 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Architectures for Fine-grained Entity Type Classification
Feb 21, 2017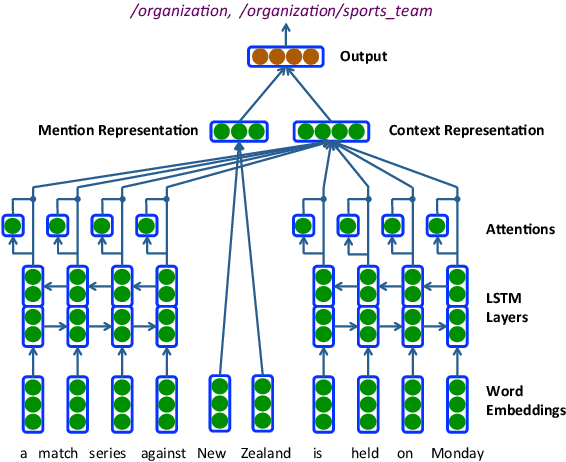

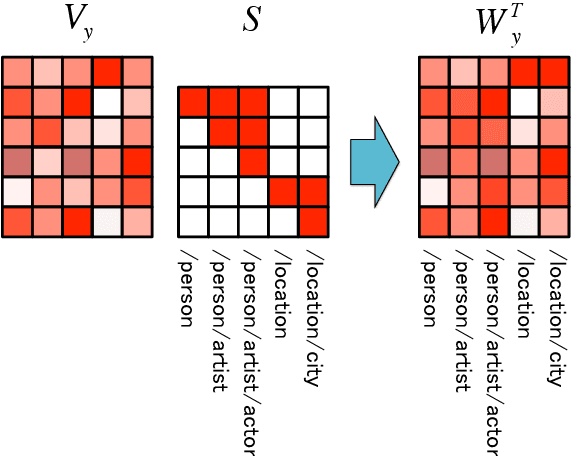
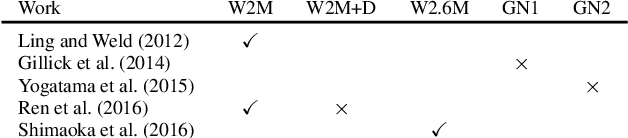
In this work, we investigate several neural network architectures for fine-grained entity type classification. Particularly, we consider extensions to a recently proposed attentive neural architecture and make three key contributions. Previous work on attentive neural architectures do not consider hand-crafted features, we combine learnt and hand-crafted features and observe that they complement each other. Additionally, through quantitative analysis we establish that the attention mechanism is capable of learning to attend over syntactic heads and the phrase containing the mention, where both are known strong hand-crafted features for our task. We enable parameter sharing through a hierarchical label encoding method, that in low-dimensional projections show clear clusters for each type hierarchy. Lastly, despite using the same evaluation dataset, the literature frequently compare models trained using different data. We establish that the choice of training data has a drastic impact on performance, with decreases by as much as 9.85% loose micro F1 score for a previously proposed method. Despite this, our best model achieves state-of-the-art results with 75.36% loose micro F1 score on the well- established FIGER (GOLD) dataset.
