 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlaying the lottery with rewards and multiple languages: lottery tickets in RL and NLP
Jun 06, 2019
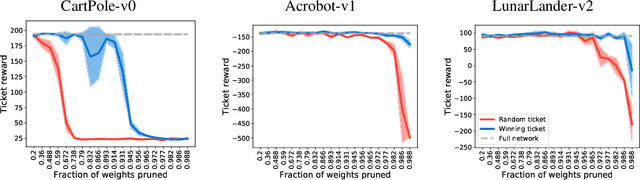
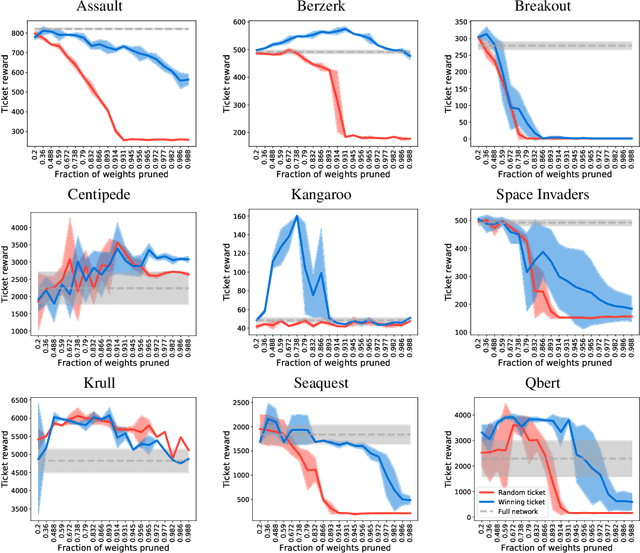
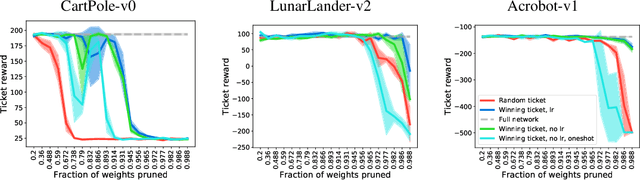
The lottery ticket hypothesis proposes that over-parameterization of deep neural networks (DNNs) aids training by increasing the probability of a "lucky" sub-network initialization being present rather than by helping the optimization process. This phenomenon is intriguing and suggests that initialization strategies for DNNs can be improved substantially, but the lottery ticket hypothesis has only previously been tested in the context of supervised learning for natural image tasks. Here, we evaluate whether "winning ticket" initializations exist in two different domains: reinforcement learning (RL) and in natural language processing (NLP). For RL, we analyzed a number of discrete-action space tasks, including both classic control and pixel control. For NLP, we examined both recurrent LSTM models and large-scale Transformer models. Consistent with work in supervised image classification, we confirm that winning ticket initializations generally outperform parameter-matched random initializations, even at extreme pruning rates. Together, these results suggest that the lottery ticket hypothesis is not restricted to supervised learning of natural images, but rather represents a broader phenomenon in DNNs.
fairseq: A Fast, Extensible Toolkit for Sequence Modeling
