 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSQL-PaLM: Improved Large Language Model Adaptation for Text-to-SQL
Jun 07, 2023



One impressive emergent capability of large language models (LLMs) is generation of code, including Structured Query Language (SQL) for databases. For the task of converting natural language text to SQL queries, Text-to-SQL, adaptation of LLMs is of paramount importance, both in in-context learning and fine-tuning settings, depending on the amount of adaptation data used. In this paper, we propose an LLM-based Text-to-SQL model SQL-PaLM, leveraging on PaLM-2, that pushes the state-of-the-art in both settings. Few-shot SQL-PaLM is based on an execution-based self-consistency prompting approach designed for Text-to-SQL, and achieves 77.3% in test-suite accuracy on Spider, which to our best knowledge is the first to outperform previous state-of-the-art with fine-tuning by a significant margin, 4%. Furthermore, we demonstrate that the fine-tuned SQL-PALM outperforms it further by another 1%. Towards applying SQL-PaLM to real-world scenarios we further evaluate its robustness on other challenging variants of Spider and demonstrate the superior generalization capability of SQL-PaLM. In addition, via extensive case studies, we demonstrate the impressive intelligent capabilities and various success enablers of LLM-based Text-to-SQL.
LANISTR: Multimodal Learning from Structured and Unstructured Data
May 26, 2023



Multimodal large-scale pretraining has shown impressive performance gains for unstructured data including language, image, audio, and video. Yet, the scenario most prominent in real-world applications is the existence of combination of structured (including tabular and time-series) and unstructured data, and this has so far been understudied. Towards this end, we propose LANISTR, a novel attention-based framework to learn from LANguage, Image, and STRuctured data. We introduce a new multimodal fusion module with a similarity-based multimodal masking loss that enables LANISTR to learn cross-modal relations from large-scale multimodal data with missing modalities during training and test time. On two publicly available challenging datasets, MIMIC-IV and Amazon Product Review, LANISTR achieves absolute improvements of 6.47% (AUROC) and up to 17.69% (accuracy), respectively, compared to the state-of-the-art multimodal models while showing superior generalization capabilities.
Universal Self-adaptive Prompting
May 24, 2023



A hallmark of modern large language models (LLMs) is their impressive general zero-shot and few-shot abilities, often elicited through prompt-based and/or in-context learning. However, while highly coveted and being the most general, zero-shot performances in LLMs are still typically weaker due to the lack of guidance and the difficulty of applying existing automatic prompt design methods in general tasks when ground-truth labels are unavailable. In this study, we address this by presenting Universal Self-adaptive Prompting (USP), an automatic prompt design approach specifically tailored for zero-shot learning (while compatible with few-shot). Requiring only a small amount of unlabeled data & an inference-only LLM, USP is highly versatile: to achieve universal prompting, USP categorizes a possible NLP task into one of the three possible task types, and then uses a corresponding selector to select the most suitable queries & zero-shot model-generated responses as pseudo-demonstrations, thereby generalizing ICL to the zero-shot setup in a fully automated way. We evaluate zero-shot USP with two PaLM models, and demonstrate performances that are considerably stronger than standard zero-shot baselines and are comparable to or even superior than few-shot baselines across more than 20 natural language understanding (NLU) and natural language generation (NLG) tasks.
Better Zero-Shot Reasoning with Self-Adaptive Prompting
May 23, 2023



Modern large language models (LLMs) have demonstrated impressive capabilities at sophisticated tasks, often through step-by-step reasoning similar to humans. This is made possible by their strong few and zero-shot abilities -- they can effectively learn from a handful of handcrafted, completed responses ("in-context examples"), or are prompted to reason spontaneously through specially designed triggers. Nonetheless, some limitations have been observed. First, performance in the few-shot setting is sensitive to the choice of examples, whose design requires significant human effort. Moreover, given the diverse downstream tasks of LLMs, it may be difficult or laborious to handcraft per-task labels. Second, while the zero-shot setting does not require handcrafting, its performance is limited due to the lack of guidance to the LLMs. To address these limitations, we propose Consistency-based Self-adaptive Prompting (COSP), a novel prompt design method for LLMs. Requiring neither handcrafted responses nor ground-truth labels, COSP selects and builds the set of examples from the LLM zero-shot outputs via carefully designed criteria that combine consistency, diversity and repetition. In the zero-shot setting for three different LLMs, we show that using only LLM predictions, COSP improves performance up to 15% compared to zero-shot baselines and matches or exceeds few-shot baselines for a range of reasoning tasks.
SLM: End-to-end Feature Selection via Sparse Learnable Masks
Apr 06, 2023