Frustratingly Short Attention Spans in Neural Language Modeling
Feb 15, 2017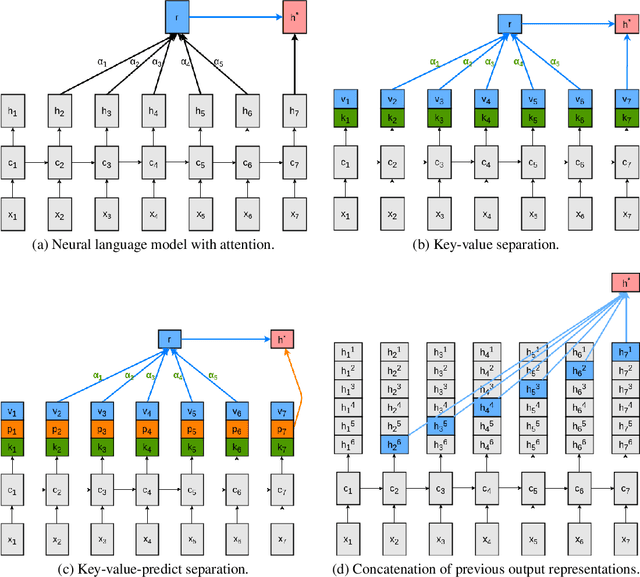
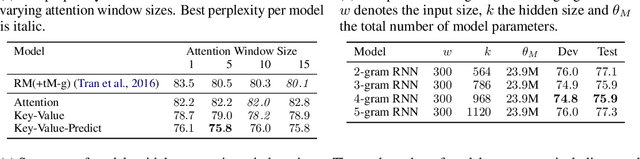
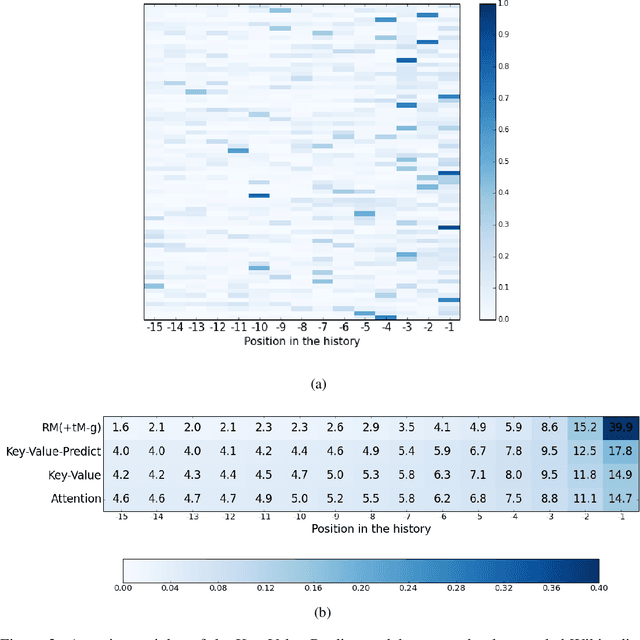
Neural language models predict the next token using a latent representation of the immediate token history. Recently, various methods for augmenting neural language models with an attention mechanism over a differentiable memory have been proposed. For predicting the next token, these models query information from a memory of the recent history which can facilitate learning mid- and long-range dependencies. However, conventional attention mechanisms used in memory-augmented neural language models produce a single output vector per time step. This vector is used both for predicting the next token as well as for the key and value of a differentiable memory of a token history. In this paper, we propose a neural language model with a key-value attention mechanism that outputs separate representations for the key and value of a differentiable memory, as well as for encoding the next-word distribution. This model outperforms existing memory-augmented neural language models on two corpora. Yet, we found that our method mainly utilizes a memory of the five most recent output representations. This led to the unexpected main finding that a much simpler model based only on the concatenation of recent output representations from previous time steps is on par with more sophisticated memory-augmented neural language models.