Apr 01, 2019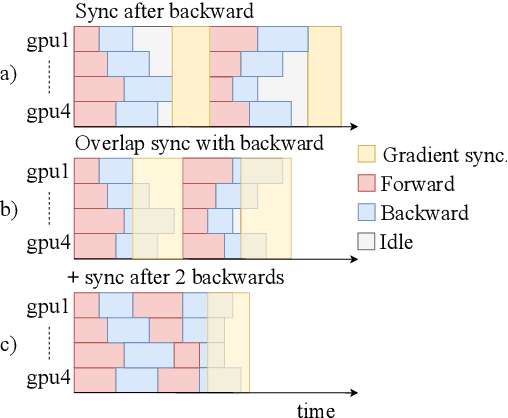

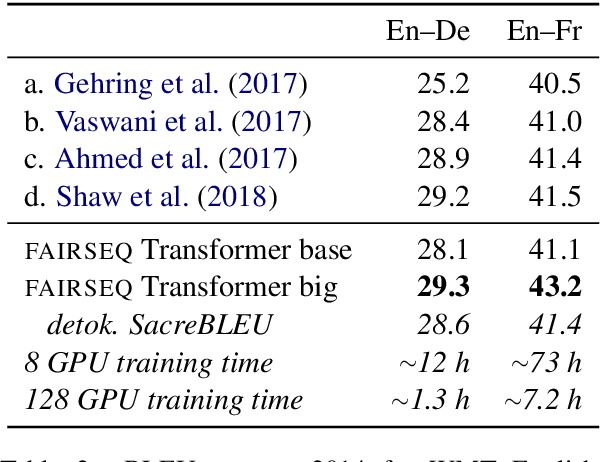
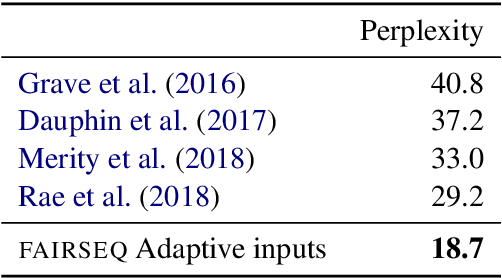
fairseq is an open-source sequence modeling toolkit that allows researchers and developers to train custom models for translation, summarization, language modeling, and other text generation tasks. The toolkit is based on PyTorch and supports distributed training across multiple GPUs and machines. We also support fast mixed-precision training and inference on modern GPUs. A demo video can be found at https://www.youtube.com/watch?v=OtgDdWtHvto
Pre-trained Language Model Representations for Language Generation
Apr 01, 2019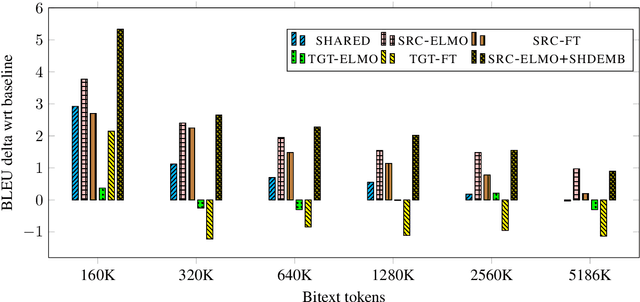
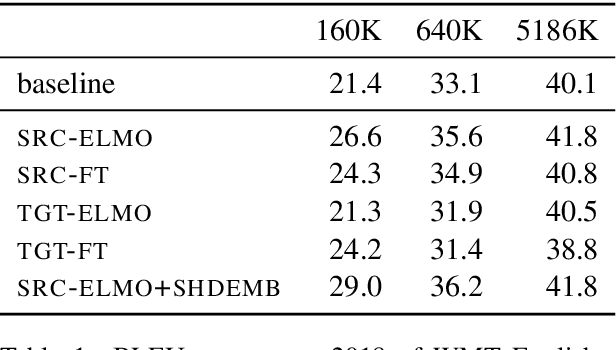

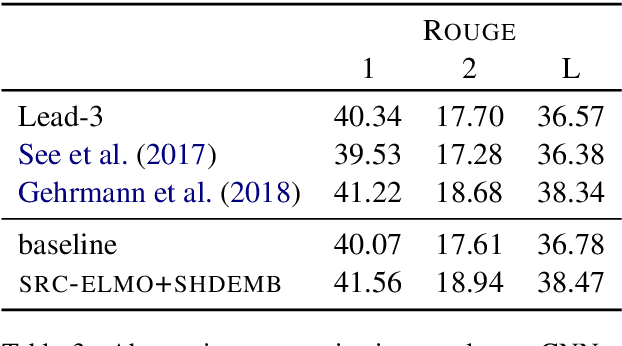
Pre-trained language model representations have been successful in a wide range of language understanding tasks. In this paper, we examine different strategies to integrate pre-trained representations into sequence to sequence models and apply it to neural machine translation and abstractive summarization. We find that pre-trained representations are most effective when added to the encoder network which slows inference by only 14%. Our experiments in machine translation show gains of up to 5.3 BLEU in a simulated resource-poor setup. While returns diminish with more labeled data, we still observe improvements when millions of sentence-pairs are available. Finally, on abstractive summarization we achieve a new state of the art on the full text version of CNN/DailyMail.
