 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApplication of Clinical Concept Embeddings for Heart Failure Prediction in UK EHR data
Nov 28, 2018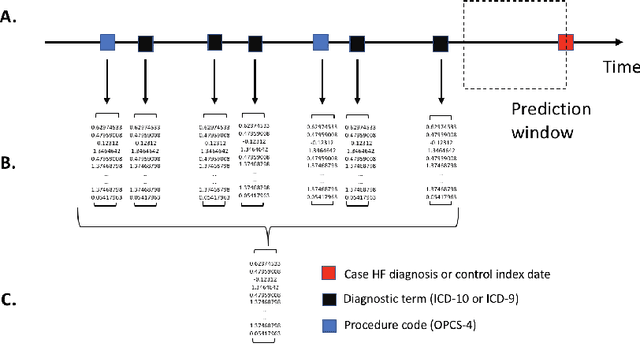
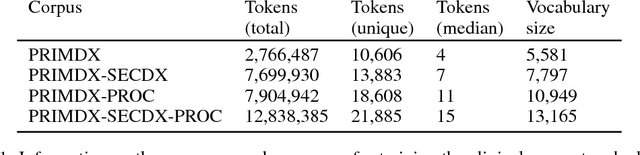

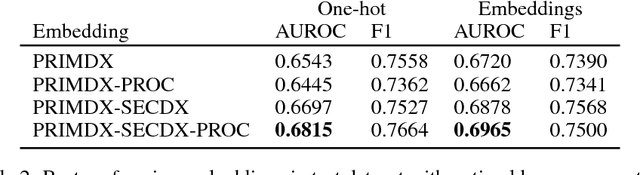
Electronic health records (EHR) are increasingly being used for constructing disease risk prediction models. Feature engineering in EHR data however is challenging due to their highly dimensional and heterogeneous nature. Low-dimensional representations of EHR data can potentially mitigate these challenges. In this paper, we use global vectors (GloVe) to learn word embeddings for diagnoses and procedures recorded using 13 million ontology terms across 2.7 million hospitalisations in national UK EHR. We demonstrate the utility of these embeddings by evaluating their performance in identifying patients which are at higher risk of being hospitalised for congestive heart failure. Our findings indicate that embeddings can enable the creation of robust EHR-derived disease risk prediction models and address some the limitations associated with manual clinical feature engineering.
Wronging a Right: Generating Better Errors to Improve Grammatical Error Detection
Sep 26, 2018
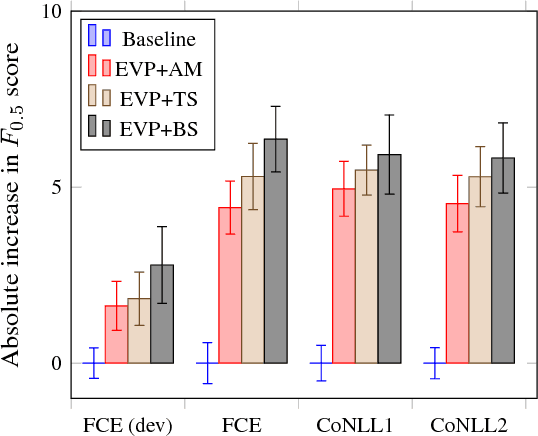
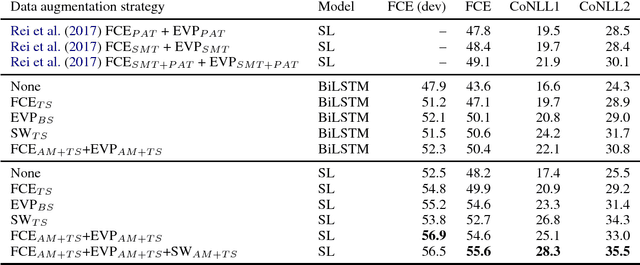
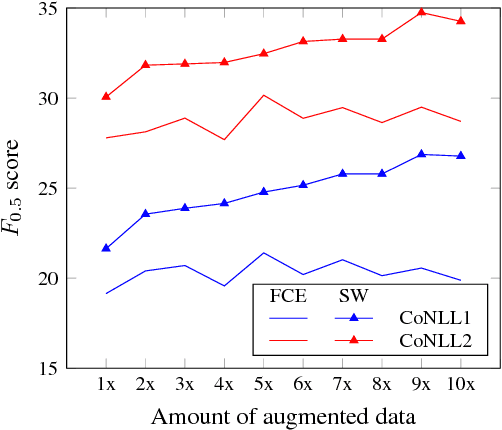
Grammatical error correction, like other machine learning tasks, greatly benefits from large quantities of high quality training data, which is typically expensive to produce. While writing a program to automatically generate realistic grammatical errors would be difficult, one could learn the distribution of naturallyoccurring errors and attempt to introduce them into other datasets. Initial work on inducing errors in this way using statistical machine translation has shown promise; we investigate cheaply constructing synthetic samples, given a small corpus of human-annotated data, using an off-the-rack attentive sequence-to-sequence model and a straight-forward post-processing procedure. Our approach yields error-filled artificial data that helps a vanilla bi-directional LSTM to outperform the previous state of the art at grammatical error detection, and a previously introduced model to gain further improvements of over 5% $F_{0.5}$ score. When attempting to determine if a given sentence is synthetic, a human annotator at best achieves 39.39 $F_1$ score, indicating that our model generates mostly human-like instances.
