 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReplication-Robust Payoff-Allocation with Applications in Machine Learning Marketplaces
Jun 25, 2020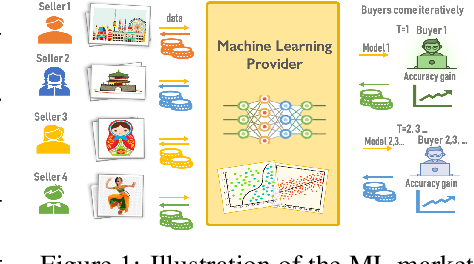
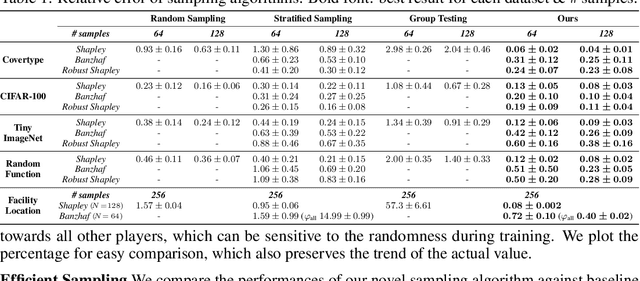
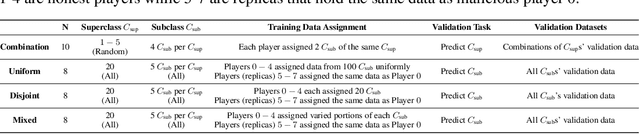
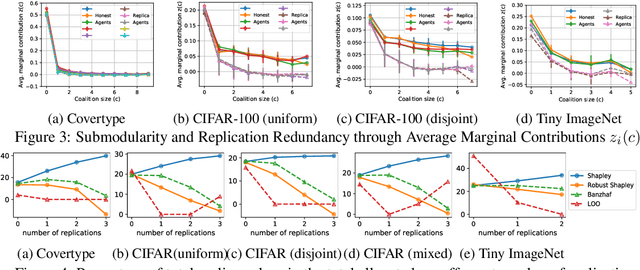
The ever-increasing take-up of machine learning techniques requires ever-more application-specific training data. Manually collecting such training data is a tedious and time-consuming process. Data marketplaces represent a compelling alternative, providing an easy way for acquiring data from potential data providers. A key component of such marketplaces is the compensation mechanism for data providers. Classic payoff-allocation methods such as the Shapley value can be vulnerable to data-replication attacks, and are infeasible to compute in the absence of efficient approximation algorithms. To address these challenges, we present an extensive theoretical study on the vulnerabilities of game theoretic payoff-allocation schemes to replication attacks. Our insights apply to a wide range of payoff-allocation schemes, and enable the design of customised replication-robust payoff-allocations. Furthermore, we present a novel efficient sampling algorithm for approximating payoff-allocation schemes based on marginal contributions. In our experiments, we validate the replication-robustness of classic payoff-allocation schemes and new payoff-allocation schemes derived from our theoretical insights. We also demonstrate the efficiency of our proposed sampling algorithm on a wide range of machine learning tasks.
VAEM: a Deep Generative Model for Heterogeneous Mixed Type Data
Jun 21, 2020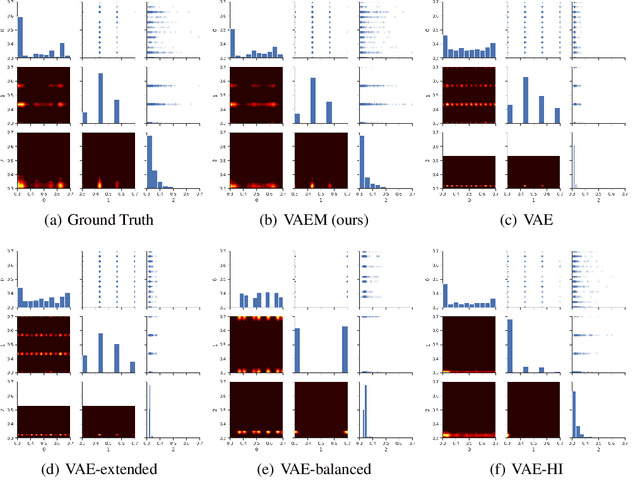

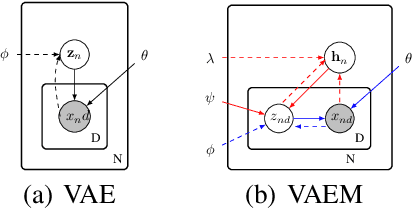
Deep generative models often perform poorly in real-world applications due to the heterogeneity of natural data sets. Heterogeneity arises from data containing different types of features (categorical, ordinal, continuous, etc.) and features of the same type having different marginal distributions. We propose an extension of variational autoencoders (VAEs) called VAEM to handle such heterogeneous data. VAEM is a deep generative model that is trained in a two stage manner such that the first stage provides a more uniform representation of the data to the second stage, thereby sidestepping the problems caused by heterogeneous data. We provide extensions of VAEM to handle partially observed data, and demonstrate its performance in data generation, missing data prediction and sequential feature selection tasks. Our results show that VAEM broadens the range of real-world applications where deep generative models can be successfully deployed.