Cloze-driven Pretraining of Self-attention Networks
Mar 19, 2019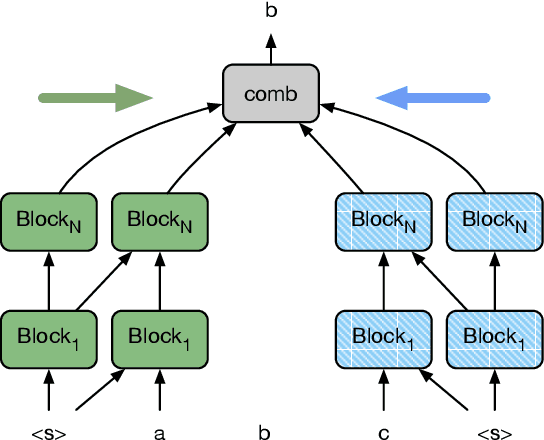
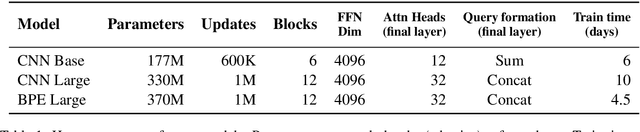
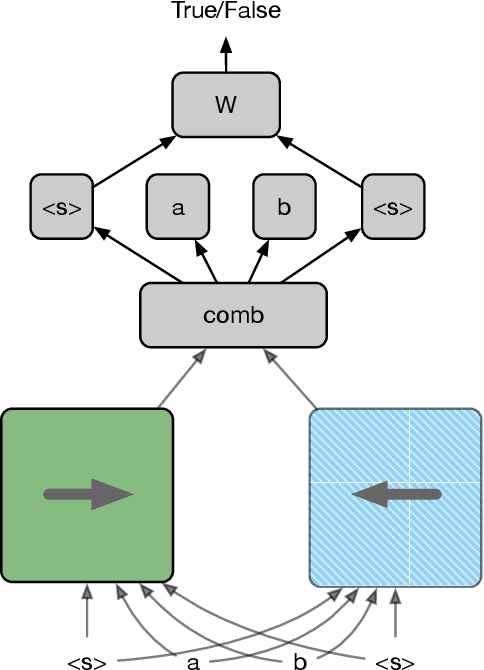
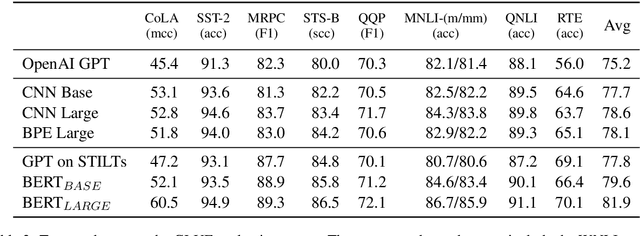
We present a new approach for pretraining a bi-directional transformer model that provides significant performance gains across a variety of language understanding problems. Our model solves a cloze-style word reconstruction task, where each word is ablated and must be predicted given the rest of the text. Experiments demonstrate large performance gains on GLUE and new state of the art results on NER as well as constituency parsing benchmarks, consistent with the concurrently introduced BERT model. We also present a detailed analysis of a number of factors that contribute to effective pretraining, including data domain and size, model capacity, and variations on the cloze objective.
Classical Structured Prediction Losses for Sequence to Sequence Learning
Oct 05, 2018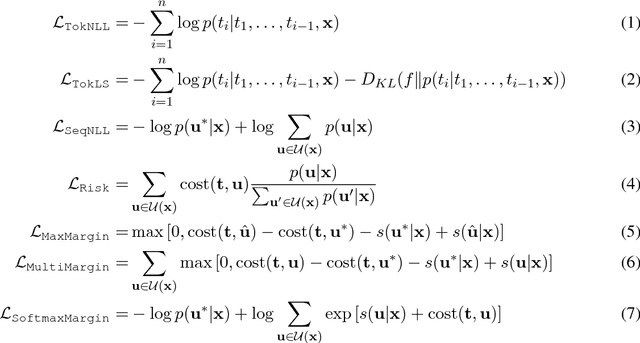
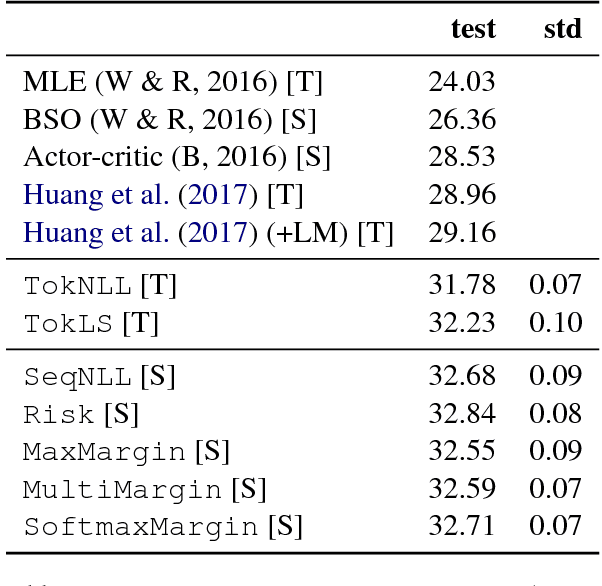
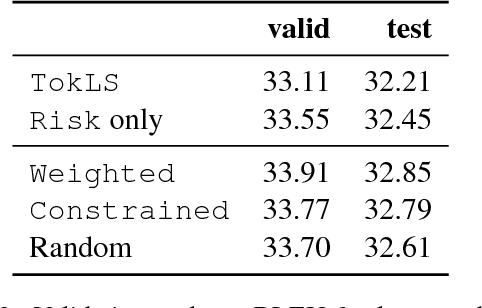
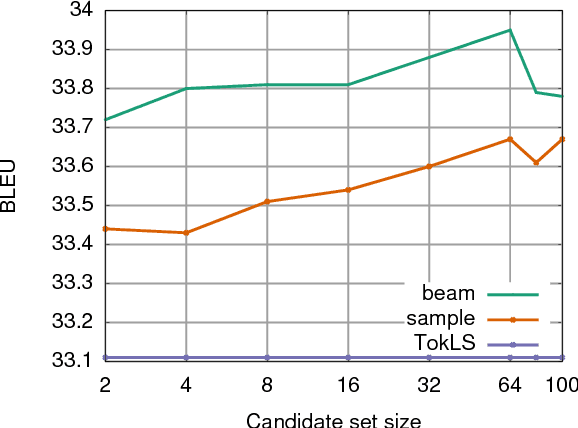