Logical Rule Induction and Theory Learning Using Neural Theorem Proving
Sep 12, 2018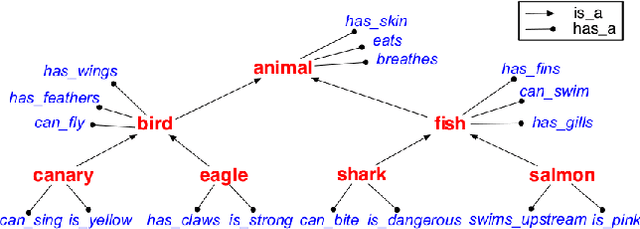
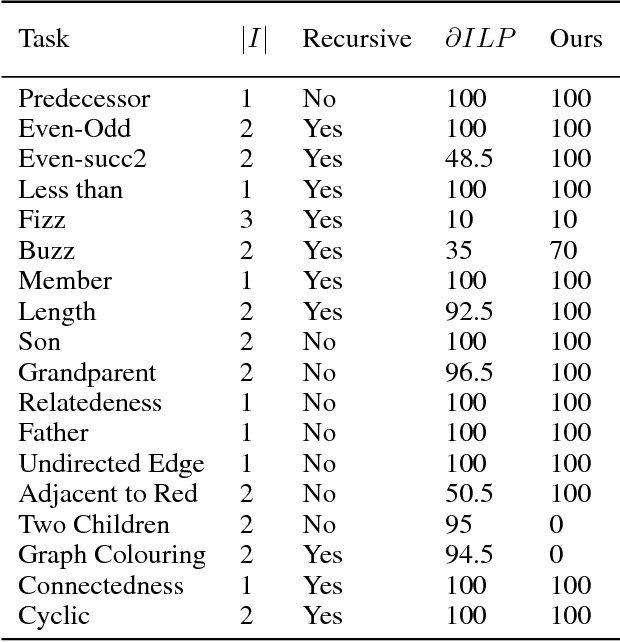
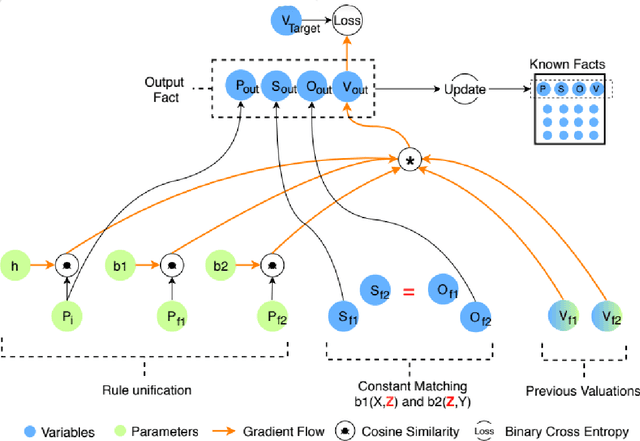
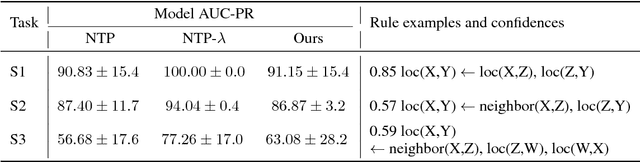
A hallmark of human cognition is the ability to continually acquire and distill observations of the world into meaningful, predictive theories. In this paper we present a new mechanism for logical theory acquisition which takes a set of observed facts and learns to extract from them a set of logical rules and a small set of core facts which together entail the observations. Our approach is neuro-symbolic in the sense that the rule pred- icates and core facts are given dense vector representations. The rules are applied to the core facts using a soft unification procedure to infer additional facts. After k steps of forward inference, the consequences are compared to the initial observations and the rules and core facts are then encouraged towards representations that more faithfully generate the observations through inference. Our approach is based on a novel neural forward-chaining differentiable rule induction network. The rules are interpretable and learned compositionally from their predicates, which may be invented. We demonstrate the efficacy of our approach on a variety of ILP rule induction and domain theory learning datasets.
