 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefine and Imitate: Reducing Repetition and Inconsistency in Persuasion Dialogues via Reinforcement Learning and Human Demonstration
Dec 31, 2020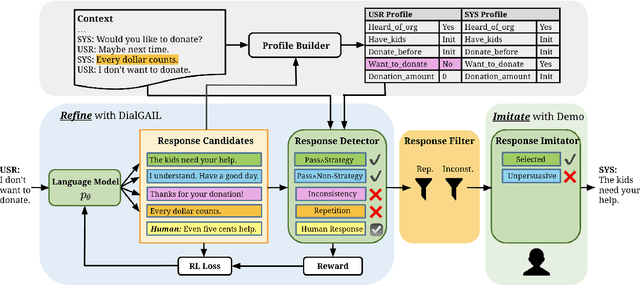
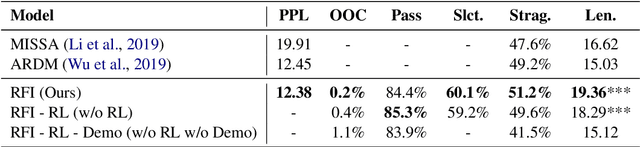
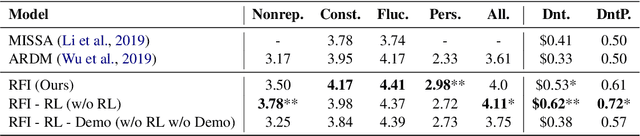
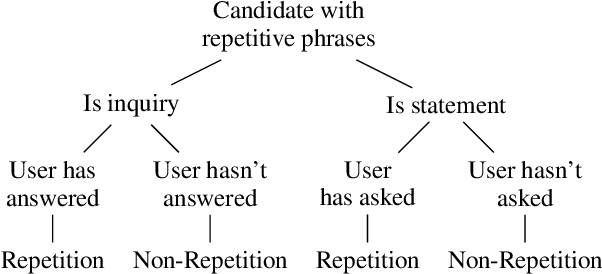
Despite the recent success of large-scale language models on various downstream NLP tasks, the repetition and inconsistency problems still persist in dialogue response generation. Previous approaches have attempted to avoid repetition by penalizing the language model's undesirable behaviors in the loss function. However, these methods focus on token-level information and can lead to incoherent responses and uninterpretable behaviors. To alleviate these issues, we propose to apply reinforcement learning to refine an MLE-based language model without user simulators, and distill sentence-level information about repetition, inconsistency and task relevance through rewards. In addition, to better accomplish the dialogue task, the model learns from human demonstration to imitate intellectual activities such as persuasion, and selects the most persuasive responses. Experiments show that our model outperforms previous state-of-the-art dialogue models on both automatic metrics and human evaluation results on a donation persuasion task, and generates more diverse, consistent and persuasive conversations according to the user feedback.
Audio-Visual Understanding of Passenger Intents for In-Cabin Conversational Agents
Jul 08, 2020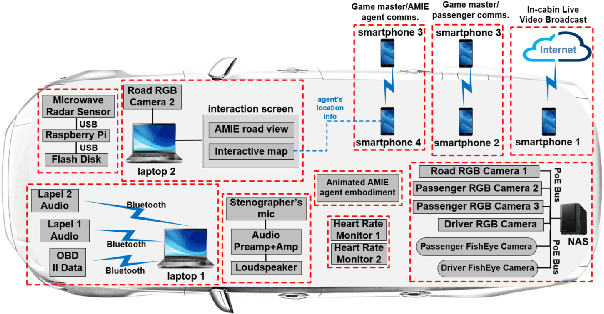

Building multimodal dialogue understanding capabilities situated in the in-cabin context is crucial to enhance passenger comfort in autonomous vehicle (AV) interaction systems. To this end, understanding passenger intents from spoken interactions and vehicle vision systems is a crucial component for developing contextual and visually grounded conversational agents for AV. Towards this goal, we explore AMIE (Automated-vehicle Multimodal In-cabin Experience), the in-cabin agent responsible for handling multimodal passenger-vehicle interactions. In this work, we discuss the benefits of a multimodal understanding of in-cabin utterances by incorporating verbal/language input together with the non-verbal/acoustic and visual clues from inside and outside the vehicle. Our experimental results outperformed text-only baselines as we achieved improved performances for intent detection with a multimodal approach.