Community Question Answering Platforms vs. Twitter for Predicting Characteristics of Urban Neighbourhoods
Jan 17, 2017
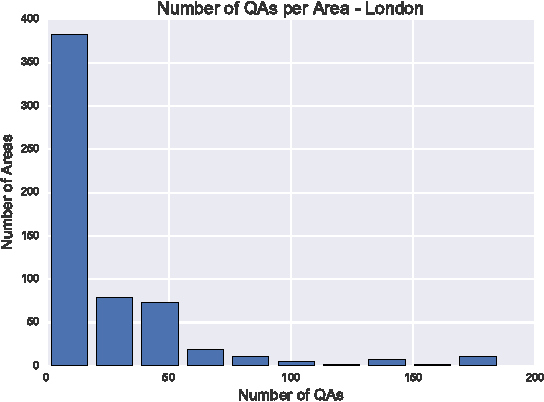
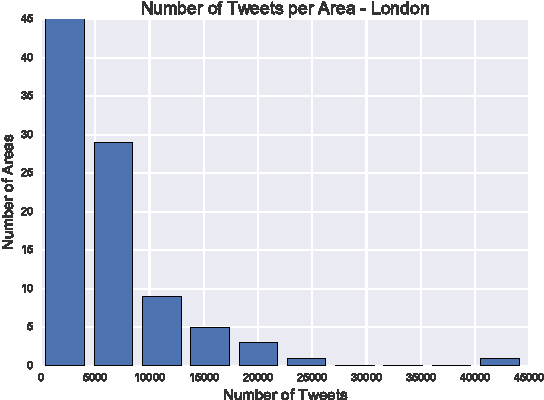
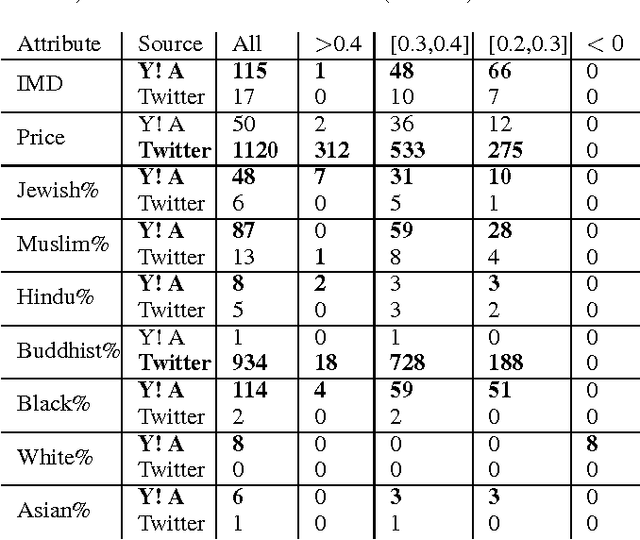
In this paper, we investigate whether text from a Community Question Answering (QA) platform can be used to predict and describe real-world attributes. We experiment with predicting a wide range of 62 demographic attributes for neighbourhoods of London. We use the text from QA platform of Yahoo! Answers and compare our results to the ones obtained from Twitter microblogs. Outcomes show that the correlation between the predicted demographic attributes using text from Yahoo! Answers discussions and the observed demographic attributes can reach an average Pearson correlation coefficient of \r{ho} = 0.54, slightly higher than the predictions obtained using Twitter data. Our qualitative analysis indicates that there is semantic relatedness between the highest correlated terms extracted from both datasets and their relative demographic attributes. Furthermore, the correlations highlight the different natures of the information contained in Yahoo! Answers and Twitter. While the former seems to offer a more encyclopedic content, the latter provides information related to the current sociocultural aspects or phenomena.
Deep Semi-Supervised Learning with Linguistically Motivated Sequence Labeling Task Hierarchies
Dec 29, 2016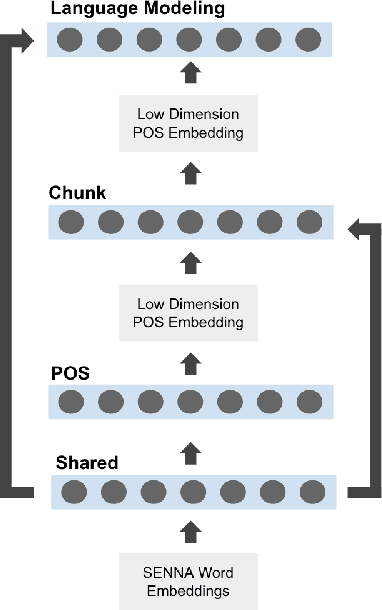

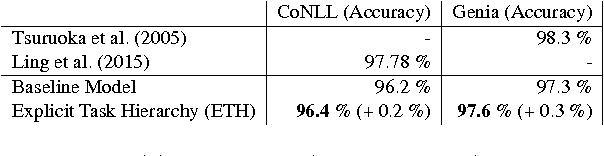
In this paper we present a novel Neural Network algorithm for conducting semi-supervised learning for sequence labeling tasks arranged in a linguistically motivated hierarchy. This relationship is exploited to regularise the representations of supervised tasks by backpropagating the error of the unsupervised task through the supervised tasks. We introduce a neural network where lower layers are supervised by junior downstream tasks and the final layer task is an auxiliary unsupervised task. The architecture shows improvements of up to two percentage points F1 for Chunking compared to a plausible baseline.