Large-Scale Educational Question Analysis with Partial Variational Auto-encoders
Mar 12, 2020
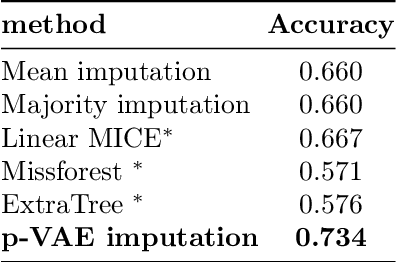
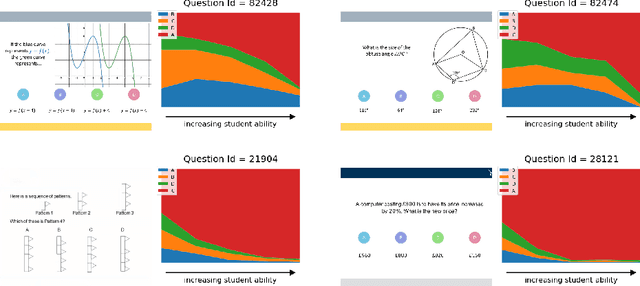
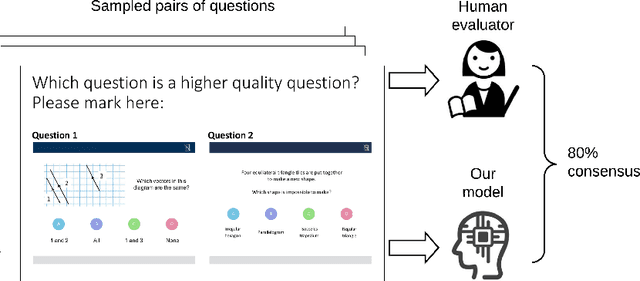
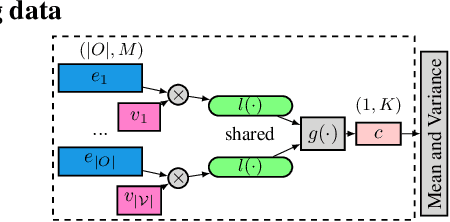
Online education platforms enable teachers to share a large number of educational resources such as questions to form exercises and quizzes for students. With large volumes of such crowd-sourced questions, quantifying the properties of these questions in crowd-sourced online education platforms is of great importance to enable both teachers and students to find high-quality and suitable resources. In this work, we propose a framework for large-scale question analysis. We utilize the state-of-the-art Bayesian deep learning method, in particular partial variational auto-encoders, to analyze real-world educational data. We also develop novel objectives to quantify question quality and difficulty. We apply our proposed framework to a real-world cohort with millions of question-answer pairs from an online education platform. Our framework not only demonstrates promising results in terms of statistical metrics but also obtains highly consistent results with domain expert evaluation.