Low Rank Fusion based Transformers for Multimodal Sequences
Jul 04, 2020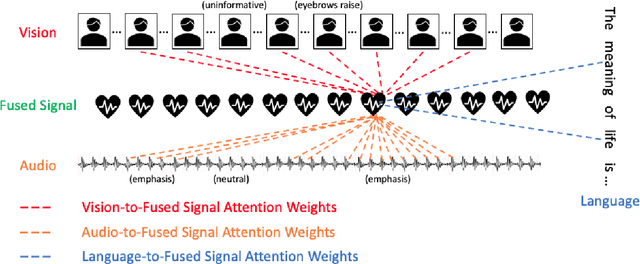
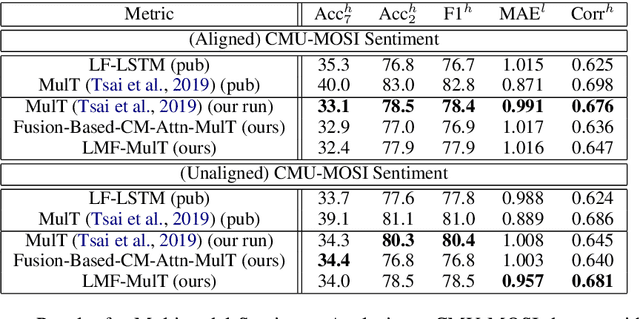
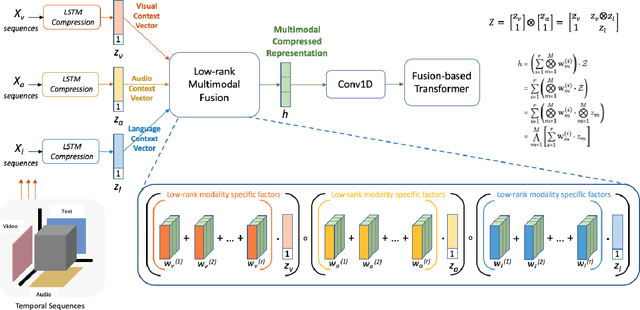
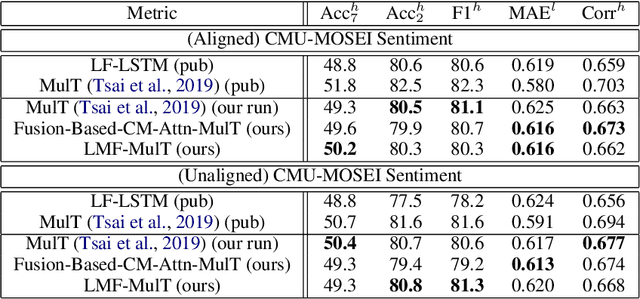
Our senses individually work in a coordinated fashion to express our emotional intentions. In this work, we experiment with modeling modality-specific sensory signals to attend to our latent multimodal emotional intentions and vice versa expressed via low-rank multimodal fusion and multimodal transformers. The low-rank factorization of multimodal fusion amongst the modalities helps represent approximate multiplicative latent signal interactions. Motivated by the work of~\cite{tsai2019MULT} and~\cite{Liu_2018}, we present our transformer-based cross-fusion architecture without any over-parameterization of the model. The low-rank fusion helps represent the latent signal interactions while the modality-specific attention helps focus on relevant parts of the signal. We present two methods for the Multimodal Sentiment and Emotion Recognition results on CMU-MOSEI, CMU-MOSI, and IEMOCAP datasets and show that our models have lesser parameters, train faster and perform comparably to many larger fusion-based architectures.