Feature selection has been widely used to alleviate compute requirements during training, elucidate model interpretability, and improve model generalizability. We propose SLM -- Sparse Learnable Masks -- a canonical approach for end-to-end feature selection that scales well with respect to both the feature dimension and the number of samples. At the heart of SLM lies a simple but effective learnable sparse mask, which learns which features to select, and gives rise to a novel objective that provably maximizes the mutual information (MI) between the selected features and the labels, which can be derived from a quadratic relaxation of mutual information from first principles. In addition, we derive a scaling mechanism that allows SLM to precisely control the number of features selected, through a novel use of sparsemax. This allows for more effective learning as demonstrated in ablation studies. Empirically, SLM achieves state-of-the-art results against a variety of competitive baselines on eight benchmark datasets, often by a significant margin, especially on those with real-world challenges such as class imbalance.
TSMixer: An all-MLP Architecture for Time Series Forecasting
Mar 10, 2023



Real-world time-series datasets are often multivariate with complex dynamics. Commonly-used high capacity architectures like recurrent- or attention-based sequential models have become popular. However, recent work demonstrates that simple univariate linear models can outperform those deep alternatives. In this paper, we investigate the capabilities of linear models for time-series forecasting and present Time-Series Mixer (TSMixer), an architecture designed by stacking multi-layer perceptrons (MLPs). TSMixer is based on mixing operations along time and feature dimensions to extract information efficiently. On popular academic benchmarks, the simple-to-implement TSMixer is comparable to specialized state-of-the-art models that leverage the inductive biases of specific benchmarks. On the challenging and large scale M5 benchmark, a real-world retail dataset, TSMixer demonstrates superior performance compared to the state-of-the-art alternatives. Our results underline the importance of efficiently utilizing cross-variate and auxiliary information for improving the performance of time series forecasting. The design paradigms utilized in TSMixer are expected to open new horizons for deep learning-based time series forecasting.
Neural Spline Search for Quantile Probabilistic Modeling
Jan 12, 2023Accurate estimation of output quantiles is crucial in many use cases, where it is desired to model the range of possibility. Modeling target distribution at arbitrary quantile levels and at arbitrary input attribute levels are important to offer a comprehensive picture of the data, and requires the quantile function to be expressive enough. The quantile function describing the target distribution using quantile levels is critical for quantile regression. Although various parametric forms for the distributions (that the quantile function specifies) can be adopted, an everlasting problem is selecting the most appropriate one that can properly approximate the data distributions. In this paper, we propose a non-parametric and data-driven approach, Neural Spline Search (NSS), to represent the observed data distribution without parametric assumptions. NSS is flexible and expressive for modeling data distributions by transforming the inputs with a series of monotonic spline regressions guided by symbolic operators. We demonstrate that NSS outperforms previous methods on synthetic, real-world regression and time-series forecasting tasks.
SPADE: Semi-supervised Anomaly Detection under Distribution Mismatch
Nov 30, 2022



Semi-supervised anomaly detection is a common problem, as often the datasets containing anomalies are partially labeled. We propose a canonical framework: Semi-supervised Pseudo-labeler Anomaly Detection with Ensembling (SPADE) that isn't limited by the assumption that labeled and unlabeled data come from the same distribution. Indeed, the assumption is often violated in many applications - for example, the labeled data may contain only anomalies unlike unlabeled data, or unlabeled data may contain different types of anomalies, or labeled data may contain only 'easy-to-label' samples. SPADE utilizes an ensemble of one class classifiers as the pseudo-labeler to improve the robustness of pseudo-labeling with distribution mismatch. Partial matching is proposed to automatically select the critical hyper-parameters for pseudo-labeling without validation data, which is crucial with limited labeled data. SPADE shows state-of-the-art semi-supervised anomaly detection performance across a wide range of scenarios with distribution mismatch in both tabular and image domains. In some common real-world settings such as model facing new types of unlabeled anomalies, SPADE outperforms the state-of-the-art alternatives by 5% AUC in average.
Provable Membership Inference Privacy
Nov 12, 2022