Resource-Efficient Neural Networks for Embedded Systems
Jan 07, 2020
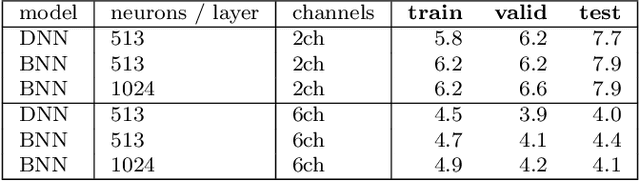
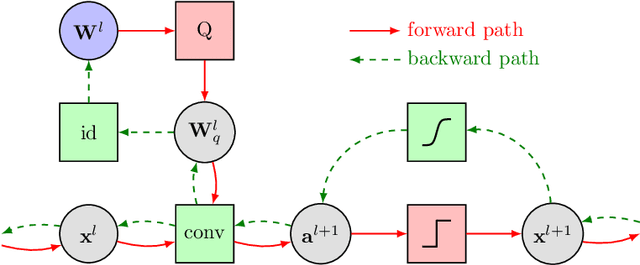
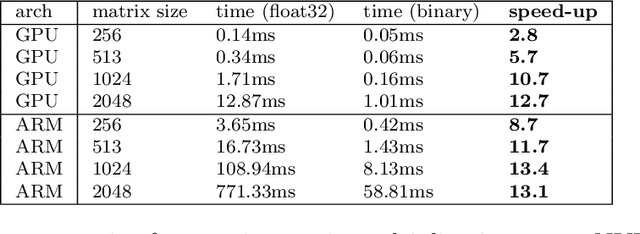
While machine learning is traditionally a resource intensive task, embedded systems, autonomous navigation, and the vision of the Internet of Things fuel the interest in resource-efficient approaches. These approaches aim for a carefully chosen trade-off between performance and resource consumption in terms of computation and energy. The development of such approaches is among the major challenges in current machine learning research and key to ensure a smooth transition of machine learning technology from a scientific environment with virtually unlimited computing resources into every day's applications. In this article, we provide an overview of the current state of the art of machine learning techniques facilitating these real-world requirements. In particular, we focus on deep neural networks (DNNs), the predominant machine learning models of the past decade. We give a comprehensive overview of the vast literature that can be mainly split into three non-mutually exclusive categories: (i) quantized neural networks, (ii) network pruning, and (iii) structural efficiency. These techniques can be applied during training or as post-processing, and they are widely used to reduce the computational demands in terms of memory footprint, inference speed, and energy efficiency. We substantiate our discussion with experiments on well-known benchmark data sets to showcase the difficulty of finding good trade-offs between resource-efficiency and predictive performance.
Collaborative Machine Learning Markets with Data-Replication-Robust Payments
Nov 08, 2019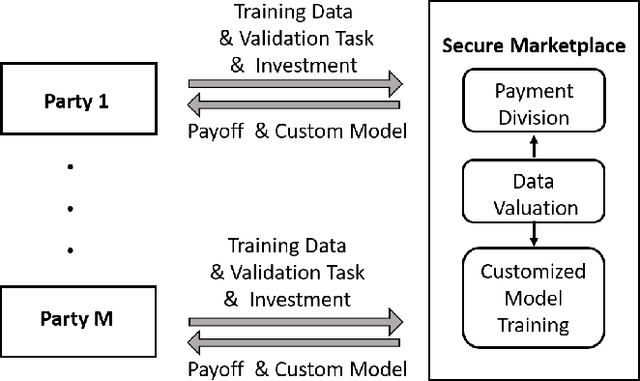
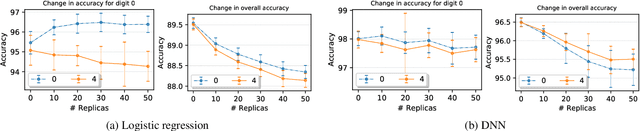
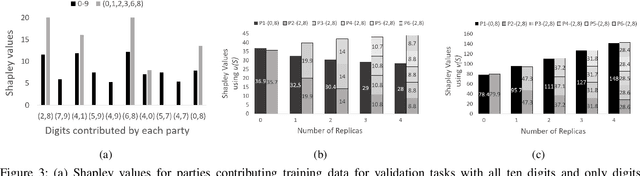
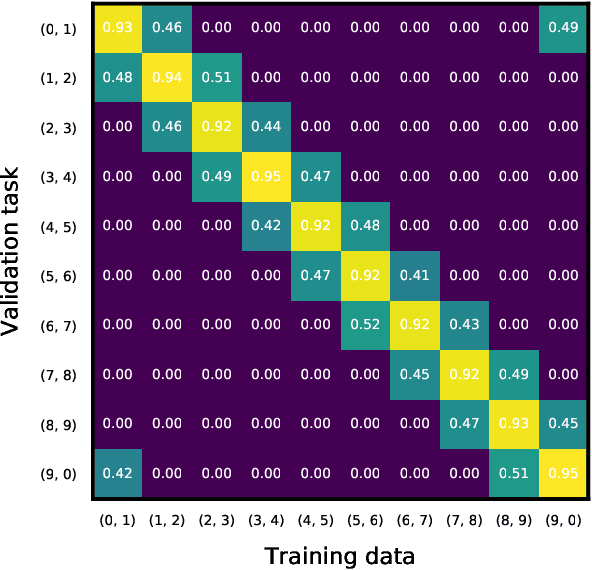
We study the problem of collaborative machine learning markets where multiple parties can achieve improved performance on their machine learning tasks by combining their training data. We discuss desired properties for these machine learning markets in terms of fair revenue distribution and potential threats, including data replication. We then instantiate a collaborative market for cases where parties share a common machine learning task and where parties' tasks are different. Our marketplace incentivizes parties to submit high quality training and true validation data. To this end, we introduce a novel payment division function that is robust-to-replication and customized output models that perform well only on requested machine learning tasks. In experiments, we validate the assumptions underlying our theoretical analysis and show that these are approximately satisfied for commonly used machine learning models.