Exploring Context, Attention and Audio Features for Audio Visual Scene-Aware Dialog
Dec 20, 2019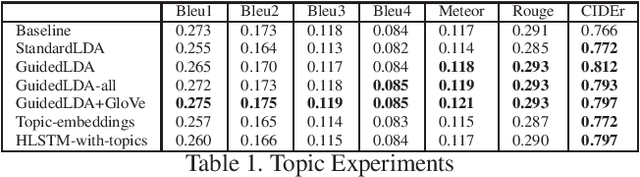
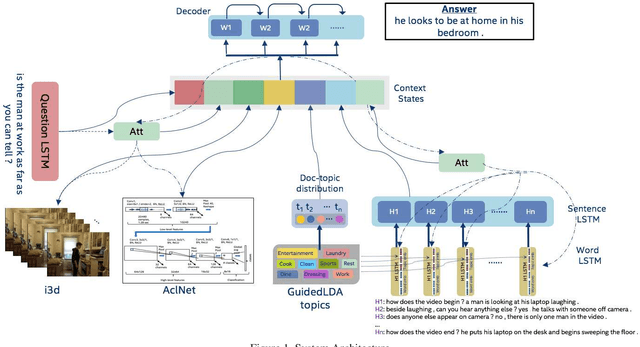
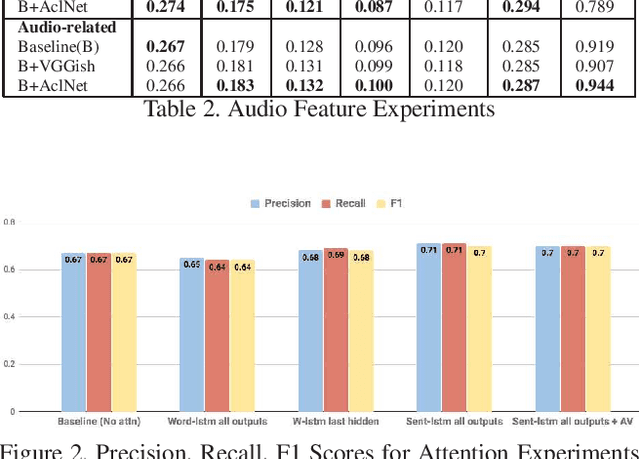
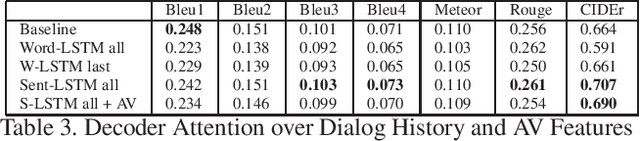
We are witnessing a confluence of vision, speech and dialog system technologies that are enabling the IVAs to learn audio-visual groundings of utterances and have conversations with users about the objects, activities and events surrounding them. Recent progress in visual grounding techniques and Audio Understanding are enabling machines to understand shared semantic concepts and listen to the various sensory events in the environment. With audio and visual grounding methods, end-to-end multimodal SDS are trained to meaningfully communicate with us in natural language about the real dynamic audio-visual sensory world around us. In this work, we explore the role of `topics' as the context of the conversation along with multimodal attention into such an end-to-end audio-visual scene-aware dialog system architecture. We also incorporate an end-to-end audio classification ConvNet, AclNet, into our models. We develop and test our approaches on the Audio Visual Scene-Aware Dialog (AVSD) dataset released as a part of the DSTC7. We present the analysis of our experiments and show that some of our model variations outperform the baseline system released for AVSD.
Leveraging Topics and Audio Features with Multimodal Attention for Audio Visual Scene-Aware Dialog
Dec 20, 2019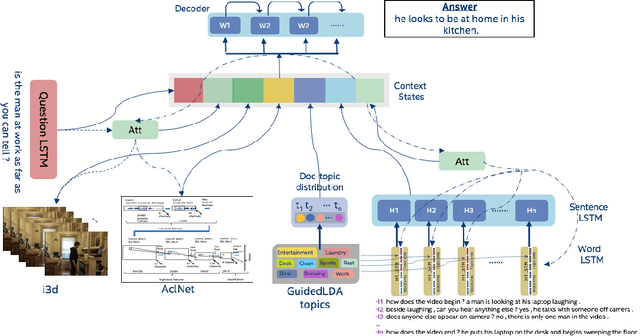

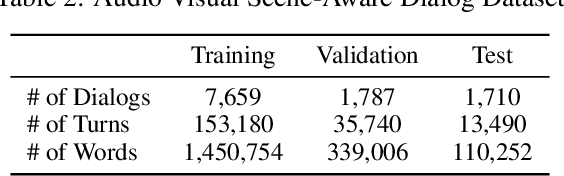
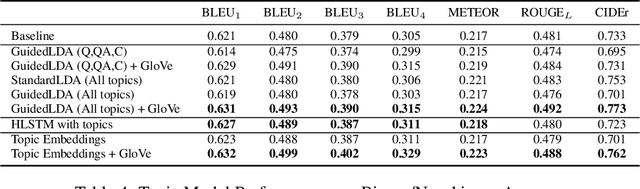
With the recent advancements in Artificial Intelligence (AI), Intelligent Virtual Assistants (IVA) such as Alexa, Google Home, etc., have become a ubiquitous part of many homes. Currently, such IVAs are mostly audio-based, but going forward, we are witnessing a confluence of vision, speech and dialog system technologies that are enabling the IVAs to learn audio-visual groundings of utterances. This will enable agents to have conversations with users about the objects, activities and events surrounding them. In this work, we present three main architectural explorations for the Audio Visual Scene-Aware Dialog (AVSD): 1) investigating `topics' of the dialog as an important contextual feature for the conversation, 2) exploring several multimodal attention mechanisms during response generation, 3) incorporating an end-to-end audio classification ConvNet, AclNet, into our architecture. We discuss detailed analysis of the experimental results and show that our model variations outperform the baseline system presented for the AVSD task.