Learning Python Code Suggestion with a Sparse Pointer Network
Nov 24, 2016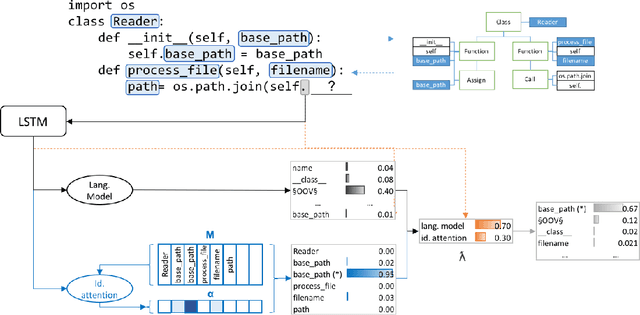
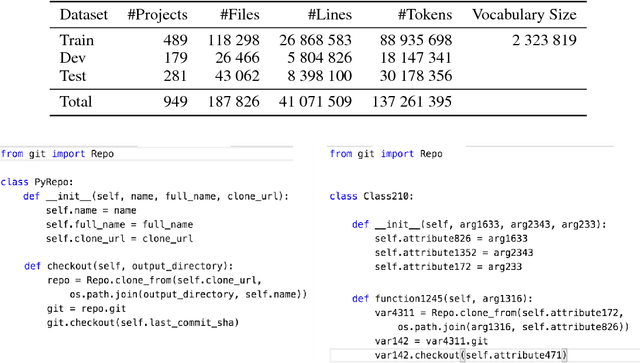
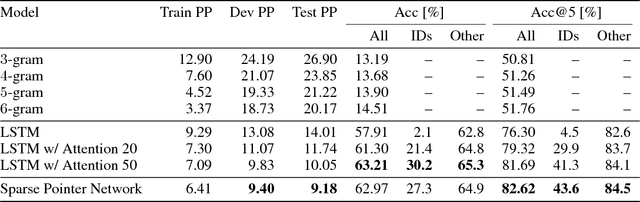
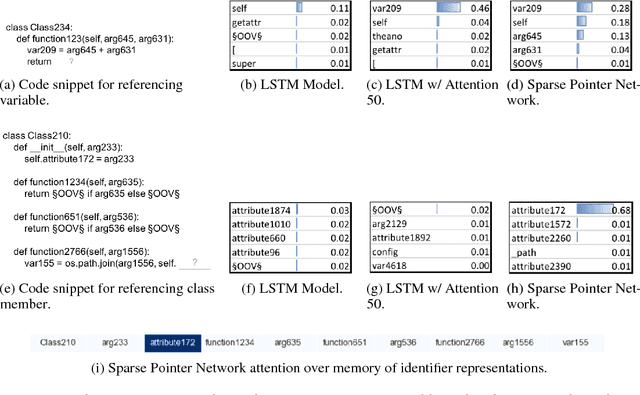
To enhance developer productivity, all modern integrated development environments (IDEs) include code suggestion functionality that proposes likely next tokens at the cursor. While current IDEs work well for statically-typed languages, their reliance on type annotations means that they do not provide the same level of support for dynamic programming languages as for statically-typed languages. Moreover, suggestion engines in modern IDEs do not propose expressions or multi-statement idiomatic code. Recent work has shown that language models can improve code suggestion systems by learning from software repositories. This paper introduces a neural language model with a sparse pointer network aimed at capturing very long-range dependencies. We release a large-scale code suggestion corpus of 41M lines of Python code crawled from GitHub. On this corpus, we found standard neural language models to perform well at suggesting local phenomena, but struggle to refer to identifiers that are introduced many tokens in the past. By augmenting a neural language model with a pointer network specialized in referring to predefined classes of identifiers, we obtain a much lower perplexity and a 5 percentage points increase in accuracy for code suggestion compared to an LSTM baseline. In fact, this increase in code suggestion accuracy is due to a 13 times more accurate prediction of identifiers. Furthermore, a qualitative analysis shows this model indeed captures interesting long-range dependencies, like referring to a class member defined over 60 tokens in the past.