Interpretation of Natural Language Rules in Conversational Machine Reading
Aug 28, 2018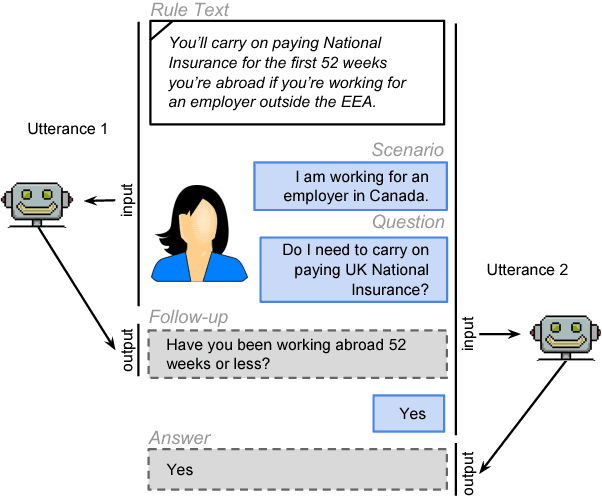

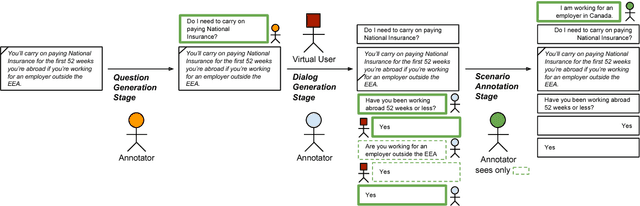
Most work in machine reading focuses on question answering problems where the answer is directly expressed in the text to read. However, many real-world question answering problems require the reading of text not because it contains the literal answer, but because it contains a recipe to derive an answer together with the reader's background knowledge. One example is the task of interpreting regulations to answer "Can I...?" or "Do I have to...?" questions such as "I am working in Canada. Do I have to carry on paying UK National Insurance?" after reading a UK government website about this topic. This task requires both the interpretation of rules and the application of background knowledge. It is further complicated due to the fact that, in practice, most questions are underspecified, and a human assistant will regularly have to ask clarification questions such as "How long have you been working abroad?" when the answer cannot be directly derived from the question and text. In this paper, we formalise this task and develop a crowd-sourcing strategy to collect 32k task instances based on real-world rules and crowd-generated questions and scenarios. We analyse the challenges of this task and assess its difficulty by evaluating the performance of rule-based and machine-learning baselines. We observe promising results when no background knowledge is necessary, and substantial room for improvement whenever background knowledge is needed.