There has been much recent work on training neural attention models at the sequence-level using either reinforcement learning-style methods or by optimizing the beam. In this paper, we survey a range of classical objective functions that have been widely used to train linear models for structured prediction and apply them to neural sequence to sequence models. Our experiments show that these losses can perform surprisingly well by slightly outperforming beam search optimization in a like for like setup. We also report new state of the art results on both IWSLT'14 German-English translation as well as Gigaword abstractive summarization. On the larger WMT'14 English-French translation task, sequence-level training achieves 41.5 BLEU which is on par with the state of the art.
Understanding Back-Translation at Scale
Oct 03, 2018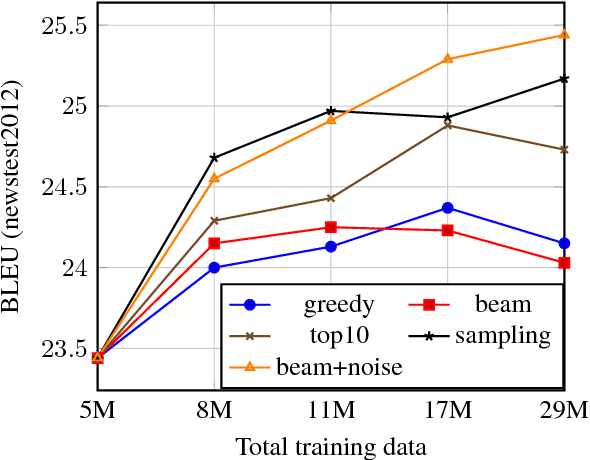
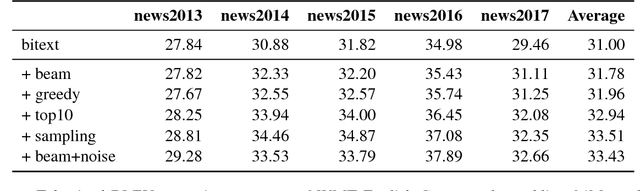
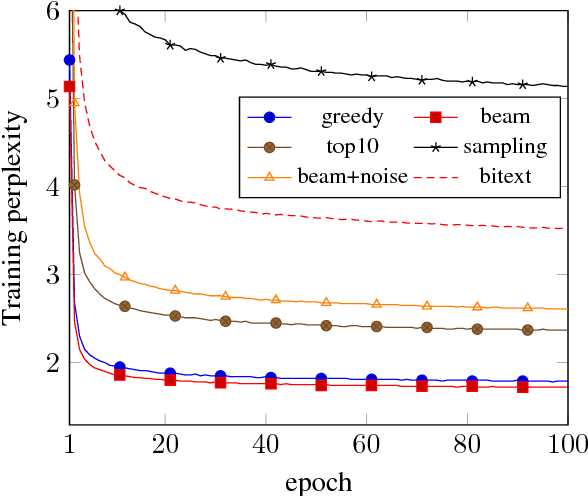
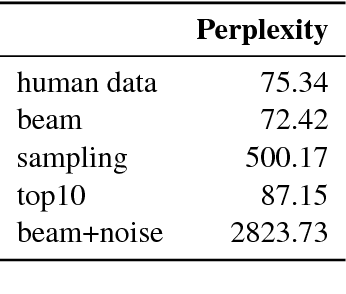
An effective method to improve neural machine translation with monolingual data is to augment the parallel training corpus with back-translations of target language sentences. This work broadens the understanding of back-translation and investigates a number of methods to generate synthetic source sentences. We find that in all but resource poor settings back-translations obtained via sampling or noised beam outputs are most effective. Our analysis shows