 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing Roads Through Words: A Language-Guided Framework for RGB-T Driving Scene Segmentation
Feb 07, 2026Robust semantic segmentation of road scenes under adverse illumination, lighting, and shadow conditions remain a core challenge for autonomous driving applications. RGB-Thermal fusion is a standard approach, yet existing methods apply static fusion strategies uniformly across all conditions, allowing modality-specific noise to propagate throughout the network. Hence, we propose CLARITY that dynamically adapts its fusion strategy to the detected scene condition. Guided by vision-language model (VLM) priors, the network learns to modulate each modality's contribution based on the illumination state while leveraging object embeddings for segmentation, rather than applying a fixed fusion policy. We further introduce two mechanisms, i.e., one which preserves valid dark-object semantics that prior noise-suppression methods incorrectly discard, and a hierarchical decoder that enforces structural consistency across scales to sharpen boundaries on thin objects. Experiments on the MFNet dataset demonstrate that CLARITY establishes a new state-of-the-art (SOTA), achieving 62.3% mIoU and 77.5% mAcc.
RAPiD: Real-time Deterministic Trajectory Planning via Diffusion Behavior Priors for Safe and Efficient Autonomous Driving
Feb 07, 2026Diffusion-based trajectory planners have demonstrated strong capability for modeling the multimodal nature of human driving behavior, but their reliance on iterative stochastic sampling poses critical challenges for real-time, safety-critical deployment. In this work, we present RAPiD, a deterministic policy extraction framework that distills a pretrained diffusion-based planner into an efficient policy while eliminating diffusion sampling. Using score-regularized policy optimization, we leverage the score function of a pre-trained diffusion planner as a behavior prior to regularize policy learning. To promote safety and passenger comfort, the policy is optimized using a critic trained to imitate a predictive driver controller, providing dense, safety-focused supervision beyond conventional imitation learning. Evaluations demonstrate that RAPiD achieves competitive performance on closed-loop nuPlan scenarios with an 8x speedup over diffusion baselines, while achieving state-of-the-art generalization among learning-based planners on the interPlan benchmark. The official website of this work is: https://github.com/ruturajreddy/RAPiD.
DexAvatar: 3D Sign Language Reconstruction with Hand and Body Pose Priors
Dec 24, 2025



The trend in sign language generation is centered around data-driven generative methods that require vast amounts of precise 2D and 3D human pose data to achieve an acceptable generation quality. However, currently, most sign language datasets are video-based and limited to automatically reconstructed 2D human poses (i.e., keypoints) and lack accurate 3D information. Furthermore, existing state-of-the-art for automatic 3D human pose estimation from sign language videos is prone to self-occlusion, noise, and motion blur effects, resulting in poor reconstruction quality. In response to this, we introduce DexAvatar, a novel framework to reconstruct bio-mechanically accurate fine-grained hand articulations and body movements from in-the-wild monocular sign language videos, guided by learned 3D hand and body priors. DexAvatar achieves strong performance in the SGNify motion capture dataset, the only benchmark available for this task, reaching an improvement of 35.11% in the estimation of body and hand poses compared to the state-of-the-art. The official website of this work is: https://github.com/kaustesseract/DexAvatar.
MD-BERT: Action Recognition in Dark Videos via Dynamic Multi-Stream Fusion and Temporal Modeling
Feb 06, 2025



Action recognition in dark, low-light (under-exposed) or noisy videos is a challenging task due to visibility degradation, which can hinder critical spatiotemporal details. This paper proposes MD-BERT, a novel multi-stream approach that integrates complementary pre-processing techniques such as gamma correction and histogram equalization alongside raw dark frames to address these challenges. We introduce the Dynamic Feature Fusion (DFF) module, extending existing attentional fusion methods to a three-stream setting, thereby capturing fine-grained and global contextual information across different brightness and contrast enhancements. The fused spatiotemporal features are then processed by a BERT-based temporal model, which leverages its bidirectional self-attention to effectively capture long-range dependencies and contextual relationships across frames. Extensive experiments on the ARID V1.0 and ARID V1.5 dark video datasets show that MD-BERT outperforms existing methods, establishing a new state-of-the-art performance. Ablation studies further highlight the individual contributions of each input stream and the effectiveness of the proposed DFF and BERT modules. The official website of this work is available at: https://github.com/HrishavBakulBarua/DarkBERT
A Cycle Ride to HDR: Semantics Aware Self-Supervised Framework for Unpaired LDR-to-HDR Image Translation
Oct 19, 2024