Generalization in Reinforcement Learning with Selective Noise Injection and Information Bottleneck
Oct 28, 2019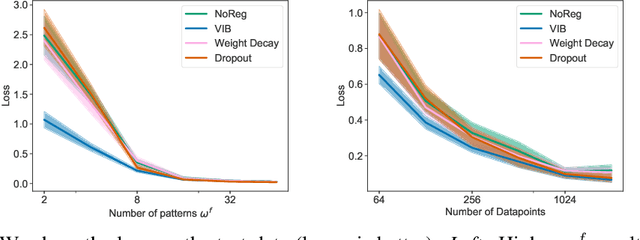
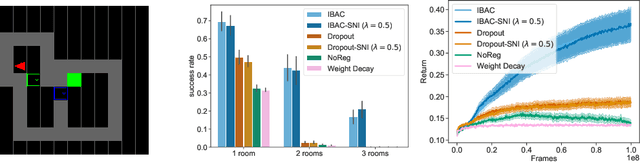
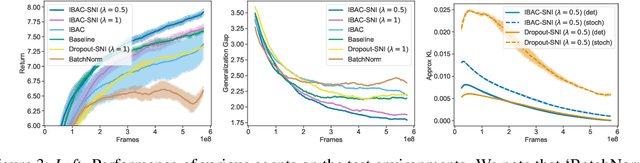
The ability for policies to generalize to new environments is key to the broad application of RL agents. A promising approach to prevent an agent's policy from overfitting to a limited set of training environments is to apply regularization techniques originally developed for supervised learning. However, there are stark differences between supervised learning and RL. We discuss those differences and propose modifications to existing regularization techniques in order to better adapt them to RL. In particular, we focus on regularization techniques relying on the injection of noise into the learned function, a family that includes some of the most widely used approaches such as Dropout and Batch Normalization. To adapt them to RL, we propose Selective Noise Injection (SNI), which maintains the regularizing effect the injected noise has, while mitigating the adverse effects it has on the gradient quality. Furthermore, we demonstrate that the Information Bottleneck (IB) is a particularly well suited regularization technique for RL as it is effective in the low-data regime encountered early on in training RL agents. Combining the IB with SNI, we significantly outperform current state of the art results, including on the recently proposed generalization benchmark Coinrun.