that sampling or noisy synthetic data gives a much stronger training signal than data generated by beam or greedy search. We also compare how synthetic data compares to genuine bitext and study various domain effects. Finally, we scale to hundreds of millions of monolingual sentences and achieve a new state of the art of 35 BLEU on the WMT'14 English-German test set.
Scaling Neural Machine Translation
Sep 04, 2018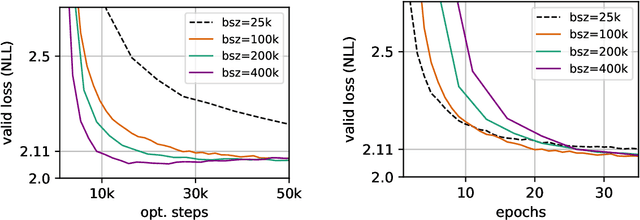
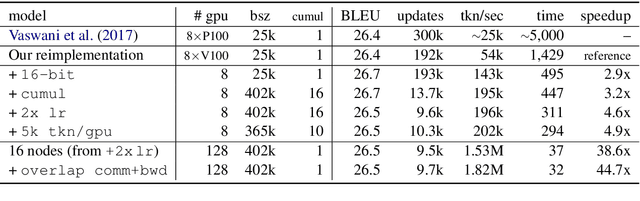
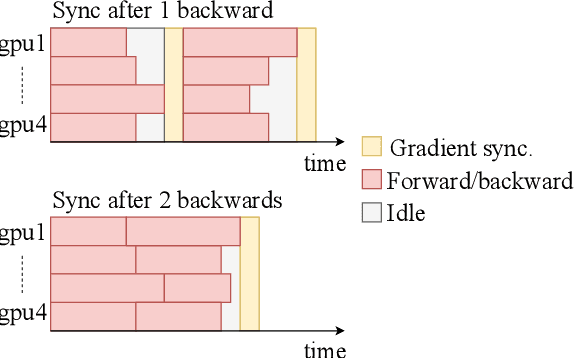
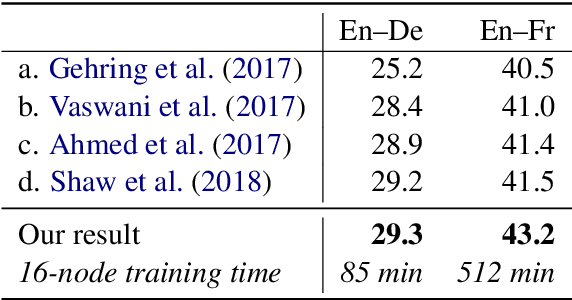
Sequence to sequence learning models still require several days to reach state of the art performance on large benchmark datasets using a single machine. This paper shows that reduced precision and large batch training can speedup training by nearly 5x on a single 8-GPU machine with careful tuning and implementation. On WMT'14 English-German translation, we match the accuracy of Vaswani et al. (2017) in under 5 hours when training on 8 GPUs and we obtain a new state of the art of 29.3 BLEU after training for 85 minutes on 128 GPUs. We further improve these results to 29.8 BLEU by training on the much larger Paracrawl dataset. On the WMT'14 English-French task, we obtain a state-of-the-art BLEU of 43.2 in 8.5 hours on 128 GPUs.