 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTest-Time Adaptation for Visual Document Understanding
Paper and Code

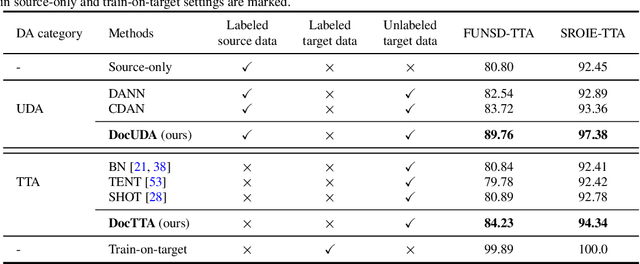
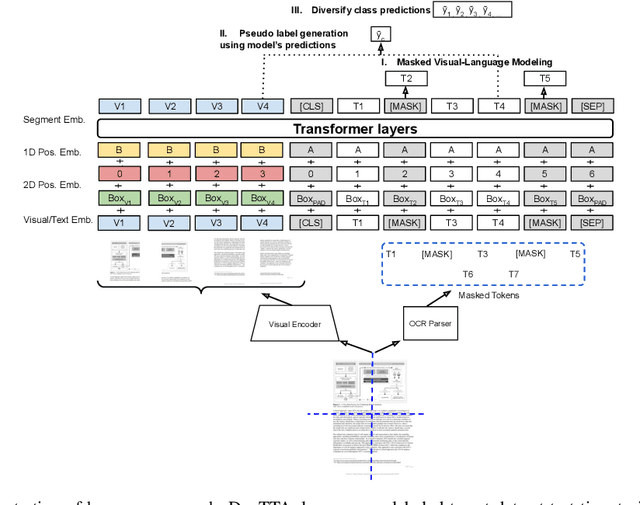
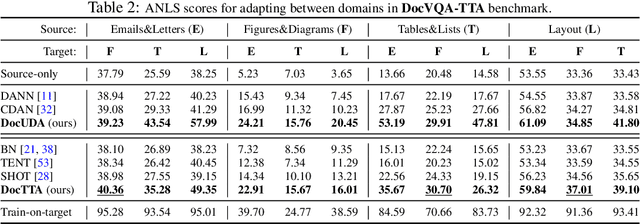
Self-supervised pretraining has been able to produce transferable representations for various visual document understanding (VDU) tasks. However, the ability of such representations to adapt to new distribution shifts at test-time has not been studied yet. We propose DocTTA, a novel test-time adaptation approach for documents that leverages cross-modality self-supervised learning via masked visual language modeling as well as pseudo labeling to adapt models learned on a \textit{source} domain to an unlabeled \textit{target} domain at test time. We also introduce new benchmarks using existing public datasets for various VDU tasks including entity recognition, key-value extraction, and document visual question answering tasks where DocTTA improves the source model performance up to 1.79\% in (F1 score), 3.43\% (F1 score), and 17.68\% (ANLS score), respectively while drastically reducing calibration error on target data.