Modeling Intent, Dialog Policies and Response Adaptation for Goal-Oriented Interactions
Dec 20, 2019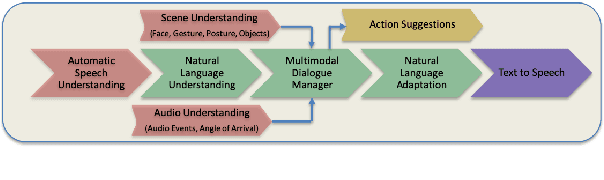
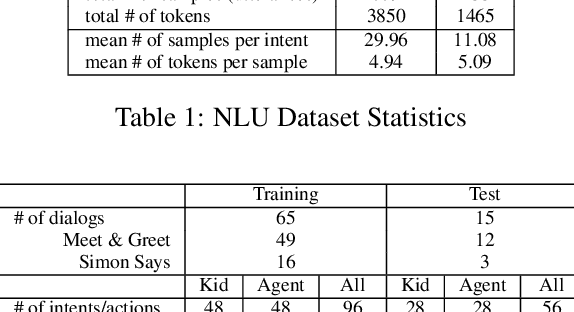
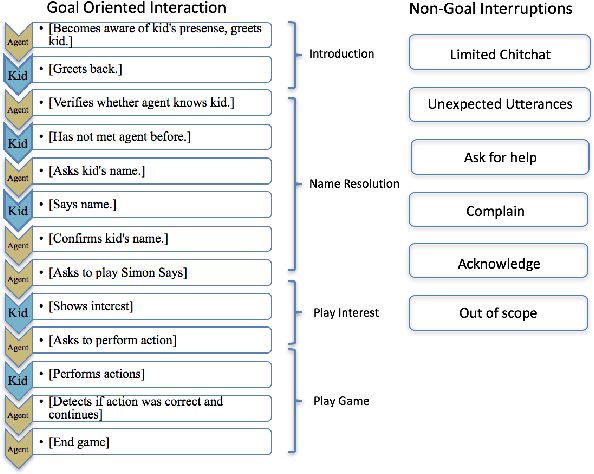
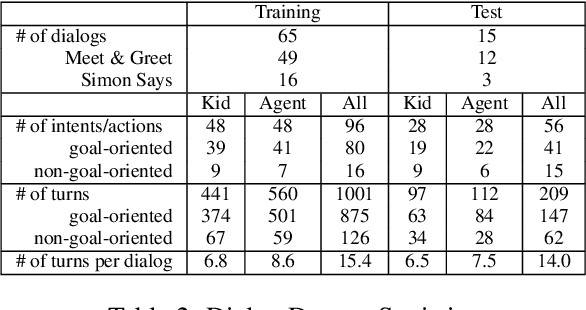
Building a machine learning driven spoken dialog system for goal-oriented interactions involves careful design of intents and data collection along with development of intent recognition models and dialog policy learning algorithms. The models should be robust enough to handle various user distractions during the interaction flow and should steer the user back into an engaging interaction for successful completion of the interaction. In this work, we have designed a goal-oriented interaction system where children can engage with agents for a series of interactions involving `Meet \& Greet' and `Simon Says' game play. We have explored various feature extractors and models for improved intent recognition and looked at leveraging previous user and system interactions in novel ways with attention models. We have also looked at dialog adaptation methods for entrained response selection. Our bootstrapped models from limited training data perform better than many baseline approaches we have looked at for intent recognition and dialog action prediction.