emoji2vec: Learning Emoji Representations from their Description
Nov 20, 2016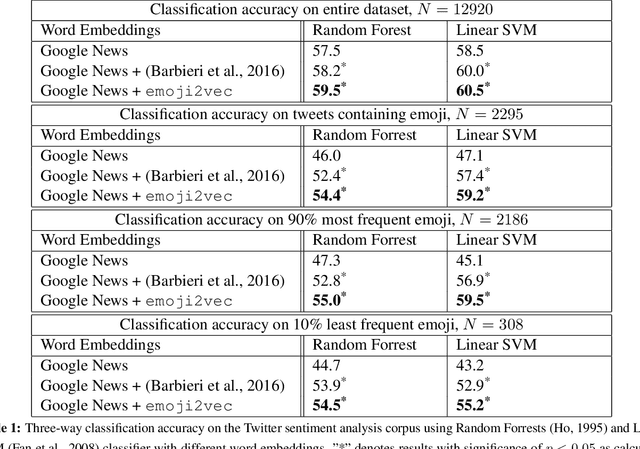
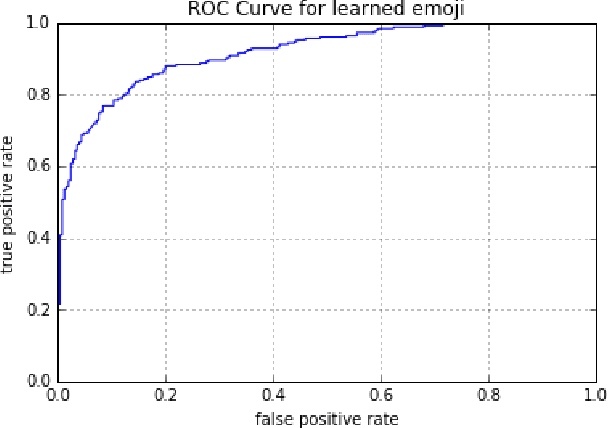

Many current natural language processing applications for social media rely on representation learning and utilize pre-trained word embeddings. There currently exist several publicly-available, pre-trained sets of word embeddings, but they contain few or no emoji representations even as emoji usage in social media has increased. In this paper we release emoji2vec, pre-trained embeddings for all Unicode emoji which are learned from their description in the Unicode emoji standard. The resulting emoji embeddings can be readily used in downstream social natural language processing applications alongside word2vec. We demonstrate, for the downstream task of sentiment analysis, that emoji embeddings learned from short descriptions outperforms a skip-gram model trained on a large collection of tweets, while avoiding the need for contexts in which emoji need to appear frequently in order to estimate a representation.
