 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinTradeBench: A Financial Reasoning Benchmark for LLMs
Mar 19, 2026Real-world financial decision-making is a challenging problem that requires reasoning over heterogeneous signals, including company fundamentals derived from regulatory filings and trading signals computed from price dynamics. Recently, with the advancement of Large Language Models (LLMs), financial analysts have begun to use them for financial decision-making tasks. However, existing financial question answering benchmarks for testing these models primarily focus on company balance sheet data and rarely evaluate reasoning over how company stocks trade in the market or their interactions with fundamentals. To take advantage of the strengths of both approaches, we introduce FinTradeBench, a benchmark for evaluating financial reasoning that integrates company fundamentals and trading signals. FinTradeBench contains 1,400 questions grounded in NASDAQ-100 companies over a ten-year historical window. The benchmark is organized into three reasoning categories: fundamentals-focused, trading-signal-focused, and hybrid questions requiring cross-signal reasoning. To ensure reliability at scale, we adopt a calibration-then-scaling framework that combines expert seed questions, multi-model response generation, intra-model self-filtering, numerical auditing, and human-LLM judge alignment. We evaluate 14 LLMs under zero-shot prompting and retrieval-augmented settings and witness a clear performance gap. Retrieval substantially improves reasoning over textual fundamentals, but provides limited benefit for trading-signal reasoning. These findings highlight fundamental challenges in the numerical and time-series reasoning for current LLMs and motivate future research in financial intelligence.
Investigating Corporate Social Responsibility Initiatives: Examining the case of corporate Covid-19 response
Feb 05, 2025



In todays age of freely available information, policy makers have to take into account a huge amount of information while making decisions affecting relevant stakeholders. While increase in the amount of information sources and documents increases credibility of decisions based on the corpus of available text, it is challenging for policymakers to make sense of this information. This paper demonstrates how policy makers can implement some of the most popular topic recognition methods, Latent Dirichlet Allocation, Deep Distributed Representation method, text summarization approaches, Word Based Sentence Ranking method and TextRank for sentence extraction method, to sum up the content of large volume of documents to understand the gist of the overload of information. We have applied popular NLP methods to corporate press releases during the early period and advanced period of Covid-19 pandemic which has resulted in a global unprecedented health and socio-economic crisis, when policymaking and regulations have become especially important to standardize corporate practices for employee and social welfare in the face of similar future unseen crises. The steps undertaken in this study can be replicated to yield insights from relevant documents in any other social decision-making context.
An Efficient Convolutional Neural Network for Coronary Heart Disease Prediction
Sep 01, 2019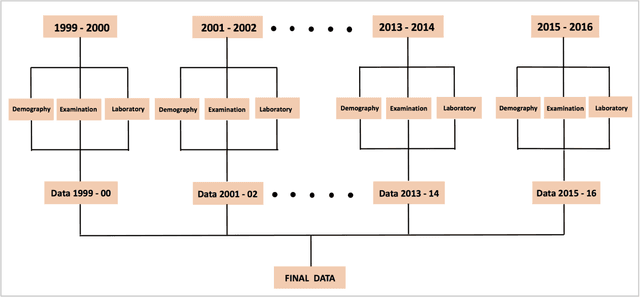
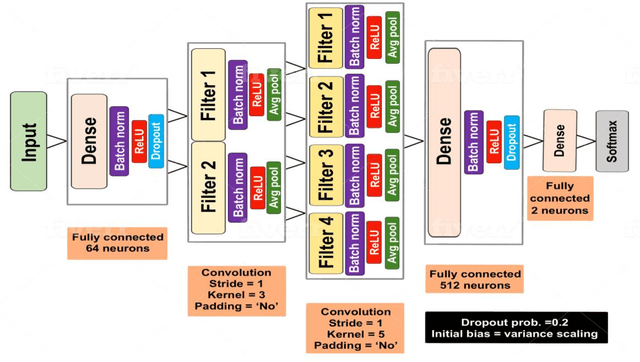
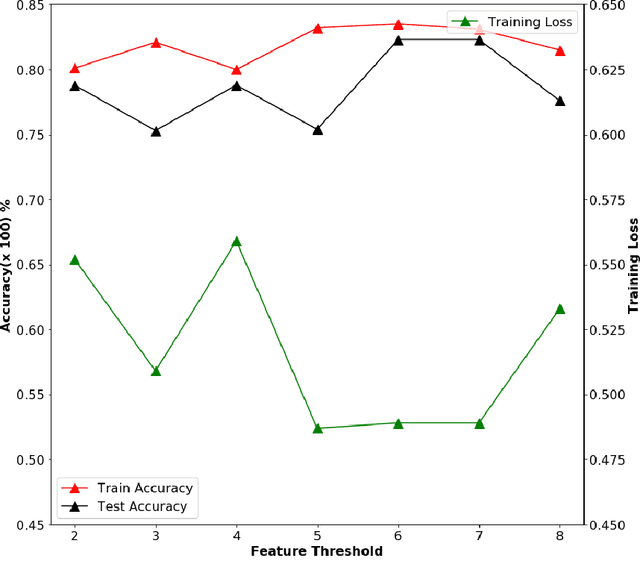
This study proposes an efficient neural network with convolutional layers to classify significantly class-imbalanced clinical data. The data are curated from the National Health and Nutritional Examination Survey (NHANES) with the goal of predicting the occurrence of Coronary Heart Disease (CHD). While the majority of the existing machine learning models that have been used on this class of data are vulnerable to class imbalance even after the adjustment of class-specific weights, our simple two-layer CNN exhibits resilience to the imbalance with fair harmony in class-specific performance. In order to obtain significant improvement in classification accuracy under supervised learning settings, it is a common practice to train a neural network architecture with a massive data and thereafter, test the resulting network on a comparatively smaller amount of data. However, given a highly imbalanced dataset, it is often challenging to achieve a high class 1 (true CHD prediction rate) accuracy as the testing data size increases. We adopt a two-step approach: first, we employ least absolute shrinkage and selection operator (LASSO) based feature weight assessment followed by majority-voting based identification of important features. Next, the important features are homogenized by using a fully connected layer, a crucial step before passing the output of the layer to successive convolutional stages. We also propose a training routine per epoch, akin to a simulated annealing process, to boost the classification accuracy. Despite a 35:1 (Non-CHD:CHD) ratio in the NHANES dataset, the investigation confirms that our proposed CNN architecture has the classification power of 77% to correctly classify the presence of CHD and 81.8% the absence of CHD cases on a testing data, which is 85.70% of the total dataset. ( (<1920 characters)Please check the paper for full abstract)