* Presented as a full-paper at the 23rd Workshop on the Semantics and Pragmatics of Dialogue (SemDial 2019 - LondonLogue), Sep 4-6, 2019, London, UK
Towards Multimodal Understanding of Passenger-Vehicle Interactions in Autonomous Vehicles: Intent/Slot Recognition Utilizing Audio-Visual Data
Sep 20, 2019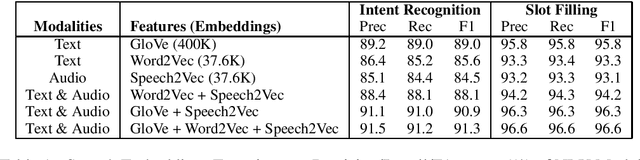

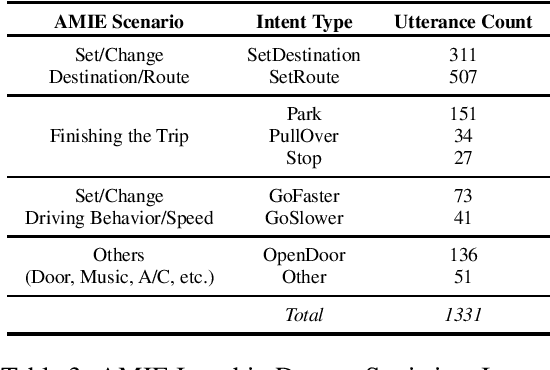
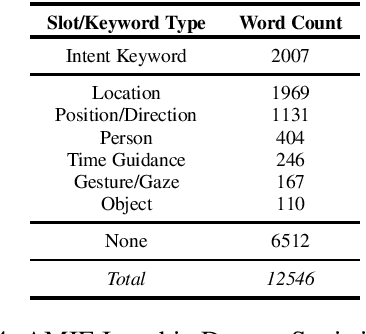
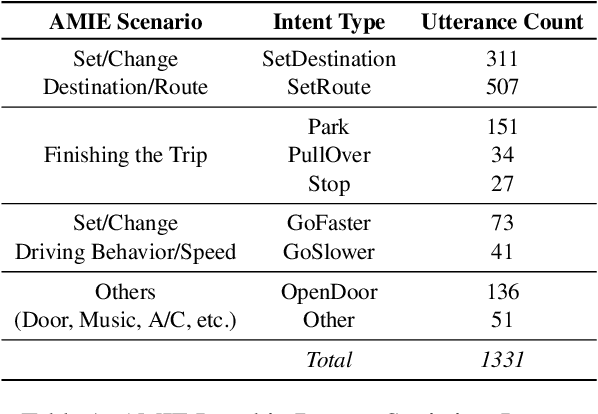
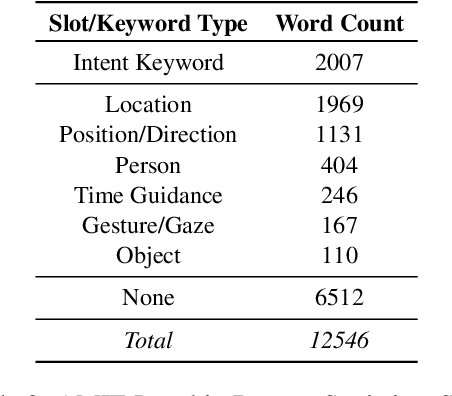
Understanding passenger intents from spoken interactions and car's vision (both inside and outside the vehicle) are important building blocks towards developing contextual dialog systems for natural interactions in autonomous vehicles (AV). In this study, we continued exploring AMIE (Automated-vehicle Multimodal In-cabin Experience), the in-cabin agent responsible for handling certain multimodal passenger-vehicle interactions. When the passengers give instructions to AMIE, the agent should parse such commands properly considering available three modalities (language/text, audio, video) and trigger the appropriate functionality of the AV system. We had collected a multimodal in-cabin dataset with multi-turn dialogues between the passengers and AMIE using a Wizard-of-Oz scheme via realistic scavenger hunt game. In our previous explorations, we experimented with various RNN-based models to detect utterance-level intents (set destination, change route, go faster, go slower, stop, park, pull over, drop off, open door, and others) along with intent keywords and relevant slots (location, position/direction, object, gesture/gaze, time-guidance, person) associated with the action to be performed in our AV scenarios. In this recent work, we propose to discuss the benefits of multimodal understanding of in-cabin utterances by incorporating verbal/language input (text and speech embeddings) together with the non-verbal/acoustic and visual input from inside and outside the vehicle (i.e., passenger gestures and gaze from in-cabin video stream, referred objects outside of the vehicle from the road view camera stream). Our experimental results outperformed text-only baselines and with multimodality, we achieved improved performances for utterance-level intent detection and slot filling.