Learning to Reason With Adaptive Computation
Nov 10, 2016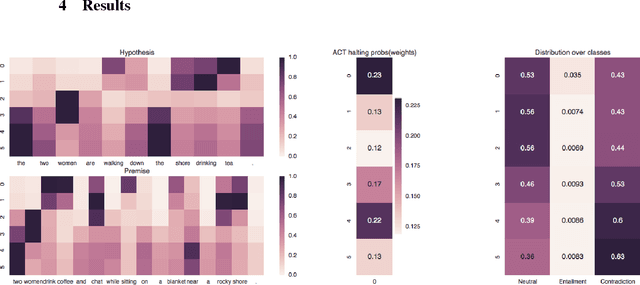

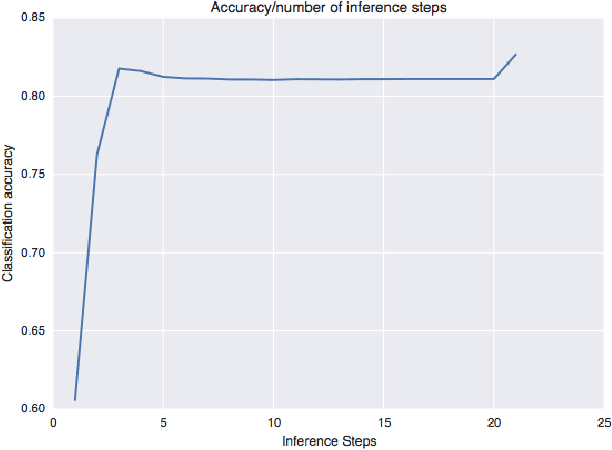

Multi-hop inference is necessary for machine learning systems to successfully solve tasks such as Recognising Textual Entailment and Machine Reading. In this work, we demonstrate the effectiveness of adaptive computation for learning the number of inference steps required for examples of different complexity and that learning the correct number of inference steps is difficult. We introduce the first model involving Adaptive Computation Time which provides a small performance benefit on top of a similar model without an adaptive component as well as enabling considerable insight into the reasoning process of the model.
Represent, Aggregate, and Constrain: A Novel Architecture for Machine Reading from Noisy Sources
Oct 30, 2016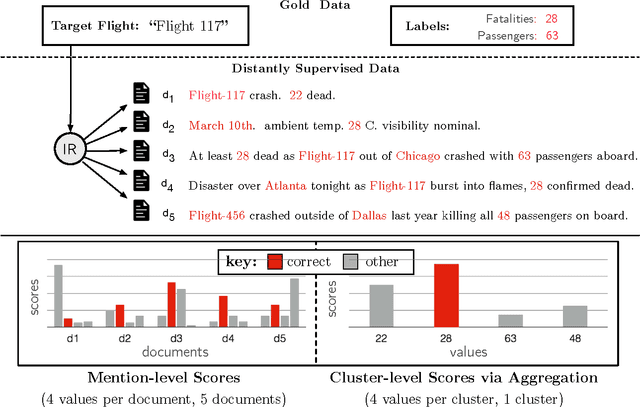
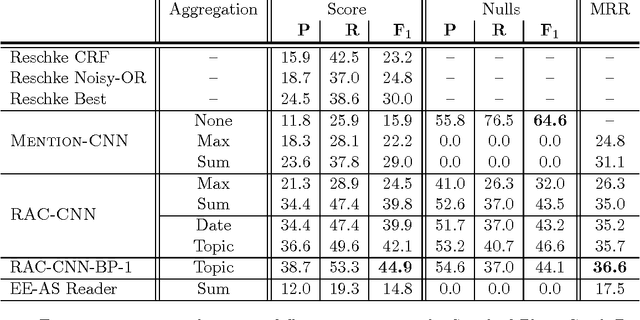
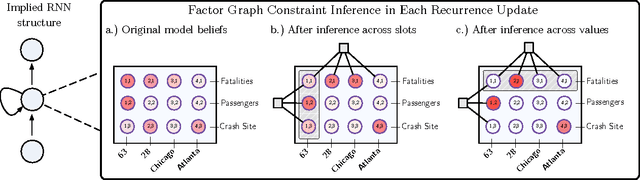
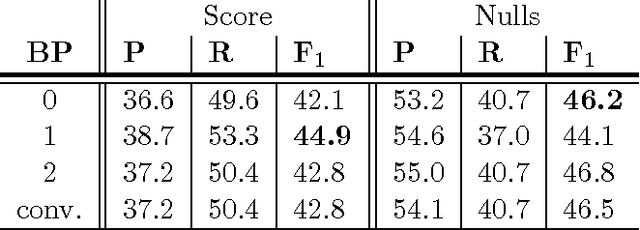
In order to extract event information from text, a machine reading model must learn to accurately read and interpret the ways in which that information is expressed. But it must also, as the human reader must, aggregate numerous individual value hypotheses into a single coherent global analysis, applying global constraints which reflect prior knowledge of the domain. In this work we focus on the task of extracting plane crash event information from clusters of related news articles whose labels are derived via distant supervision. Unlike previous machine reading work, we assume that while most target values will occur frequently in most clusters, they may also be missing or incorrect. We introduce a novel neural architecture to explicitly model the noisy nature of the