 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Adaptation Under MNAR Missingness
Apr 01, 2025



Current domain adaptation methods under missingness shift are restricted to Missing At Random (MAR) missingness mechanisms. However, in many real-world examples, the MAR assumption may be too restrictive. When covariates are Missing Not At Random (MNAR) in both source and target data, the common covariate shift solutions, including importance weighting, are not directly applicable. We show that under reasonable assumptions, the problem of MNAR missingness shift can be reduced to an imputation problem. This allows us to leverage recent methodological developments in both the traditional statistics and machine/deep-learning literature for MNAR imputation to develop a novel domain adaptation procedure for MNAR missingness shift. We further show that our proposed procedure can be extended to handle simultaneous MNAR missingness and covariate shifts. We apply our procedure to Electronic Health Record (EHR) data from two hospitals in south and northeast regions of the US. In this setting we expect different hospital networks and regions to serve different populations and to have different procedures, practices, and software for inputting and recording data, causing simultaneous missingness and covariate shifts.
Finding Regions of Heterogeneity in Decision-Making via Expected Conditional Covariance
Oct 27, 2021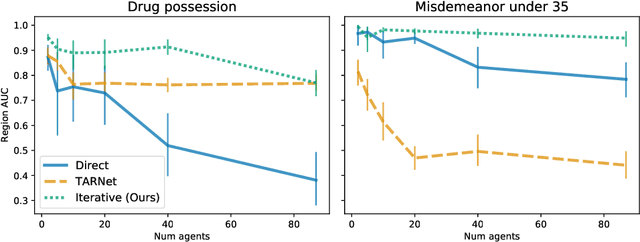
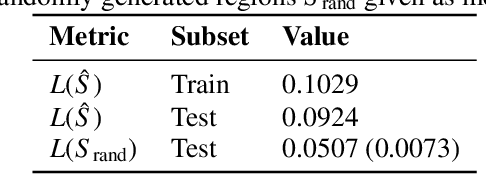
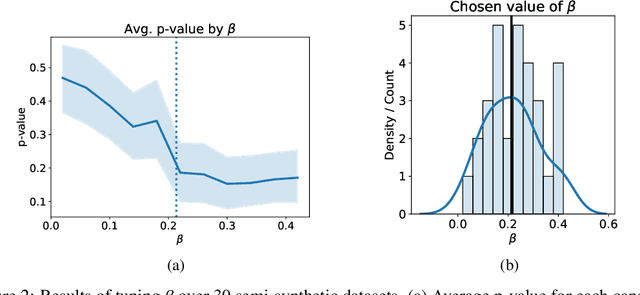

Individuals often make different decisions when faced with the same context, due to personal preferences and background. For instance, judges may vary in their leniency towards certain drug-related offenses, and doctors may vary in their preference for how to start treatment for certain types of patients. With these examples in mind, we present an algorithm for identifying types of contexts (e.g., types of cases or patients) with high inter-decision-maker disagreement. We formalize this as a causal inference problem, seeking a region where the assignment of decision-maker has a large causal effect on the decision. Our algorithm finds such a region by maximizing an empirical objective, and we give a generalization bound for its performance. In a semi-synthetic experiment, we show that our algorithm recovers the correct region of heterogeneity accurately compared to baselines. Finally, we apply our algorithm to real-world healthcare datasets, recovering variation that aligns with existing clinical knowledge.