* Presented as a short-paper at the 23rd Workshop on the Semantics and Pragmatics of Dialogue (SemDial 2019 - LondonLogue), Sep 4-6, 2019, London, UK
Natural Language Interactions in Autonomous Vehicles: Intent Detection and Slot Filling from Passenger Utterances
Apr 23, 2019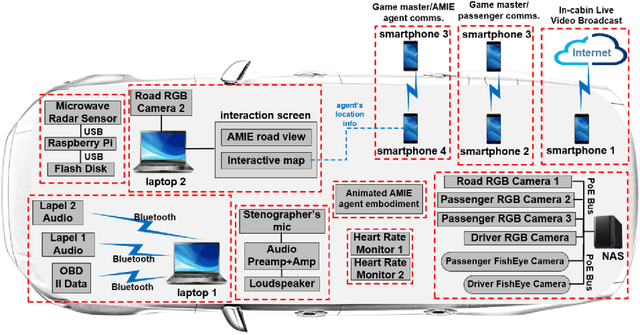
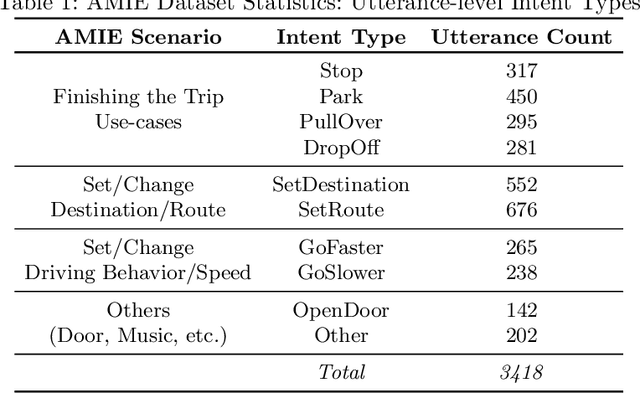

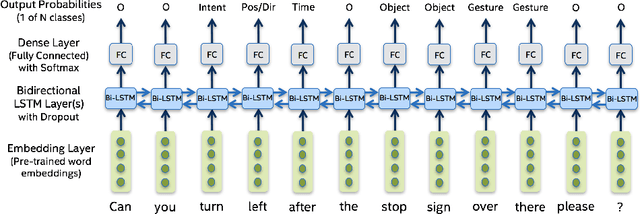
Understanding passenger intents and extracting relevant slots are important building blocks towards developing contextual dialogue systems for natural interactions in autonomous vehicles (AV). In this work, we explored AMIE (Automated-vehicle Multi-modal In-cabin Experience), the in-cabin agent responsible for handling certain passenger-vehicle interactions. When the passengers give instructions to AMIE, the agent should parse such commands properly and trigger the appropriate functionality of the AV system. In our current explorations, we focused on AMIE scenarios describing usages around setting or changing the destination and route, updating driving behavior or speed, finishing the trip and other use-cases to support various natural commands. We collected a multi-modal in-cabin dataset with multi-turn dialogues between the passengers and AMIE using a Wizard-of-Oz scheme via a realistic scavenger hunt game activity. After exploring various recent Recurrent Neural Networks (RNN) based techniques, we introduced our own hierarchical joint models to recognize passenger intents along with relevant slots associated with the action to be performed in AV scenarios. Our experimental results outperformed certain competitive baselines and achieved overall F1 scores of 0.91 for utterance-level intent detection and 0.96 for slot filling tasks. In addition, we conducted initial speech-to-text explorations by comparing intent/slot models trained and tested on human transcriptions versus noisy Automatic Speech Recognition (ASR) outputs. Finally, we compared the results with single passenger rides versus the rides with multiple passengers.
