 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Gender Debiasing Affects Internal Model Representations, and Why It Matters
Apr 14, 2022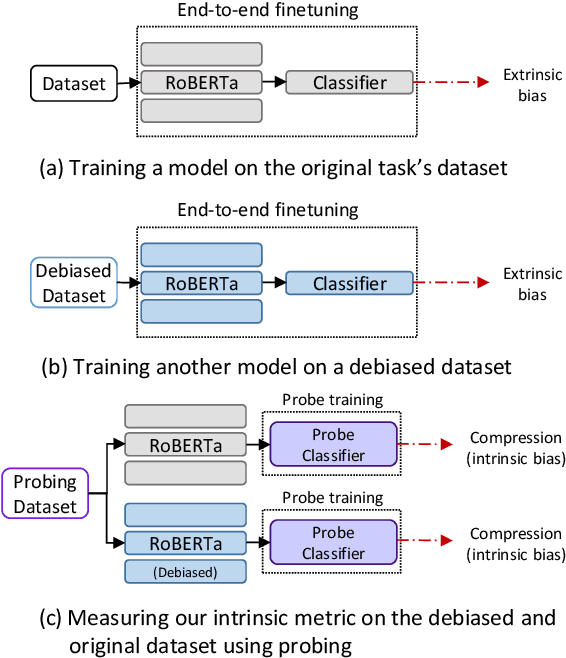
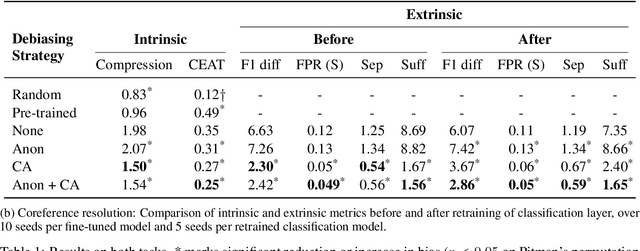
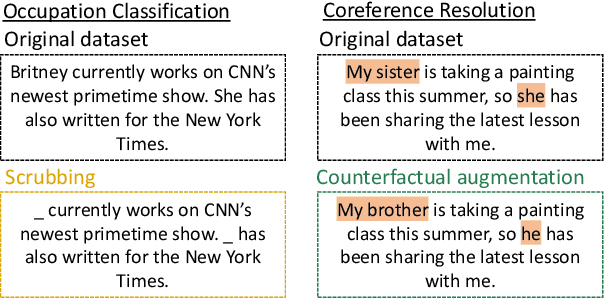
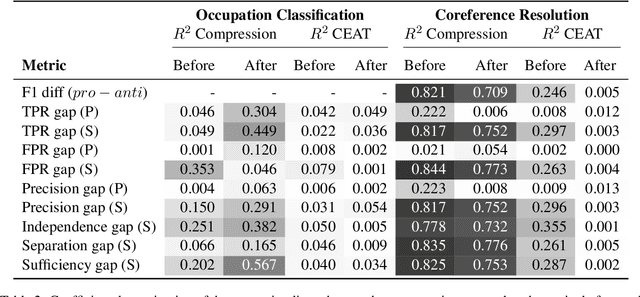
Common studies of gender bias in NLP focus either on extrinsic bias measured by model performance on a downstream task or on intrinsic bias found in models' internal representations. However, the relationship between extrinsic and intrinsic bias is relatively unknown. In this work, we illuminate this relationship by measuring both quantities together: we debias a model during downstream fine-tuning, which reduces extrinsic bias, and measure the effect on intrinsic bias, which is operationalized as bias extractability with information-theoretic probing. Through experiments on two tasks and multiple bias metrics, we show that our intrinsic bias metric is a better indicator of debiasing than (a contextual adaptation of) the standard WEAT metric, and can also expose cases of superficial debiasing. Our framework provides a comprehensive perspective on bias in NLP models, which can be applied to deploy NLP systems in a more informed manner. Our code will be made publicly available.
