 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCity-Mesh3R: Simulation-Ready City-Scale 3D Mesh Reconstruction from Multi-View Images
May 28, 2026City-scale 3D surface reconstruction from multiview images for downstream 3D simulation, poses highly challenging problems due to the scale and complexity of urban scenes. Existing city-scale 3D reconstruction methods based on NeRF, Gaussian Splatting etc. often fail to recover 3D meshes ready for simulation due to incomplete/missing geometry and irregular, noisy surfaces. Scaling existing small-scale 3D reconstruction methods to arbitrarily large urban scenes is highly infeasible due to their computational complexity. We present City-Mesh3R, a scalable framework for reconstructing watertight surface meshes directly from large unordered image collections. Unlike recent methods which use global sparse SfM point-cloud initialization followed by a distributed 3D dense reconstruction of large-scale scenes, our method follows an end-to-end images-to-mesh 3D reconstruction approach using a divide-and-conquer strategy. The sparse city map is reconstructed via topological image clustering, cluster-wise independent sparse SfM and map merging, without need for exhaustive image feature matching. Then this map is partitioned spatially to perform geometry-aware camera selection, followed by dense surface reconstruction and surface refinement using curvature-aware adaptive vertex density remeshing. These partition meshes are then stitched together to produce the global mesh of the city. The proposed end-to-end framework is evaluated on city-scale reconstruction datasets. As demonstrated by our qualitative and quantitative results, our proposed method yields high-fidelity watertight 3D meshes with regular geometry, capturing fine surface details, and is suitable for scaling to arbitrarily large scenes owing to the end-to-end processing in a distributed setting.
MPVO: Motion-Prior based Visual Odometry for PointGoal Navigation
Nov 07, 2024



Visual odometry (VO) is essential for enabling accurate point-goal navigation of embodied agents in indoor environments where GPS and compass sensors are unreliable and inaccurate. However, traditional VO methods face challenges in wide-baseline scenarios, where fast robot motions and low frames per second (FPS) during inference hinder their performance, leading to drift and catastrophic failures in point-goal navigation. Recent deep-learned VO methods show robust performance but suffer from sample inefficiency during training; hence, they require huge datasets and compute resources. So, we propose a robust and sample-efficient VO pipeline based on motion priors available while an agent is navigating an environment. It consists of a training-free action-prior based geometric VO module that estimates a coarse relative pose which is further consumed as a motion prior by a deep-learned VO model, which finally produces a fine relative pose to be used by the navigation policy. This strategy helps our pipeline achieve up to 2x sample efficiency during training and demonstrates superior accuracy and robustness in point-goal navigation tasks compared to state-of-the-art VO method(s). Realistic indoor environments of the Gibson dataset is used in the AI-Habitat simulator to evaluate the proposed approach using navigation metrics (like success/SPL) and pose metrics (like RPE/ATE). We hope this method further opens a direction of work where motion priors from various sources can be utilized to improve VO estimates and achieve better results in embodied navigation tasks.
Teledrive: An Embodied AI based Telepresence System
Jun 01, 2024



This article presents Teledrive, a telepresence robotic system with embodied AI features that empowers an operator to navigate the telerobot in any unknown remote place with minimal human intervention. We conceive Teledrive in the context of democratizing remote care-giving for elderly citizens as well as for isolated patients, affected by contagious diseases. In particular, this paper focuses on the problem of navigating to a rough target area (like bedroom or kitchen) rather than pre-specified point destinations. This ushers in a unique AreaGoal based navigation feature, which has not been explored in depth in the contemporary solutions. Further, we describe an edge computing-based software system built on a WebRTC-based communication framework to realize the aforementioned scheme through an easy-to-use speech-based human-robot interaction. Moreover, to enhance the ease of operation for the remote caregiver, we incorporate a person following feature, whereby a robot follows a person on the move in its premises as directed by the operator. Moreover, the system presented is loosely coupled with specific robot hardware, unlike the existing solutions. We have evaluated the efficacy of the proposed system through baseline experiments, user study, and real-life deployment.