Adversarially Regularising Neural NLI Models to Integrate Logical Background Knowledge
Aug 26, 2018
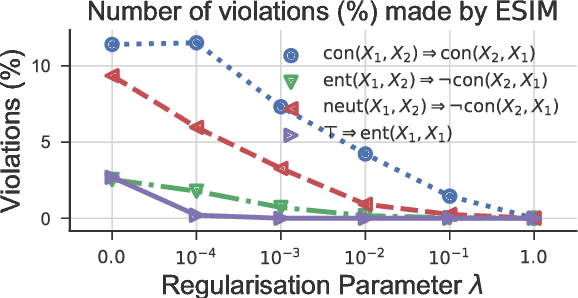
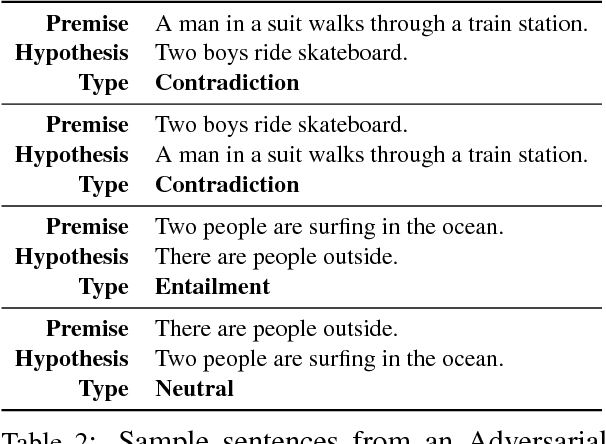
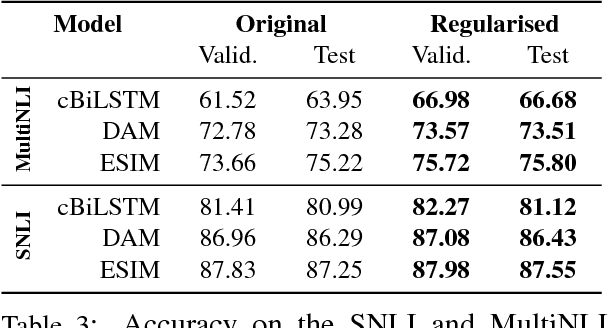
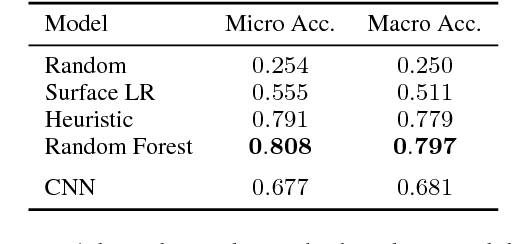
Adversarial examples are inputs to machine learning models designed to cause the model to make a mistake. They are useful for understanding the shortcomings of machine learning models, interpreting their results, and for regularisation. In NLP, however, most example generation strategies produce input text by using known, pre-specified semantic transformations, requiring significant manual effort and in-depth understanding of the problem and domain. In this paper, we investigate the problem of automatically generating adversarial examples that violate a set of given First-Order Logic constraints in Natural Language Inference (NLI). We reduce the problem of identifying such adversarial examples to a combinatorial optimisation problem, by maximising a quantity measuring the degree of violation of such constraints and by using a language model for generating linguistically-plausible examples. Furthermore, we propose a method for adversarially regularising neural NLI models for incorporating background knowledge. Our results show that, while the proposed method does not always improve results on the SNLI and MultiNLI datasets, it significantly and consistently increases the predictive accuracy on adversarially-crafted datasets -- up to a 79.6% relative improvement -- while drastically reducing the number of background knowledge violations. Furthermore, we show that adversarial examples transfer among model architectures, and that the proposed adversarial training procedure improves the robustness of NLI models to adversarial examples.
