval Postprocessing
Apr 27, 2023Current metric learning approaches for image retrieval are usually based on learning a space of informative latent representations where simple approaches such as the cosine distance will work well. Recent state of the art methods such as HypViT move to more complex embedding spaces that may yield better results but are harder to scale to production environments. In this work, we first construct a simpler model based on triplet loss with hard negatives mining that performs at the state of the art level but does not have these drawbacks. Second, we introduce a novel approach for image retrieval postprocessing called Siamese Transformer for Image Retrieval (STIR) that reranks several top outputs in a single forward pass. Unlike previously proposed Reranking Transformers, STIR does not rely on global/local feature extraction and directly compares a query image and a retrieved candidate on pixel level with the usage of attention mechanism. The resulting approach defines a new state of the art on standard image retrieval datasets: Stanford Online Products and DeepFashion In-shop. We also release the source code at https://github.com/OML-Team/open-metric-learning/tree/main/pipelines/postprocessing/ and an interactive demo of our approach at https://dapladoc-oml-postprocessing-demo-srcappmain-pfh2g0.streamlit.app/
Topological Data Analysis for Speech Processing
Dec 02, 2022



We apply topological data analysis (TDA) to speech classification problems and to the introspection of a pretrained speech model, HuBERT. To this end, we introduce a number of topological and algebraic features derived from Transformer attention maps and embeddings. We show that a simple linear classifier built on top of such features outperforms a fine-tuned classification head. In particular, we achieve an improvement of about $9\%$ accuracy and $5\%$ ERR on four common datasets; on CREMA-D, the proposed feature set reaches a new state of the art performance with accuracy $80.155$. We also show that topological features are able to reveal functional roles of speech Transformer heads; e.g., we find the heads capable to distinguish between pairs of sample sources (natural/synthetic) or voices without any downstream fine-tuning. Our results demonstrate that TDA is a promising new approach for speech analysis, especially for tasks that require structural prediction. Appendices, an introduction to TDA, and other additional materials are available here - https://topohubert.github.io/speech-topology-webpages/