Low Dynamic Range (LDR) to High Dynamic Range (HDR) image translation is an important computer vision problem. There is a significant amount of research utilizing both conventional non-learning methods and modern data-driven approaches, focusing on using both single-exposed and multi-exposed LDR for HDR image reconstruction. However, most current state-of-the-art methods require high-quality paired {LDR,HDR} datasets for model training. In addition, there is limited literature on using unpaired datasets for this task where the model learns a mapping between domains, i.e., LDR to HDR. To address limitations of current methods, such as the paired data constraint , as well as unwanted blurring and visual artifacts in the reconstructed HDR, we propose a method that uses a modified cycle-consistent adversarial architecture and utilizes unpaired {LDR,HDR} datasets for training. The method introduces novel generators to address visual artifact removal and an encoder and loss to address semantic consistency, another under-explored topic. The method achieves state-of-the-art results across several benchmark datasets and reconstructs high-quality HDR images.
ActNetFormer: Transformer-ResNet Hybrid Method for Semi-Supervised Action Recognition in Videos
Apr 09, 2024



Human action or activity recognition in videos is a fundamental task in computer vision with applications in surveillance and monitoring, self-driving cars, sports analytics, human-robot interaction and many more. Traditional supervised methods require large annotated datasets for training, which are expensive and time-consuming to acquire. This work proposes a novel approach using Cross-Architecture Pseudo-Labeling with contrastive learning for semi-supervised action recognition. Our framework leverages both labeled and unlabelled data to robustly learn action representations in videos, combining pseudo-labeling with contrastive learning for effective learning from both types of samples. We introduce a novel cross-architecture approach where 3D Convolutional Neural Networks (3D CNNs) and video transformers (VIT) are utilised to capture different aspects of action representations; hence we call it ActNetFormer. The 3D CNNs excel at capturing spatial features and local dependencies in the temporal domain, while VIT excels at capturing long-range dependencies across frames. By integrating these complementary architectures within the ActNetFormer framework, our approach can effectively capture both local and global contextual information of an action. This comprehensive representation learning enables the model to achieve better performance in semi-supervised action recognition tasks by leveraging the strengths of each of these architectures. Experimental results on standard action recognition datasets demonstrate that our approach performs better than the existing methods, achieving state-of-the-art performance with only a fraction of labeled data. The official website of this work is available at: https://github.com/rana2149/ActNetFormer.
GTA-HDR: A Large-Scale Synthetic Dataset for HDR Image Reconstruction
Mar 26, 2024



High Dynamic Range (HDR) content (i.e., images and videos) has a broad range of applications. However, capturing HDR content from real-world scenes is expensive and time-consuming. Therefore, the challenging task of reconstructing visually accurate HDR images from their Low Dynamic Range (LDR) counterparts is gaining attention in the vision research community. A major challenge in this research problem is the lack of datasets, which capture diverse scene conditions (e.g., lighting, shadows, weather, locations, landscapes, objects, humans, buildings) and various image features (e.g., color, contrast, saturation, hue, luminance, brightness, radiance). To address this gap, in this paper, we introduce GTA-HDR, a large-scale synthetic dataset of photo-realistic HDR images sampled from the GTA-V video game. We perform thorough evaluation of the proposed dataset, which demonstrates significant qualitative and quantitative improvements of the state-of-the-art HDR image reconstruction methods. Furthermore, we demonstrate the effectiveness of the proposed dataset and its impact on additional computer vision tasks including 3D human pose estimation, human body part segmentation, and holistic scene segmentation. The dataset, data collection pipeline, and evaluation code are available at: https://github.com/HrishavBakulBarua/GTA-HDR.
HistoHDR-Net: Histogram Equalization for Single LDR to HDR Image Translation
Feb 08, 2024