* Accepted in Journal of Intelligent Robotic System
DoRO: Disambiguation of referred object for embodied agents
Jul 28, 2022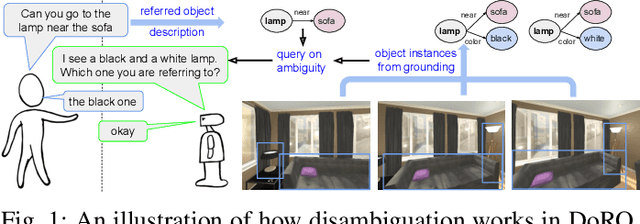
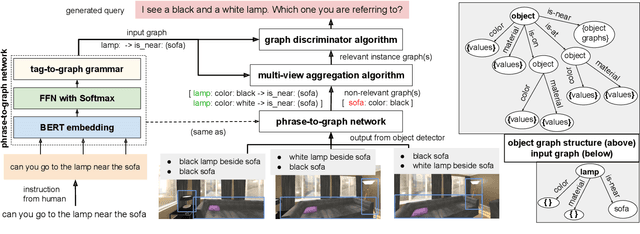
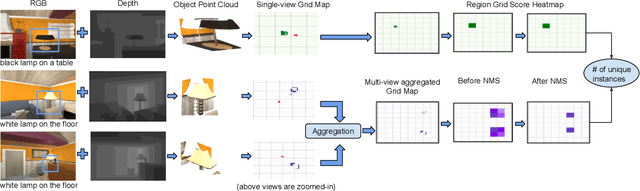
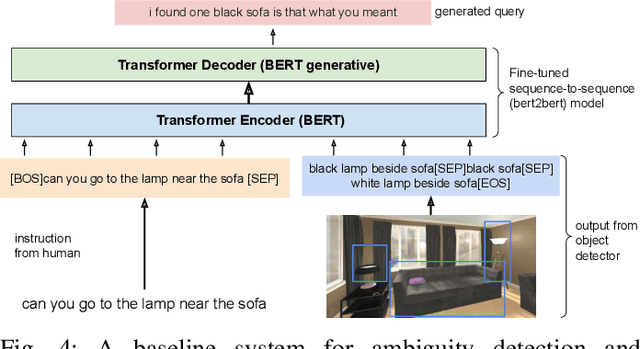
Robotic task instructions often involve a referred object that the robot must locate (ground) within the environment. While task intent understanding is an essential part of natural language understanding, less effort is made to resolve ambiguity that may arise while grounding the task. Existing works use vision-based task grounding and ambiguity detection, suitable for a fixed view and a static robot. However, the problem magnifies for a mobile robot, where the ideal view is not known beforehand. Moreover, a single view may not be sufficient to locate all the object instances in the given area, which leads to inaccurate ambiguity detection. Human intervention is helpful only if the robot can convey the kind of ambiguity it is facing. In this article, we present DoRO (Disambiguation of Referred Object), a system that can help an embodied agent to disambiguate the referred object by raising a suitable query whenever required. Given an area where the intended object is, DoRO finds all the instances of the object by aggregating observations from multiple views while exploring & scanning the area. It then raises a suitable query using the information from the grounded object instances. Experiments conducted with the AI2Thor simulator show that DoRO not only detects the ambiguity more accurately but also raises verbose queries with more accurate information from the visual-language grounding.
MELINDA: A Multimodal Dataset for Biomedical Experiment Method Classification
Dec 16, 2020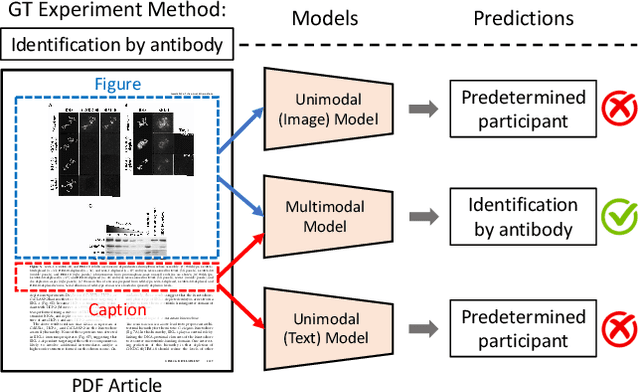
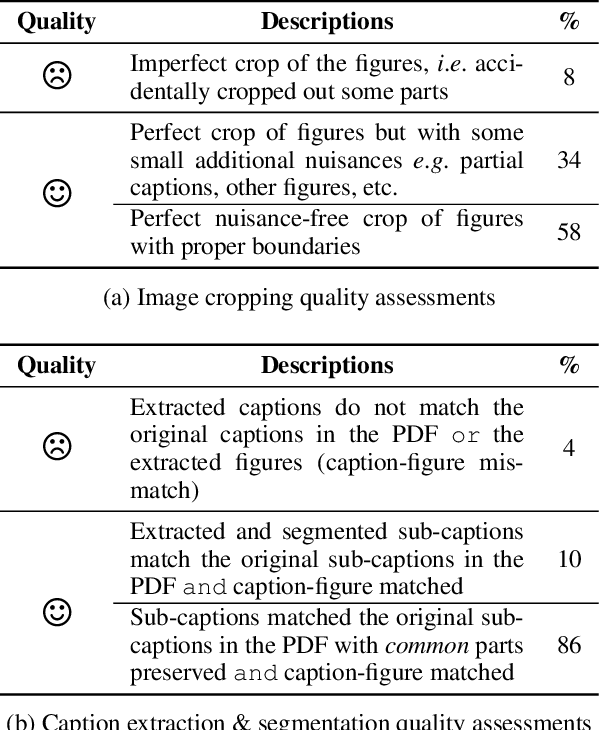
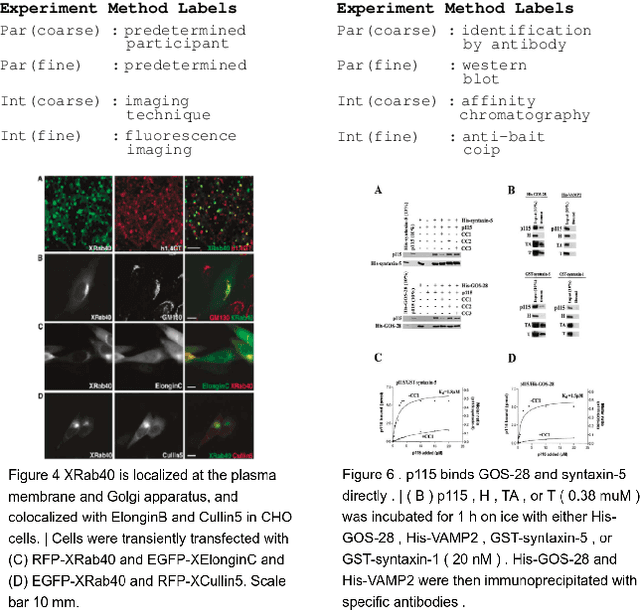
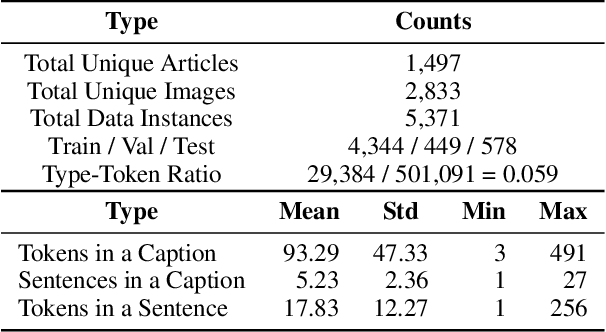