Intrinsic Bias Metrics Do Not Correlate with Application Bias
Jan 02, 2021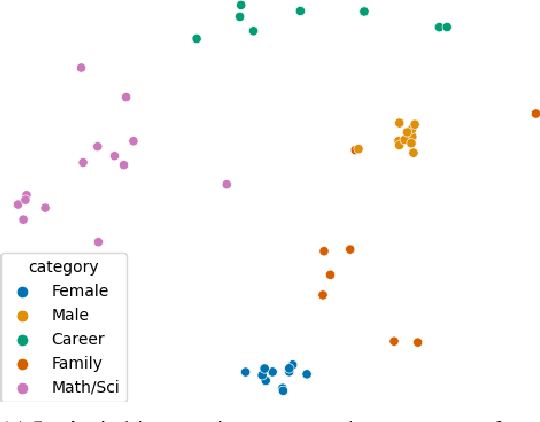

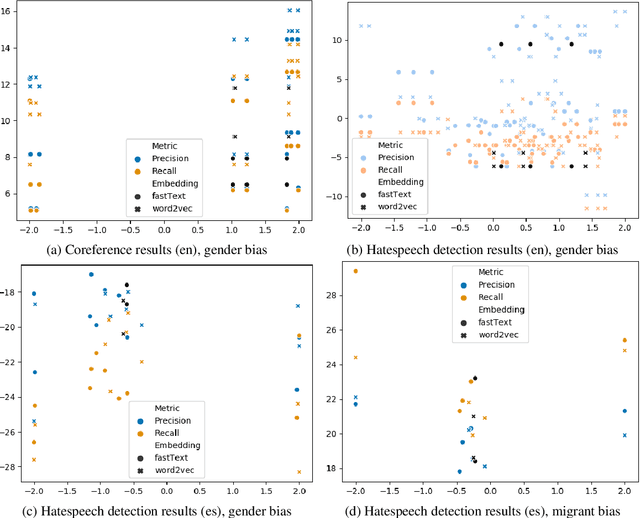
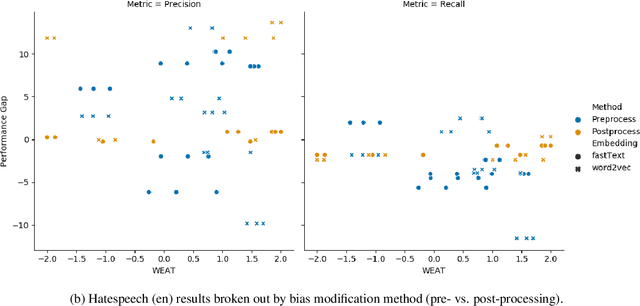
Natural Language Processing (NLP) systems learn harmful societal biases that cause them to widely proliferate inequality as they are deployed in more and more situations. To address and combat this, the NLP community relies on a variety of metrics to identify and quantify bias in black-box models and to guide efforts at debiasing. Some of these metrics are intrinsic, and are measured in word embedding spaces, and some are extrinsic, which measure the bias present downstream in the tasks that the word embeddings are plugged into. This research examines whether easy-to-measure intrinsic metrics correlate well to real world extrinsic metrics. We measure both intrinsic and extrinsic bias across hundreds of trained models covering different tasks and experimental conditions and find that there is no reliable correlation between these metrics that holds in all scenarios across tasks and languages. We advise that efforts to debias embedding spaces be always also paired with measurement of downstream model bias, and suggest that that community increase effort into making downstream measurement more feasible via creation of additional challenge sets and annotated test data. We additionally release code, a new intrinsic metric, and an annotated test set for gender bias for hatespeech.
Content Planning for Neural Story Generation with Aristotelian Rescoring
Oct 09, 2020
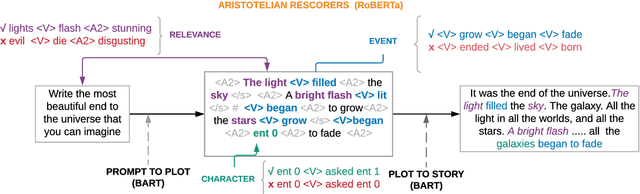
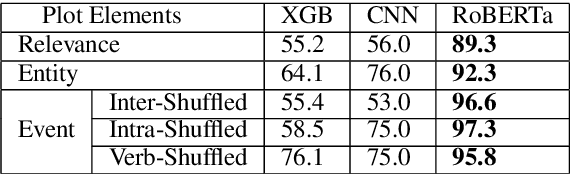
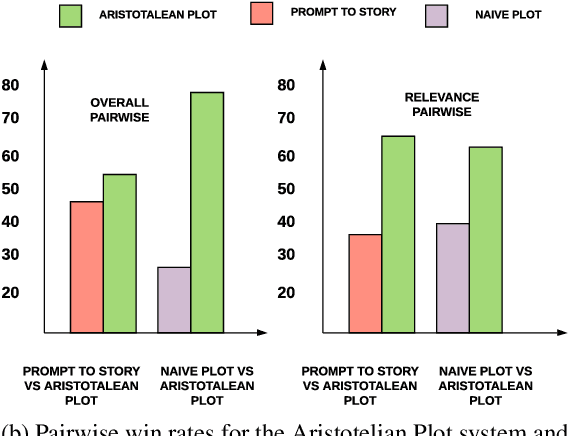
Long-form narrative text generated from large language models manages a fluent impersonation of human writing, but only at the local sentence level, and lacks structure or global cohesion. We posit that many of the problems of story generation can be addressed via high-quality content planning, and present a system that focuses on how to learn good plot structures to guide story generation. We utilize a plot-generation language model along with an ensemble of rescoring models that each implement an aspect of good story-writing as detailed in Aristotle's Poetics. We find that stories written with our more principled plot-structure are both more relevant to a given prompt and higher quality than baselines that do not content plan, or that plan in an unprincipled way.