data and to deal with these aforementioned learning issues. Our models are trained end-to-end and achieve an improvement of more than 12.1 F$_1$ over previous work, despite using far less linguistic annotation. We apply factor graph constraints to promote more coherent event analyses, with belief propagation inference formulated within the transitions of a recurrent neural network. We show this technique additionally improves maximum F$_1$ by up to 2.8 points, resulting in a relative improvement of $50\%$ over the previous state-of-the-art.
Clinical Text Prediction with Numerically Grounded Conditional Language Models
Oct 20, 2016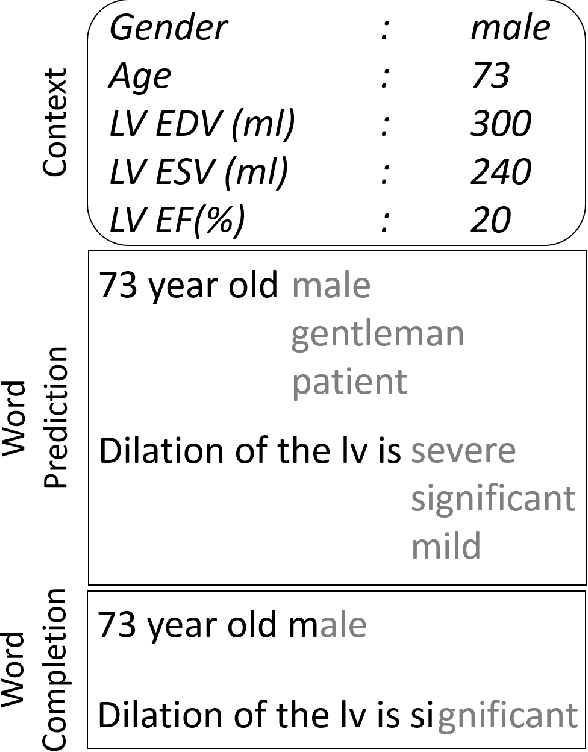
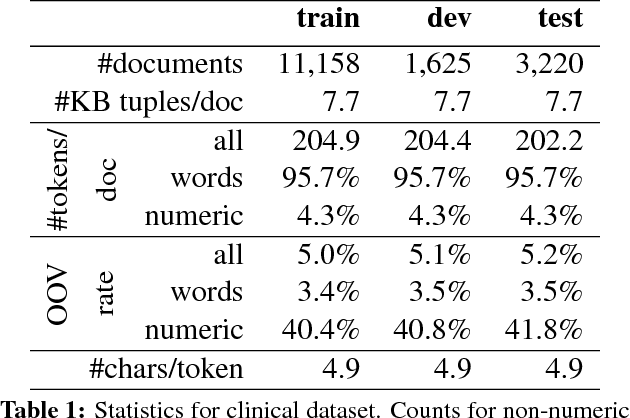
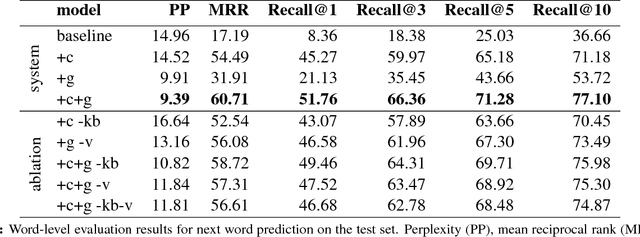
Assisted text input techniques can save time and effort and improve text quality. In this paper, we investigate how grounded and conditional extensions to standard neural language models can bring improvements in the tasks of word prediction and completion. These extensions incorporate a structured knowledge base and numerical values from the text into the context used to predict the next word. Our automated evaluation on a clinical dataset shows extended models significantly outperform standard models. Our best system uses both conditioning and grounding, because of their orthogonal benefits. For word prediction with a list of 5 suggestions, it improves recall from 25.03% to 71.28% and for word completion it improves keystroke savings from 34.35% to 44.81%, where theoretical bound for this dataset is 58.78%. We also perform a qualitative investigation of how models with lower perplexity occasionally fare better at the tasks. We found that at test time numbers have more influence on the document level than on individual word probabilities.