We introduce a new dataset, MELINDA, for Multimodal biomEdicaL experImeNt methoD clAssification. The dataset is collected in a fully automated distant supervision manner, where the labels are obtained from an existing curated database, and the actual contents are extracted from papers associated with each of the records in the database. We benchmark various state-of-the-art NLP and computer vision models, including unimodal models which only take either caption texts or images as inputs, and multimodal models. Extensive experiments and analysis show that multimodal models, despite outperforming unimodal ones, still need improvements especially on a less-supervised way of grounding visual concepts with languages, and better transferability to low resource domains. We release our dataset and the benchmarks to facilitate future research in multimodal learning, especially to motivate targeted improvements for applications in scientific domains.
Demo: Edge-centric Telepresence Avatar Robot for Geographically Distributed Environment
Jul 25, 2020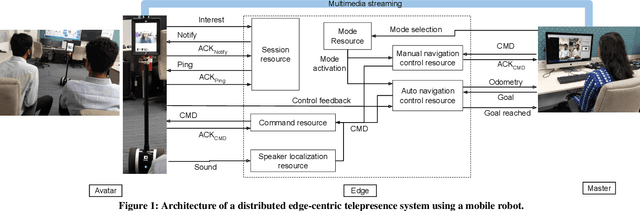
Using a robotic platform for telepresence applications has gained paramount importance in this decade. Scenarios such as remote meetings, group discussions, and presentations/talks in seminars and conferences get much attention in this regard. Though there exist some robotic platforms for such telepresence applications, they lack efficacy in communication and interaction between the remote person and the avatar robot deployed in another geographic location. Also, such existing systems are often cloud-centric which adds to its network overhead woes. In this demo, we develop and test a framework that brings the best of both cloud and edge-centric systems together along with a newly designed communication protocol. Our solution adds to the improvement of the existing systems in terms of robustness and efficacy in communication for a geographically distributed environment.