Personality-Driven Social Multimedia Content Recommendation
Jul 25, 2022
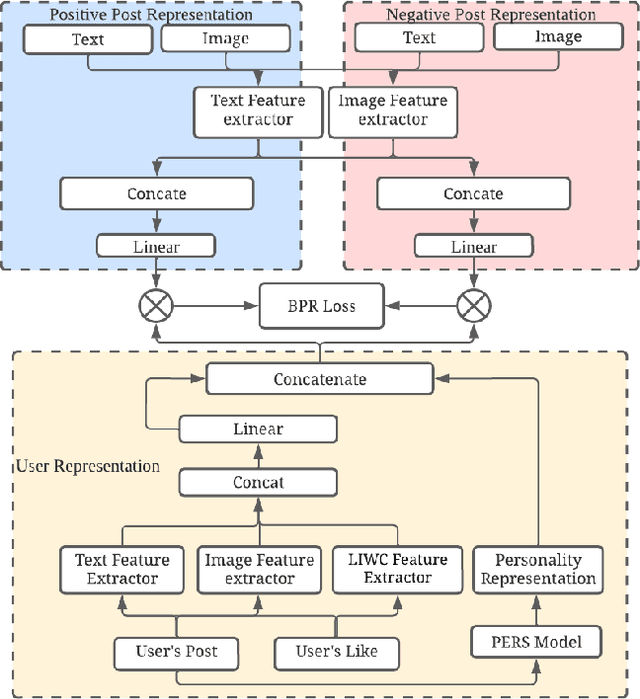
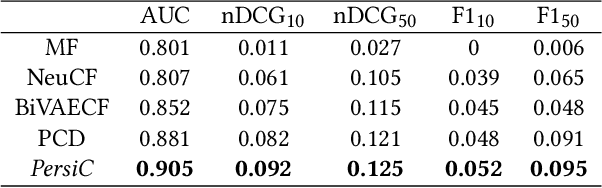
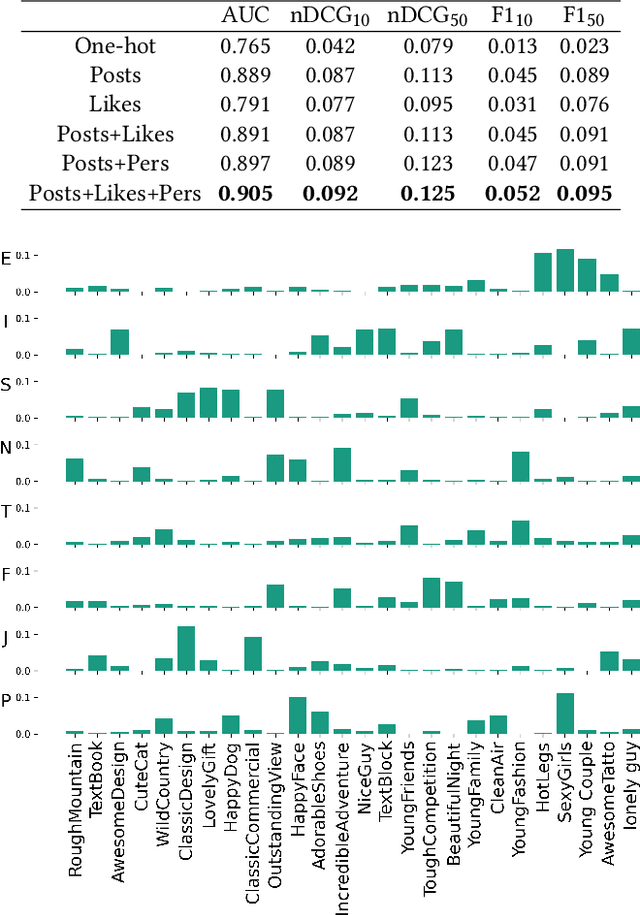
Social media marketing plays a vital role in promoting brand and product values to wide audiences. In order to boost their advertising revenues, global media buying platforms such as Facebook Ads constantly reduce the reach of branded organic posts, pushing brands to spend more on paid media ads. In order to run organic and paid social media marketing efficiently, it is necessary to understand the audience, tailoring the content to fit their interests and online behaviours, which is impossible to do manually at a large scale. At the same time, various personality type categorization schemes such as the Myers-Briggs Personality Type indicator make it possible to reveal the dependencies between personality traits and user content preferences on a wider scale by categorizing audience behaviours in a unified and structured manner. This problem is yet to be studied in depth by the research community, while the level of impact of different personality traits on content recommendation accuracy has not been widely utilised and comprehensively evaluated so far. Specifically, in this work we investigate the impact of human personality traits on the content recommendation model by applying a novel personality-driven multi-view content recommender system called Personality Content Marketing Recommender Engine, or PersiC. Our experimental results and real-world case study demonstrate not just PersiC's ability to perform efficient human personality-driven multi-view content recommendation, but also allow for actionable digital ad strategy recommendations, which when deployed are able to improve digital advertising efficiency by over 420% as compared to the original human-guided approach.
DetIE: Multilingual Open Information Extraction Inspired by Object Detection
Jun 24, 2022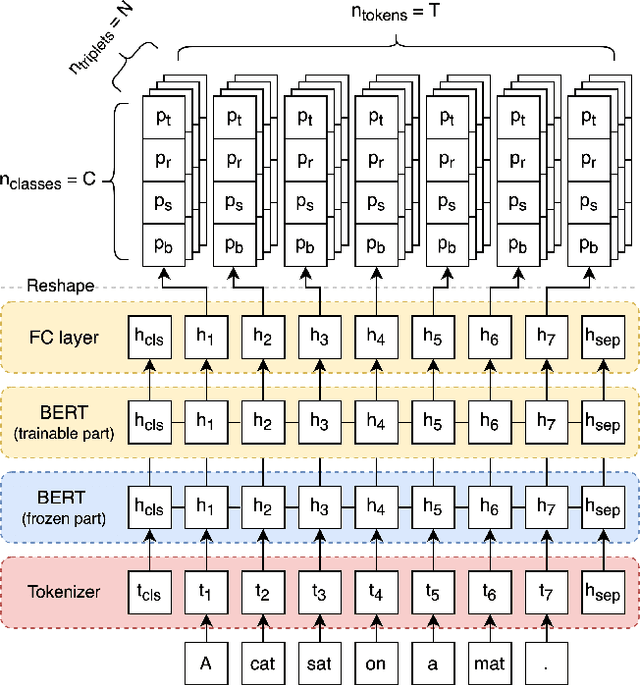
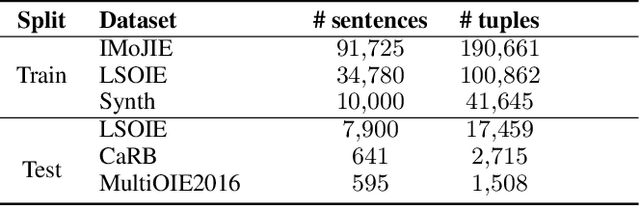
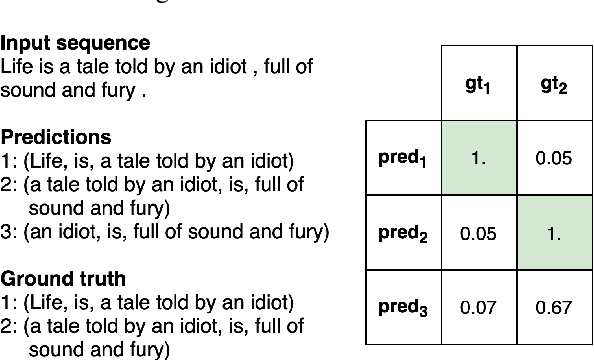