* Accepted and presented as a full paper at 20th International Conference on Computational Linguistics and Intelligent Text Processing (CICLing 2019), April 7-13, 2019, La Rochelle, France
Context, Attention and Audio Feature Explorations for Audio Visual Scene-Aware Dialog
Dec 20, 2018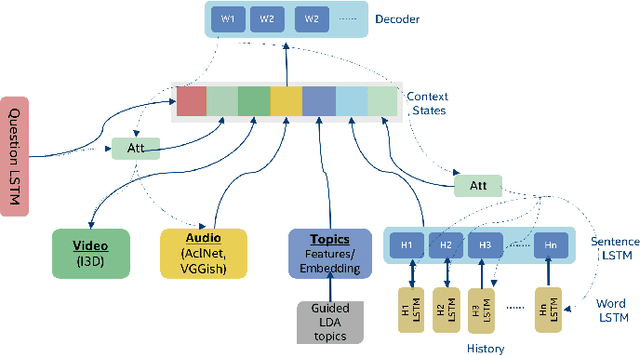

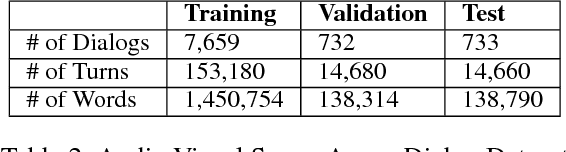
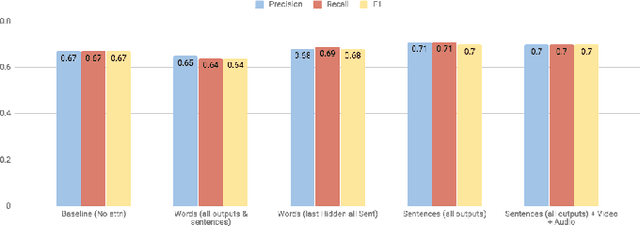
With the recent advancements in AI, Intelligent Virtual Assistants (IVA) have become a ubiquitous part of every home. Going forward, we are witnessing a confluence of vision, speech and dialog system technologies that are enabling the IVAs to learn audio-visual groundings of utterances and have conversations with users about the objects, activities and events surrounding them. As a part of the 7th Dialog System Technology Challenges (DSTC7), for Audio Visual Scene-Aware Dialog (AVSD) track, We explore `topics' of the dialog as an important contextual feature into the architecture along with explorations around multimodal Attention. We also incorporate an end-to-end audio classification ConvNet, AclNet, into our models. We present detailed analysis of the experiments and show that some of our model variations outperform the baseline system presented for this task.
Conversational Intent Understanding for Passengers in Autonomous Vehicles
Dec 14, 2018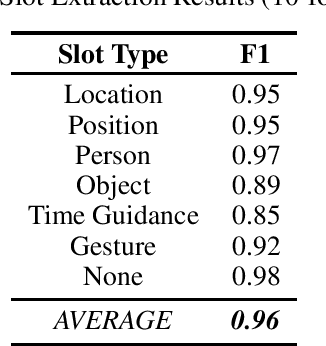
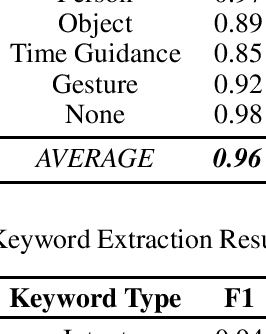


Understanding passenger intents and extracting relevant slots are important building blocks towards developing a contextual dialogue system responsible for handling certain vehicle-passenger interactions in autonomous vehicles (AV). When the passengers give instructions to AMIE (Automated-vehicle Multimodal In-cabin Experience), the agent should parse such commands properly and trigger the appropriate functionality of the AV system. In our AMIE scenarios, we describe usages and support various natural commands for interacting with the vehicle. We collected a multimodal in-cabin data-set with multi-turn dialogues between the passengers and AMIE using a Wizard-of-Oz scheme. We explored various recent Recurrent Neural Networks (RNN) based techniques and built our own hierarchical models to recognize passenger intents along with relevant slots associated with the action to be performed in AV scenarios. Our experimental results achieved F1-score of 0.91 on utterance-level intent recognition and 0.96 on slot extraction models.