Towards Neural Theorem Proving at Scale
Jul 21, 2018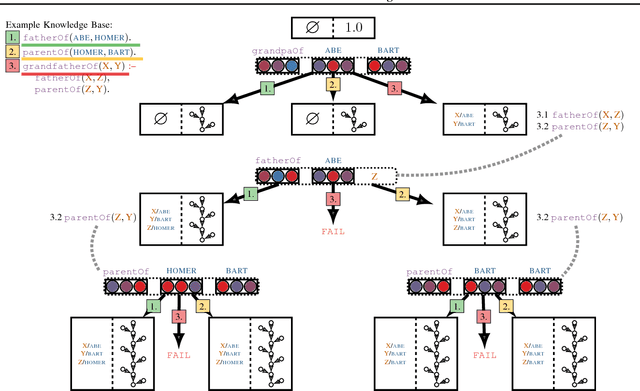
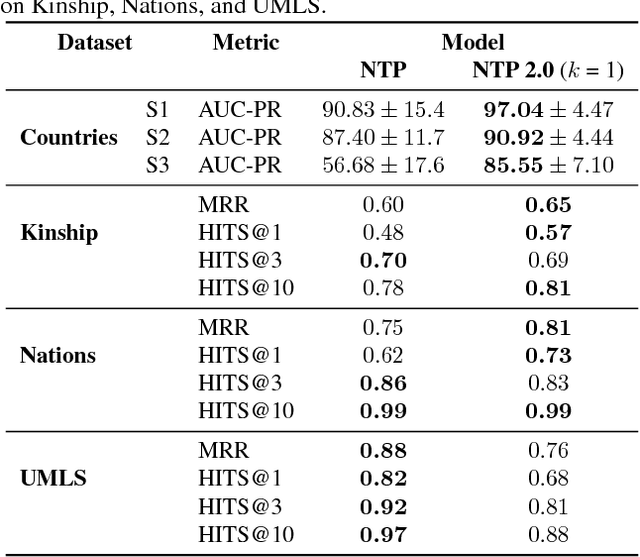
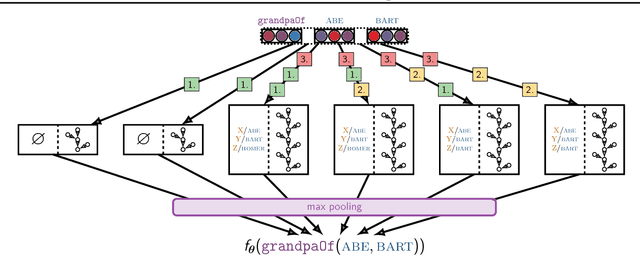

Neural models combining representation learning and reasoning in an end-to-end trainable manner are receiving increasing interest. However, their use is severely limited by their computational complexity, which renders them unusable on real world datasets. We focus on the Neural Theorem Prover (NTP) model proposed by Rockt{\"{a}}schel and Riedel (2017), a continuous relaxation of the Prolog backward chaining algorithm where unification between terms is replaced by the similarity between their embedding representations. For answering a given query, this model needs to consider all possible proof paths, and then aggregate results - this quickly becomes infeasible even for small Knowledge Bases (KBs). We observe that we can accurately approximate the inference process in this model by considering only proof paths associated with the highest proof scores. This enables inference and learning on previously impracticable KBs.
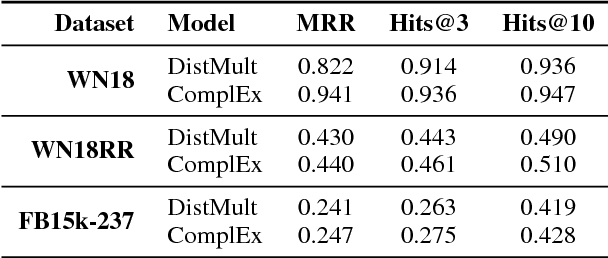
Convolutional 2D Knowledge Graph Embeddings
Jul 04, 2018
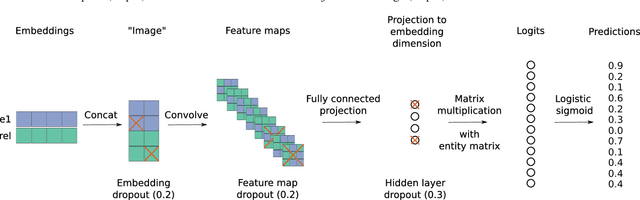
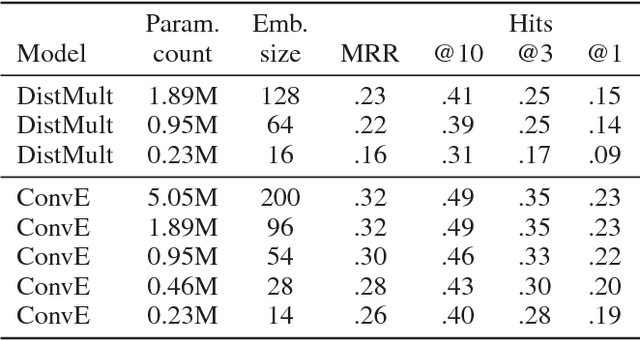
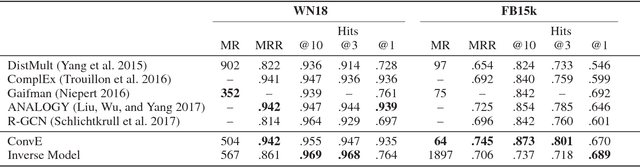
Link prediction for knowledge graphs is the task of predicting missing relationships between entities. Previous work on link prediction has focused on shallow, fast models which can scale to large knowledge graphs. However, these models learn less expressive features than deep, multi-layer models -- which potentially limits performance. In this work, we introduce ConvE, a multi-layer convolutional network model for link prediction, and report state-of-the-art results for several established datasets. We also show that the model is highly parameter efficient, yielding the same performance as DistMult and R-GCN with 8x and 17x fewer parameters. Analysis of our model suggests that it is particularly effective at modelling nodes with high indegree -- which are common in highly-connected, complex knowledge graphs such as Freebase and YAGO3. In addition, it has been noted that the WN18 and FB15k datasets suffer from test set leakage, due to inverse relations from the training set being present in the test set -- however, the extent of this issue has so far not been quantified. We find this problem to be severe: a simple rule-based model can achieve state-of-the-art results on both WN18 and FB15k. To ensure that models are evaluated on datasets where simply exploiting inverse relations cannot yield competitive results, we investigate and validate several commonly used datasets -- deriving robust variants where necessary. We then perform experiments on these robust datasets for our own and several previously proposed models and find that ConvE achieves state-of-the-art Mean Reciprocal Rank across most datasets.