In applications involving sensitive data, such as finance and healthcare, the necessity for preserving data privacy can be a significant barrier to machine learning model development. Differential privacy (DP) has emerged as one canonical standard for provable privacy. However, DP's strong theoretical guarantees often come at the cost of a large drop in its utility for machine learning, and DP guarantees themselves can be difficult to interpret. In this work, we propose a novel privacy notion, membership inference privacy (MIP), to address these challenges. We give a precise characterization of the relationship between MIP and DP, and show that MIP can be achieved using less amount of randomness compared to the amount required for guaranteeing DP, leading to a smaller drop in utility. MIP guarantees are also easily interpretable in terms of the success rate of membership inference attacks. Our theoretical results also give rise to a simple algorithm for guaranteeing MIP which can be used as a wrapper around any algorithm with a continuous output, including parametric model training.
Test-Time Adaptation for Visual Document Understanding
Jun 15, 2022
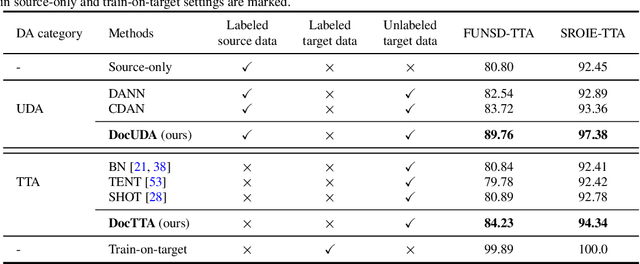
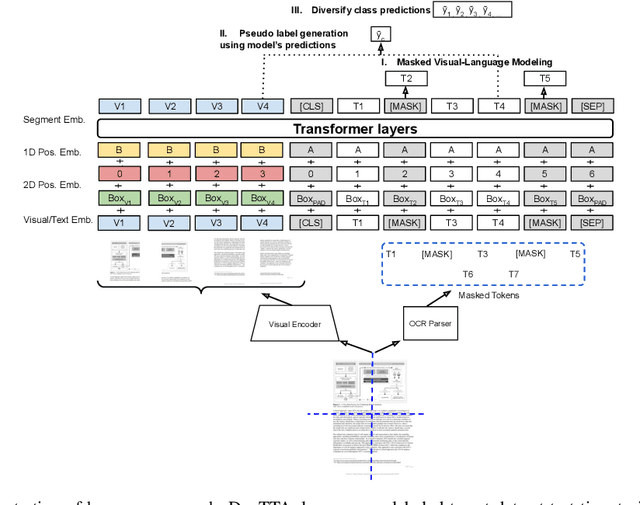
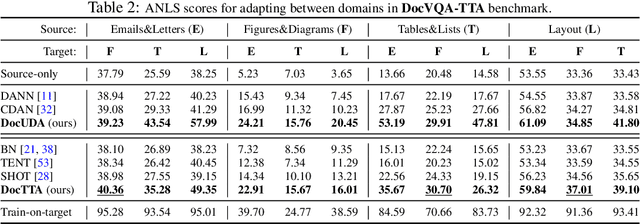
Self-supervised pretraining has been able to produce transferable representations for various visual document understanding (VDU) tasks. However, the ability of such representations to adapt to new distribution shifts at test-time has not been studied yet. We propose DocTTA, a novel test-time adaptation approach for documents that leverages cross-modality self-supervised learning via masked visual language modeling as well as pseudo labeling to adapt models learned on a \textit{source} domain to an unlabeled \textit{target} domain at test time. We also introduce new benchmarks using existing public datasets for various VDU tasks including entity recognition, key-value extraction, and document visual question answering tasks where DocTTA improves the source model performance up to 1.79\% in (F1 score), 3.43\% (F1 score), and 17.68\% (ANLS score), respectively while drastically reducing calibration error on target data.