 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Powered Workflow Optimization for Multidisciplinary Software Development: An Automotive Industry Case Study
Mar 22, 2026Multidisciplinary Software Development (MSD) requires domain experts and developers to collaborate across incompatible formalisms and separate artifact sets. Today, even with AI coding assistants like GitHub Copilot, this process remains inefficient; individual coding tasks are semi-automated, but the workflow connecting domain knowledge to implementation is not. Developers and experts still lack a shared view, resulting in repeated coordination, clarification rounds, and error-prone handoffs. We address this gap through a graph-based workflow optimization approach that progressively replaces manual coordination with LLM-powered services, enabling incremental adoption without disrupting established practices. We evaluate our approach on \texttt{spapi}, a production in-vehicle API system at Volvo Group involving 192 endpoints, 420 properties, and 776 CAN signals across six functional domains. The automated workflow achieves 93.7\% F1 score while reducing per-API development time from approximately 5 hours to under 7 minutes, saving an estimated 979 engineering hours. In production, the system received high satisfaction from both domain experts and developers, with all participants reporting full satisfaction with communication efficiency.
Learning Python Code Suggestion with a Sparse Pointer Network
Nov 24, 2016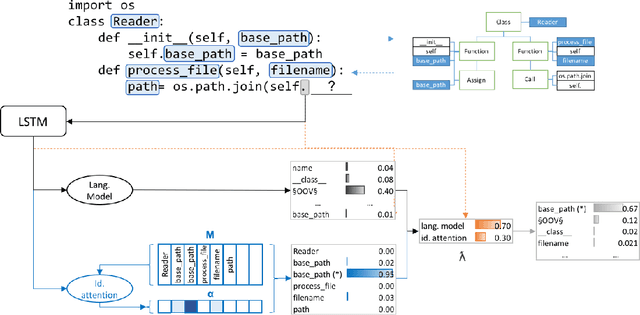
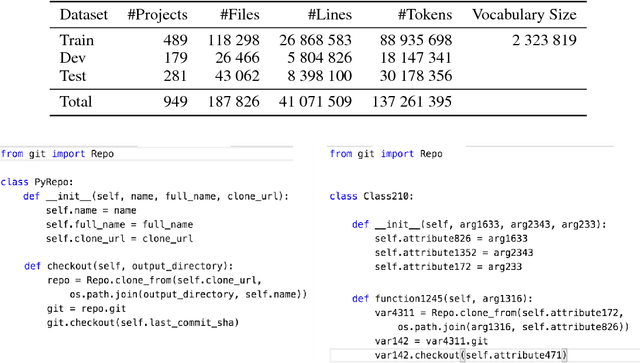
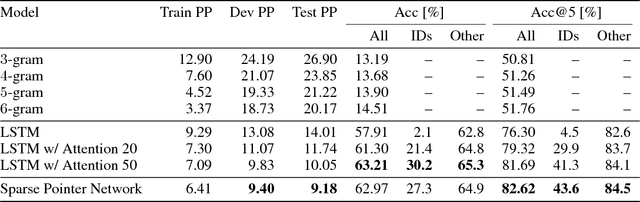
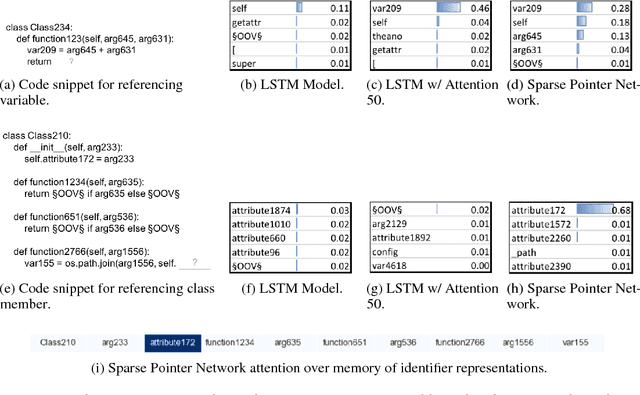
To enhance developer productivity, all modern integrated development environments (IDEs) include code suggestion functionality that proposes likely next tokens at the cursor. While current IDEs work well for statically-typed languages, their reliance on type annotations means that they do not provide the same level of support for dynamic programming languages as for statically-typed languages. Moreover, suggestion engines in modern IDEs do not propose expressions or multi-statement idiomatic code. Recent work has shown that language models can improve code suggestion systems by learning from software repositories. This paper introduces a neural language model with a sparse pointer network aimed at capturing very long-range dependencies. We release a large-scale code suggestion corpus of 41M lines of Python code crawled from GitHub. On this corpus, we found standard neural language models to perform well at suggesting local phenomena, but struggle to refer to identifiers that are introduced many tokens in the past. By augmenting a neural language model with a pointer network specialized in referring to predefined classes of identifiers, we obtain a much lower perplexity and a 5 percentage points increase in accuracy for code suggestion compared to an LSTM baseline. In fact, this increase in code suggestion accuracy is due to a 13 times more accurate prediction of identifiers. Furthermore, a qualitative analysis shows this model indeed captures interesting long-range dependencies, like referring to a class member defined over 60 tokens in the past.