 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext, Attention and Audio Feature Explorations for Audio Visual Scene-Aware Dialog
Dec 20, 2018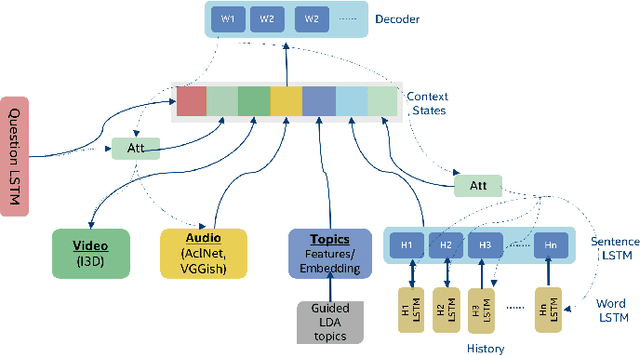

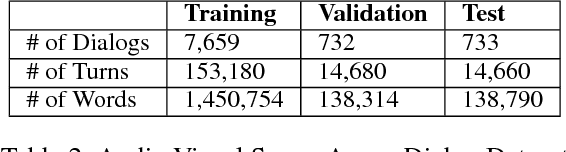
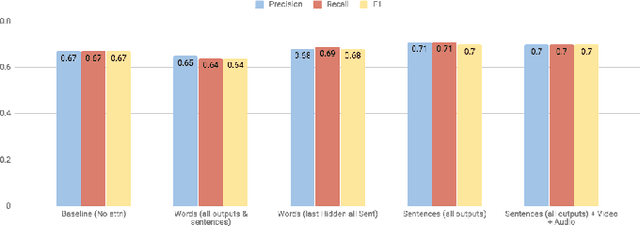
With the recent advancements in AI, Intelligent Virtual Assistants (IVA) have become a ubiquitous part of every home. Going forward, we are witnessing a confluence of vision, speech and dialog system technologies that are enabling the IVAs to learn audio-visual groundings of utterances and have conversations with users about the objects, activities and events surrounding them. As a part of the 7th Dialog System Technology Challenges (DSTC7), for Audio Visual Scene-Aware Dialog (AVSD) track, We explore `topics' of the dialog as an important contextual feature into the architecture along with explorations around multimodal Attention. We also incorporate an end-to-end audio classification ConvNet, AclNet, into our models. We present detailed analysis of the experiments and show that some of our model variations outperform the baseline system presented for this task.
AclNet: efficient end-to-end audio classification CNN
Nov 16, 2018
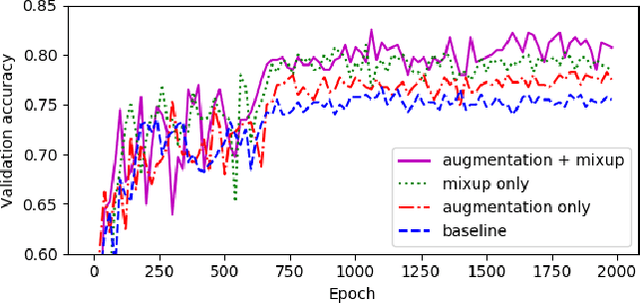
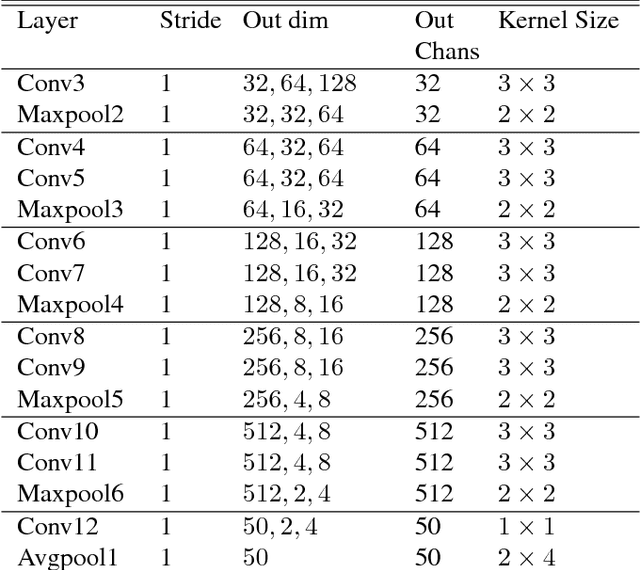
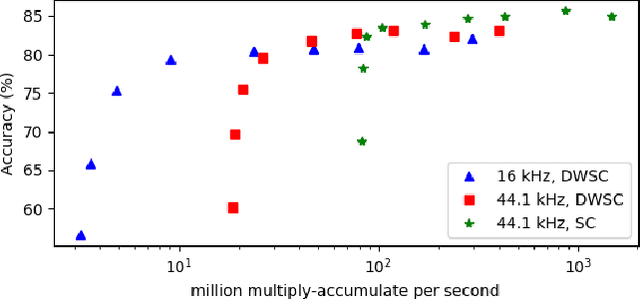
We propose an efficient end-to-end convolutional neural network architecture, AclNet, for audio classification. When trained with our data augmentation and regularization, we achieved state-of-the-art performance on the ESC-50 corpus with 85:65% accuracy. Our network allows configurations such that memory and compute requirements are drastically reduced, and a tradeoff analysis of accuracy and complexity is presented. The analysis shows high accuracy at significantly reduced computational complexity compared to existing solutions. For example, a configuration with only 155k parameters and 49:3 million multiply-adds per second is 81:75%, exceeding human accuracy of 81:3%. This improved efficiency can enable always-on inference in energy-efficient platforms.