Scaling Systematic Literature Reviews with Machine Learning Pipelines
Oct 09, 2020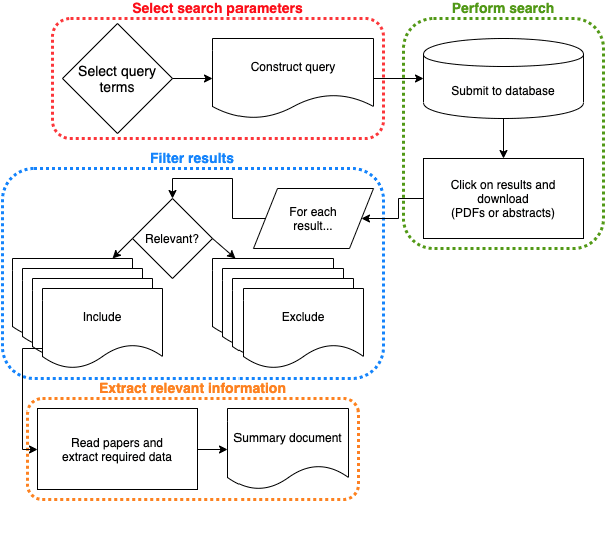
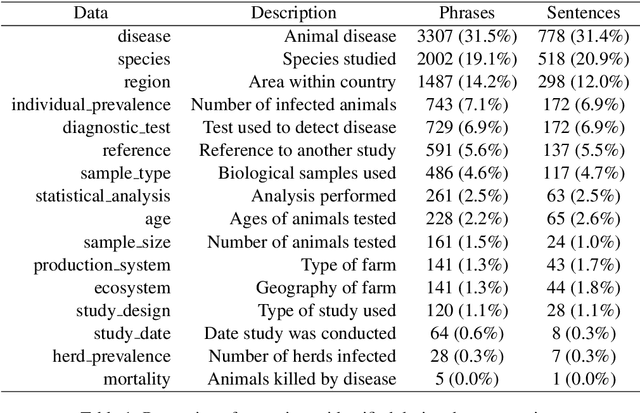
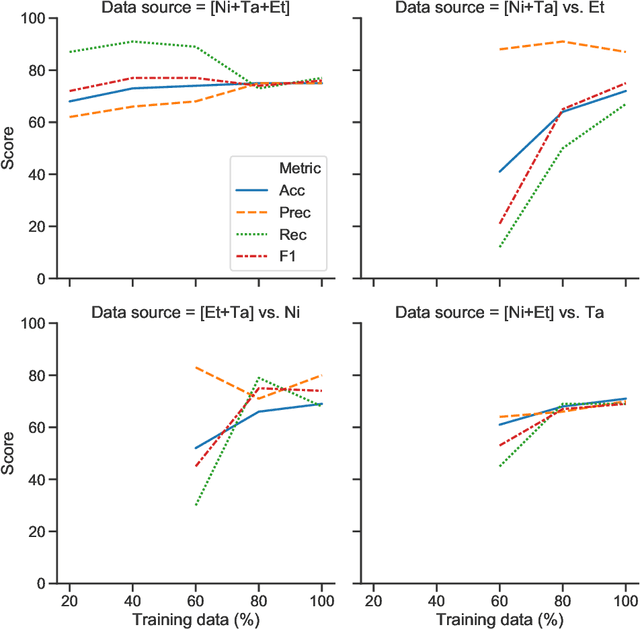
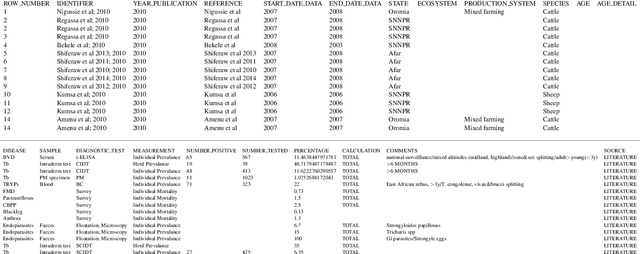
Systematic reviews, which entail the extraction of data from large numbers of scientific documents, are an ideal avenue for the application of machine learning. They are vital to many fields of science and philanthropy, but are very time-consuming and require experts. Yet the three main stages of a systematic review are easily done automatically: searching for documents can be done via APIs and scrapers, selection of relevant documents can be done via binary classification, and extraction of data can be done via sequence-labelling classification. Despite the promise of automation for this field, little research exists that examines the various ways to automate each of these tasks. We construct a pipeline that automates each of these aspects, and experiment with many human-time vs. system quality trade-offs. We test the ability of classifiers to work well on small amounts of data and to generalise to data from countries not represented in the training data. We test different types of data extraction with varying difficulty in annotation, and five different neural architectures to do the extraction. We find that we can get surprising accuracy and generalisability of the whole pipeline system with only 2 weeks of human-expert annotation, which is only 15% of the time it takes to do the whole review manually and can be repeated and extended to new data with no additional effort.