State of the art neural methods for open information extraction (OpenIE) usually extract triplets (or tuples) iteratively in an autoregressive or predicate-based manner in order not to produce duplicates. In this work, we propose a different approach to the problem that can be equally or more successful. Namely, we present a novel single-pass method for OpenIE inspired by object detection algorithms from computer vision. We use an order-agnostic loss based on bipartite matching that forces unique predictions and a Transformer-based encoder-only architecture for sequence labeling. The proposed approach is faster and shows superior or similar performance in comparison with state of the art models on standard benchmarks in terms of both quality metrics and inference time. Our model sets the new state of the art performance of 67.7% F1 on CaRB evaluated as OIE2016 while being 3.35x faster at inference than previous state of the art. We also evaluate the multilingual version of our model in the zero-shot setting for two languages and introduce a strategy for generating synthetic multilingual data to fine-tune the model for each specific language. In this setting, we show performance improvement 15% on multilingual Re-OIE2016, reaching 75% F1 for both Portuguese and Spanish languages. Code and models are available at https://github.com/sberbank-ai/DetIE.
Near-Zero-Shot Suggestion Mining with a Little Help from WordNet
Nov 25, 2021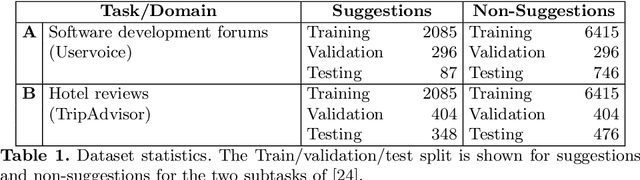
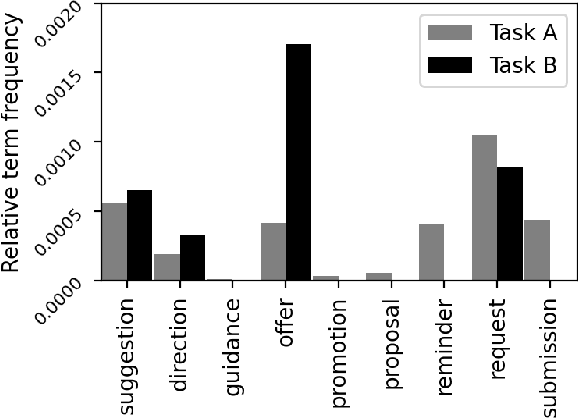

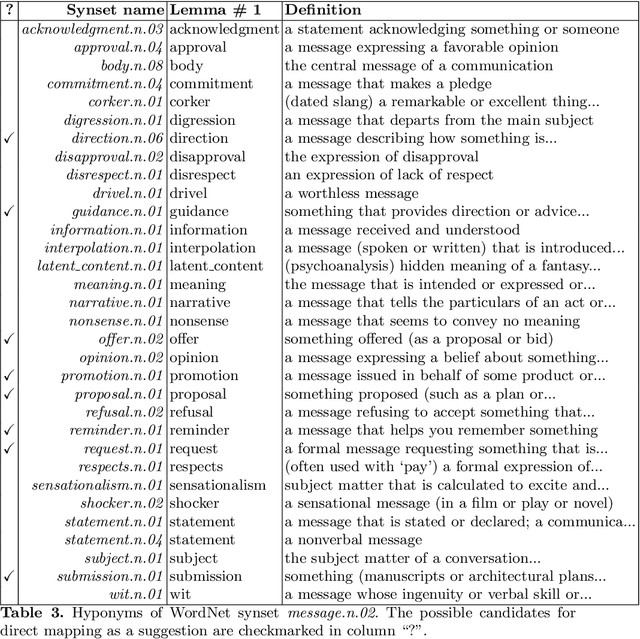
In this work, we explore the constructive side of online reviews: advice, tips, requests, and suggestions that users provide about goods, venues, services, and other items of interest. To reduce training costs and annotation efforts needed to build a classifier for a specific label set, we present and evaluate several entailment-based zero-shot approaches to suggestion classification in a label-fully-unseen fashion. In particular, we introduce the strategy of assigning target class labels to sentences in English language with user intentions, which significantly improves prediction quality. The proposed strategies are evaluated with a comprehensive experimental study that validated our results both quantitatively and qualitatively.