Jack the Reader - A Machine Reading Framework
Jun 20, 2018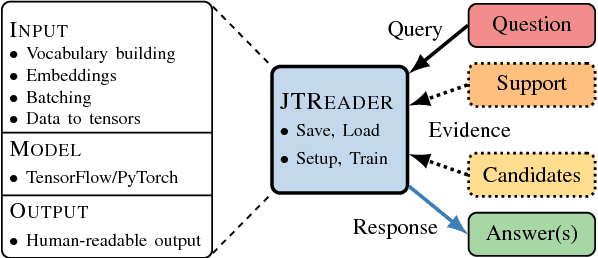
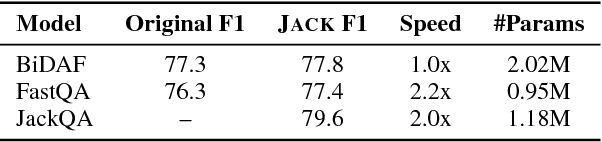

Many Machine Reading and Natural Language Understanding tasks require reading supporting text in order to answer questions. For example, in Question Answering, the supporting text can be newswire or Wikipedia articles; in Natural Language Inference, premises can be seen as the supporting text and hypotheses as questions. Providing a set of useful primitives operating in a single framework of related tasks would allow for expressive modelling, and easier model comparison and replication. To that end, we present Jack the Reader (Jack), a framework for Machine Reading that allows for quick model prototyping by component reuse, evaluation of new models on existing datasets as well as integrating new datasets and applying them on a growing set of implemented baseline models. Jack is currently supporting (but not limited to) three tasks: Question Answering, Natural Language Inference, and Link Prediction. It is developed with the aim of increasing research efficiency and code reuse.
Constructing Datasets for Multi-hop Reading Comprehension Across Documents
Jun 11, 2018Most Reading Comprehension methods limit themselves to queries which can be answered using a single sentence, paragraph, or document. Enabling models to combine disjoint pieces of textual evidence would extend the scope of machine comprehension methods, but currently there exist no resources to train and test this capability. We propose a novel task to encourage the development of models for text understanding across multiple documents and to investigate the limits of existing methods. In our task, a model learns to seek and combine evidence - effectively performing multi-hop (alias multi-step) inference. We devise a methodology to produce datasets for this task, given a collection of query-answer pairs and thematically linked documents. Two datasets from different domains are induced, and we identify potential pitfalls and devise circumvention strategies. We evaluate two previously proposed competitive models and find that one can integrate information across documents. However, both models struggle to select relevant information, as providing documents guaranteed to be relevant greatly improves their performance. While the models outperform several strong baselines, their best accuracy reaches 42.9% compared to human performance at 74.0% - leaving ample room for improvement.