Plan, Write, and Revise: an Interactive System for Open-Domain Story Generation
Apr 18, 2019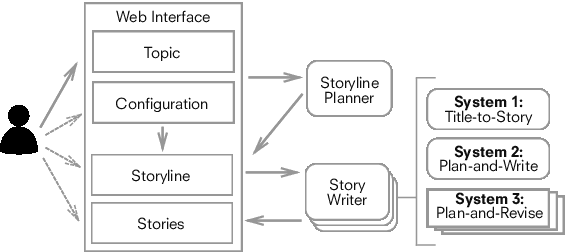
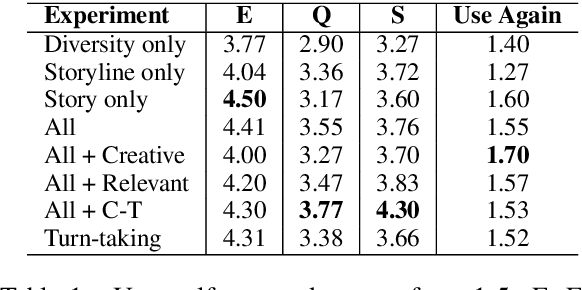
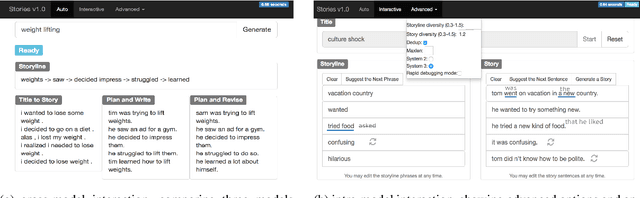
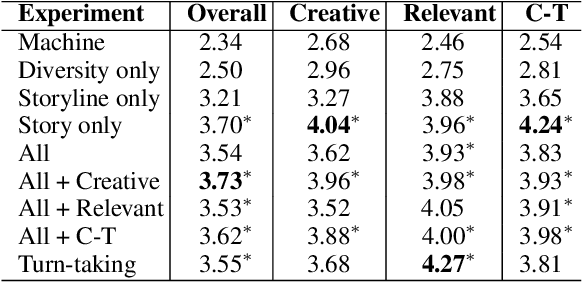
Story composition is a challenging problem for machines and even for humans. We present a neural narrative generation system that interacts with humans to generate stories. Our system has different levels of human interaction, which enables us to understand at what stage of story-writing human collaboration is most productive, both to improving story quality and human engagement in the writing process. We compare different varieties of interaction in story-writing, story-planning, and diversity controls under time constraints, and show that increased types of human collaboration at both planning and writing stages results in a 10-50% improvement in story quality as compared to less interactive baselines. We also show an accompanying increase in user engagement and satisfaction with stories as compared to our own less interactive systems and to previous turn-taking approaches to interaction. Finally, we find that humans tasked with collaboratively improving a particular characteristic of a story are in fact able to do so, which has implications for future uses of human-in-the-loop systems.