SentiHood: Targeted Aspect Based Sentiment Analysis Dataset for Urban Neighbourhoods
Oct 12, 2016
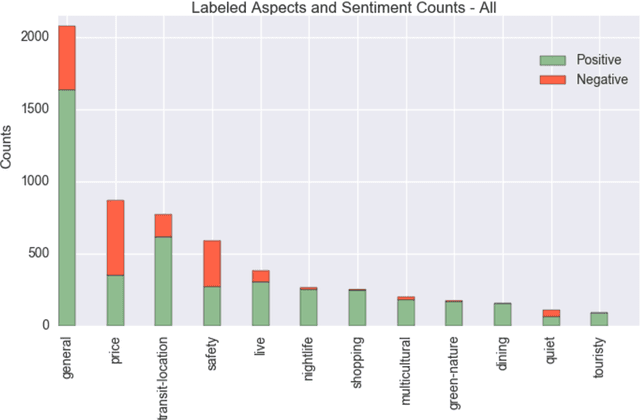
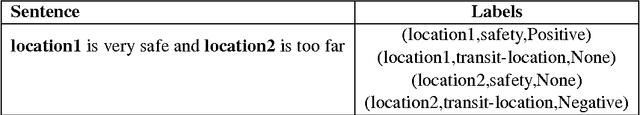
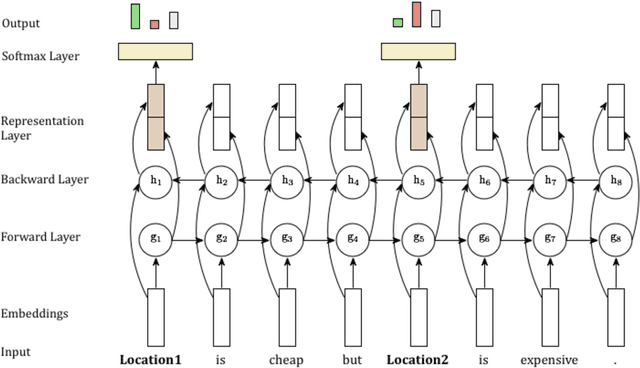
In this paper, we introduce the task of targeted aspect-based sentiment analysis. The goal is to extract fine-grained information with respect to entities mentioned in user comments. This work extends both aspect-based sentiment analysis that assumes a single entity per document and targeted sentiment analysis that assumes a single sentiment towards a target entity. In particular, we identify the sentiment towards each aspect of one or more entities. As a testbed for this task, we introduce the SentiHood dataset, extracted from a question answering (QA) platform where urban neighbourhoods are discussed by users. In this context units of text often mention several aspects of one or more neighbourhoods. This is the first time that a generic social media platform in this case a QA platform, is used for fine-grained opinion mining. Text coming from QA platforms is far less constrained compared to text from review specific platforms which current datasets are based on. We develop several strong baselines, relying on logistic regression and state-of-the-art recurrent neural networks.