Towards Deployment of Robust AI Agents for Human-Machine Partnerships
Oct 05, 2019
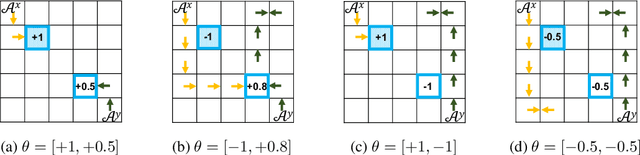
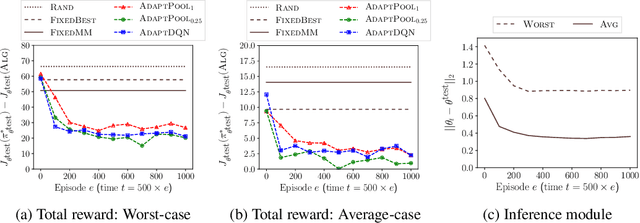
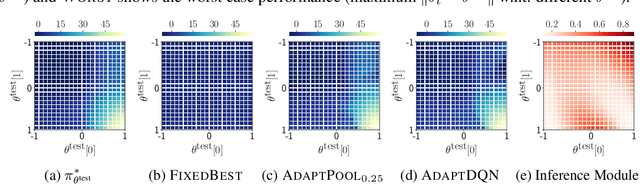
We study the problem of designing AI agents that can robustly cooperate with people in human-machine partnerships. Our work is inspired by real-life scenarios in which an AI agent, e.g., a virtual assistant, has to cooperate with new users after its deployment. We model this problem via a parametric MDP framework where the parameters correspond to a user's type and characterize her behavior. In the test phase, the AI agent has to interact with a user of unknown type. Our approach to designing a robust AI agent relies on observing the user's actions to make inferences about the user's type and adapting its policy to facilitate efficient cooperation. We show that without being adaptive, an AI agent can end up performing arbitrarily bad in the test phase. We develop two algorithms for computing policies that automatically adapt to the user in the test phase. We demonstrate the effectiveness of our approach in solving a two-agent collaborative task.
Icebreaker: Element-wise Active Information Acquisition with Bayesian Deep Latent Gaussian Model
Aug 14, 2019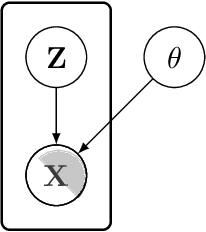
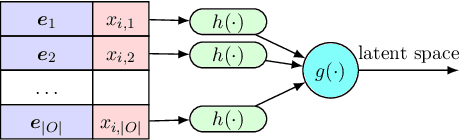
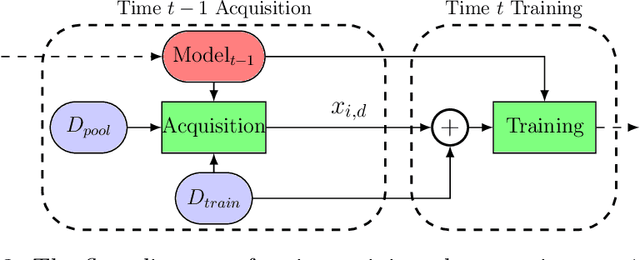
In this paper we introduce the ice-start problem, i.e., the challenge of deploying machine learning models when only little or no training data is initially available, and acquiring each feature element of data is associated with costs. This setting is representative for the real-world machine learning applications. For instance, in the health-care domain, when training an AI system for predicting patient metrics from lab tests, obtaining every single measurement comes with a high cost. Active learning, where only the label is associated with a cost does not apply to such problem, because performing all possible lab tests to acquire a new training datum would be costly, as well as unnecessary due to redundancy. We propose Icebreaker, a principled framework to approach the ice-start problem. Icebreaker uses a full Bayesian Deep Latent Gaussian Model (BELGAM) with a novel inference method. Our proposed method combines recent advances in amortized inference and stochastic gradient MCMC to enable fast and accurate posterior inference. By utilizing BELGAM's ability to fully quantify model uncertainty, we also propose two information acquisition functions for imputation and active prediction problems. We demonstrate that BELGAM performs significantly better than the previous VAE (Variational autoencoder) based models, when the data set size is small, using both machine learning benchmarks and real-world recommender systems and health-care applications. Moreover, based on BELGAM, Icebreaker further improves the performance and demonstrate the ability to use minimum amount of the training data to obtain the highest test time performance.