* This paper directly corresponds to the TACL version (https://transacl.org/ojs/index.php/tacl/article/view/1325) apart from minor changes in wording, additional footnotes, and appendices
Numeracy for Language Models: Evaluating and Improving their Ability to Predict Numbers
May 21, 2018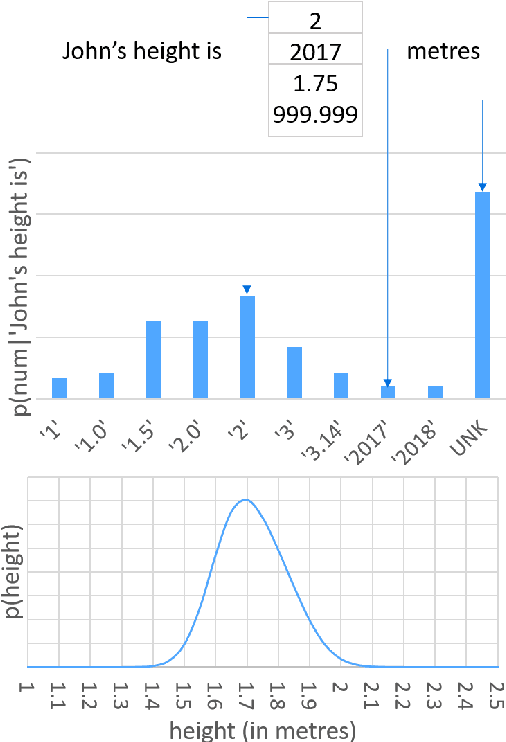
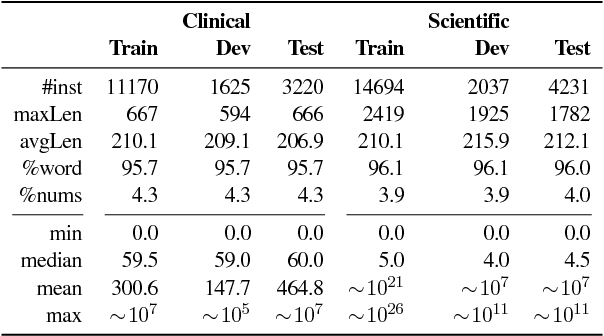
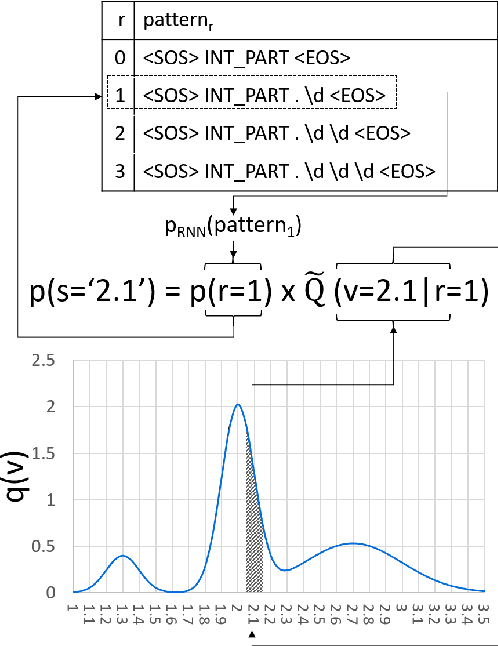
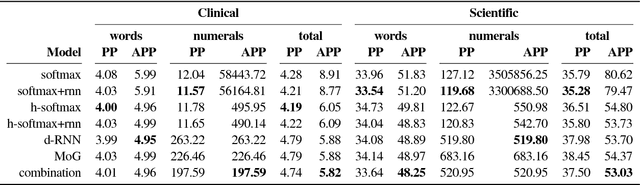
Numeracy is the ability to understand and work with numbers. It is a necessary skill for composing and understanding documents in clinical, scientific, and other technical domains. In this paper, we explore different strategies for modelling numerals with language models, such as memorisation and digit-by-digit composition, and propose a novel neural architecture that uses a continuous probability density function to model numerals from an open vocabulary. Our evaluation on clinical and scientific datasets shows that using hierarchical models to distinguish numerals from words improves a perplexity metric on the subset of numerals by 2 and 4 orders of magnitude, respectively, over non-hierarchical models. A combination of strategies can further improve perplexity. Our continuous probability density function model reduces mean absolute percentage errors by 18% and 54% in comparison to the second best strategy for each dataset, respectively.