High Dynamic Range (HDR) imaging aims to replicate the high visual quality and clarity of real-world scenes. Due to the high costs associated with HDR imaging, the literature offers various data-driven methods for HDR image reconstruction from Low Dynamic Range (LDR) counterparts. A common limitation of these approaches is missing details in regions of the reconstructed HDR images, which are over- or under-exposed in the input LDR images. To this end, we propose a simple and effective method, HistoHDR-Net, to recover the fine details (e.g., color, contrast, saturation, and brightness) of HDR images via a fusion-based approach utilizing histogram-equalized LDR images along with self-attention guidance. Our experiments demonstrate the efficacy of the proposed approach over the state-of-art methods.
ArtHDR-Net: Perceptually Realistic and Accurate HDR Content Creation
Sep 07, 2023



High Dynamic Range (HDR) content creation has become an important topic for modern media and entertainment sectors, gaming and Augmented/Virtual Reality industries. Many methods have been proposed to recreate the HDR counterparts of input Low Dynamic Range (LDR) images/videos given a single exposure or multi-exposure LDRs. The state-of-the-art methods focus primarily on the preservation of the reconstruction's structural similarity and the pixel-wise accuracy. However, these conventional approaches do not emphasize preserving the artistic intent of the images in terms of human visual perception, which is an essential element in media, entertainment and gaming. In this paper, we attempt to study and fill this gap. We propose an architecture called ArtHDR-Net based on a Convolutional Neural Network that uses multi-exposed LDR features as input. Experimental results show that ArtHDR-Net can achieve state-of-the-art performance in terms of the HDR-VDP-2 score (i.e., mean opinion score index) while reaching competitive performance in terms of PSNR and SSIM.
Computational Solar Energy -- Ensemble Learning Methods for Prediction of Solar Power Generation based on Meteorological Parameters in Eastern India
Jan 21, 2023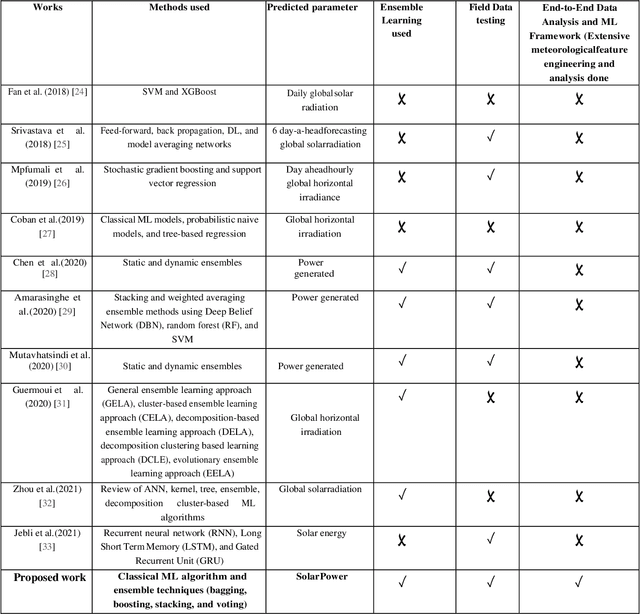



The challenges in applications of solar energy lies in its intermittency and dependency on meteorological parameters such as; solar radiation, ambient temperature, rainfall, wind-speed etc., and many other physical parameters like dust accumulation etc. Hence, it is important to estimate the amount of solar photovoltaic (PV) power generation for a specific geographical location. Machine learning (ML) models have gained importance and are widely used for prediction of solar power plant performance. In this paper, the impact of weather parameters on solar PV power generation is estimated by several Ensemble ML (EML) models like Bagging, Boosting, Stacking, and Voting for the first time. The performance of chosen ML algorithms is validated by field dataset of a 10kWp solar PV power plant in Eastern India region. Furthermore, a complete test-bed framework has been designed for data mining as well as to select appropriate learning models. It also supports feature selection and reduction for dataset to reduce space and time complexity of the learning models. The results demonstrate greater prediction accuracy of around 96% for Stacking and Voting EML models. The proposed work is a generalized one and can be very useful for predicting the performance of large-scale solar PV power plants also.