Learner-aware Teaching: Inverse Reinforcement Learning with Preferences and Constraints
Jun 02, 2019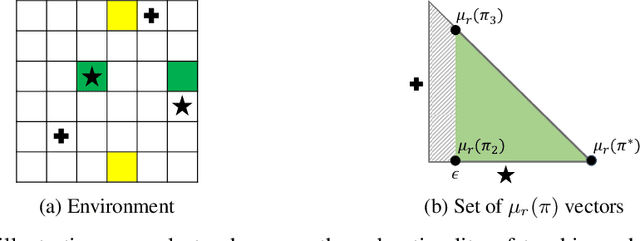

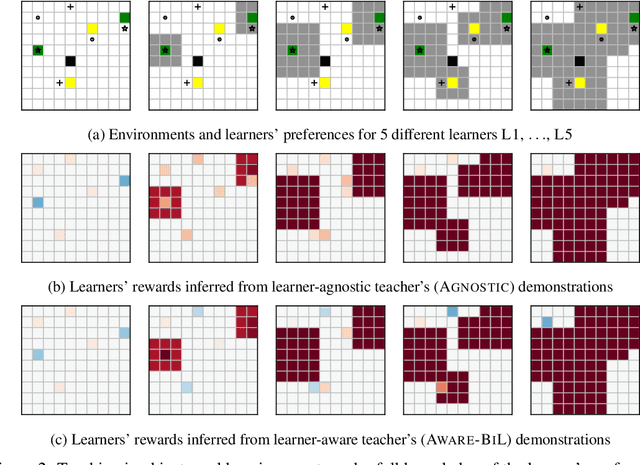

Inverse reinforcement learning (IRL) enables an agent to learn complex behavior by observing demonstrations from a (near-)optimal policy. The typical assumption is that the learner's goal is to match the teacher's demonstrated behavior. In this paper, we consider the setting where the learner has her own preferences that she additionally takes into consideration. These preferences can for example capture behavioral biases, mismatched worldviews, or physical constraints. We study two teaching approaches: learner-agnostic teaching, where the teacher provides demonstrations from an optimal policy ignoring the learner's preferences, and learner-aware teaching, where the teacher accounts for the learner's preferences. We design learner-aware teaching algorithms and show that significant performance improvements can be achieved over learner-agnostic teaching.
Efficient and Robust Machine Learning for Real-World Systems
Dec 05, 2018
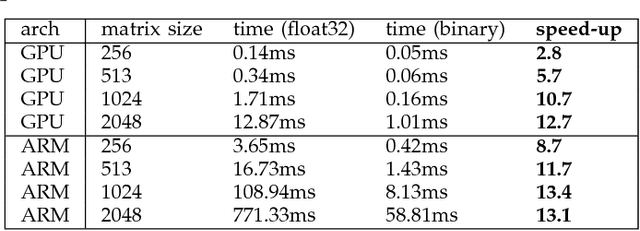
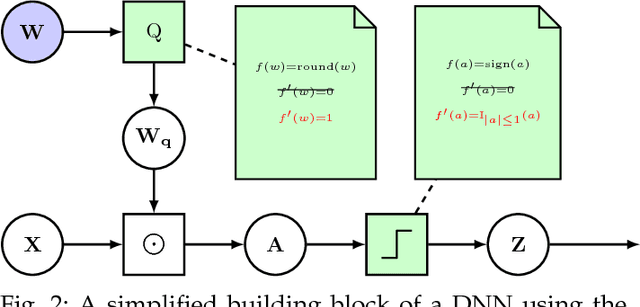
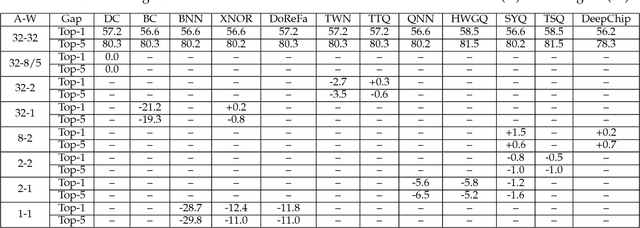
While machine learning is traditionally a resource intensive task, embedded systems, autonomous navigation and the vision of the Internet-of-Things fuel the interest in resource efficient approaches. These approaches require a carefully chosen trade-off between performance and resource consumption in terms of computation and energy. On top of this, it is crucial to treat uncertainty in a consistent manner in all but the simplest applications of machine learning systems. In particular, a desideratum for any real-world system is to be robust in the presence of outliers and corrupted data, as well as being `aware' of its limits, i.e.\ the system should maintain and provide an uncertainty estimate over its own predictions. These complex demands are among the major challenges in current machine learning research and key to ensure a smooth transition of machine learning technology into every day's applications. In this article, we provide an overview of the current state of the art of machine learning techniques facilitating these real-world requirements. First we provide a comprehensive review of resource-efficiency in deep neural networks with focus on techniques for model size reduction, compression and reduced precision. These techniques can be applied during training or as post-processing and are widely used to reduce both computational complexity and memory footprint. As most (practical) neural networks are limited in their ways to treat uncertainty, we contrast them with probabilistic graphical models, which readily serve these desiderata by means of probabilistic inference. In that way, we provide an extensive overview of the current state-of-the-art of robust and efficient machine learning for real-world systems.