 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Network-based Partial-Linear Single-Index Models for Environmental Mixtures Analysis
Dec 12, 2025Evaluating the health effects of complex environmental mixtures remains a central challenge in environmental health research. Existing approaches vary in their flexibility, interpretability, scalability, and support for diverse outcome types, often limiting their utility in real-world applications. To address these limitations, we propose a neural network-based partial-linear single-index (NeuralPLSI) modeling framework that bridges semiparametric regression modeling interpretability with the expressive power of deep learning. The NeuralPLSI model constructs an interpretable exposure index via a learnable projection and models its relationship with the outcome through a flexible neural network. The framework accommodates continuous, binary, and time-to-event outcomes, and supports inference through a bootstrap-based procedure that yields confidence intervals for key model parameters. We evaluated NeuralPLSI through simulation studies under a range of scenarios and applied it to data from the National Health and Nutrition Examination Survey (NHANES) to demonstrate its practical utility. Together, our contributions establish NeuralPLSI as a scalable, interpretable, and versatile modeling tool for mixture analysis. To promote adoption and reproducibility, we release a user-friendly open-source software package that implements the proposed methodology and supports downstream visualization and inference (\texttt{https://github.com/hyungrok-do/NeuralPLSI}).
Domain Adaptation Under MNAR Missingness
Apr 01, 2025



Current domain adaptation methods under missingness shift are restricted to Missing At Random (MAR) missingness mechanisms. However, in many real-world examples, the MAR assumption may be too restrictive. When covariates are Missing Not At Random (MNAR) in both source and target data, the common covariate shift solutions, including importance weighting, are not directly applicable. We show that under reasonable assumptions, the problem of MNAR missingness shift can be reduced to an imputation problem. This allows us to leverage recent methodological developments in both the traditional statistics and machine/deep-learning literature for MNAR imputation to develop a novel domain adaptation procedure for MNAR missingness shift. We further show that our proposed procedure can be extended to handle simultaneous MNAR missingness and covariate shifts. We apply our procedure to Electronic Health Record (EHR) data from two hospitals in south and northeast regions of the US. In this setting we expect different hospital networks and regions to serve different populations and to have different procedures, practices, and software for inputting and recording data, causing simultaneous missingness and covariate shifts.
Learning Representation for Multitask learning through Self Supervised Auxiliary learning
Sep 25, 2024



Multi-task learning is a popular machine learning approach that enables simultaneous learning of multiple related tasks, improving algorithmic efficiency and effectiveness. In the hard parameter sharing approach, an encoder shared through multiple tasks generates data representations passed to task-specific predictors. Therefore, it is crucial to have a shared encoder that provides decent representations for every and each task. However, despite recent advances in multi-task learning, the question of how to improve the quality of representations generated by the shared encoder remains open. To address this gap, we propose a novel approach called Dummy Gradient norm Regularization that aims to improve the universality of the representations generated by the shared encoder. Specifically, the method decreases the norm of the gradient of the loss function with repect to dummy task-specific predictors to improve the universality of the shared encoder's representations. Through experiments on multiple multi-task learning benchmark datasets, we demonstrate that DGR effectively improves the quality of the shared representations, leading to better multi-task prediction performances. Applied to various classifiers, the shared representations generated by DGR also show superior performance compared to existing multi-task learning methods. Moreover, our approach takes advantage of computational efficiency due to its simplicity. The simplicity also allows us to seamlessly integrate DGR with the existing multi-task learning algorithms.
Fair Generalized Linear Models with a Convex Penalty
Jun 18, 2022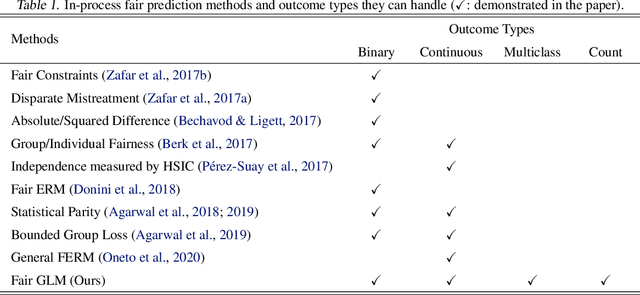
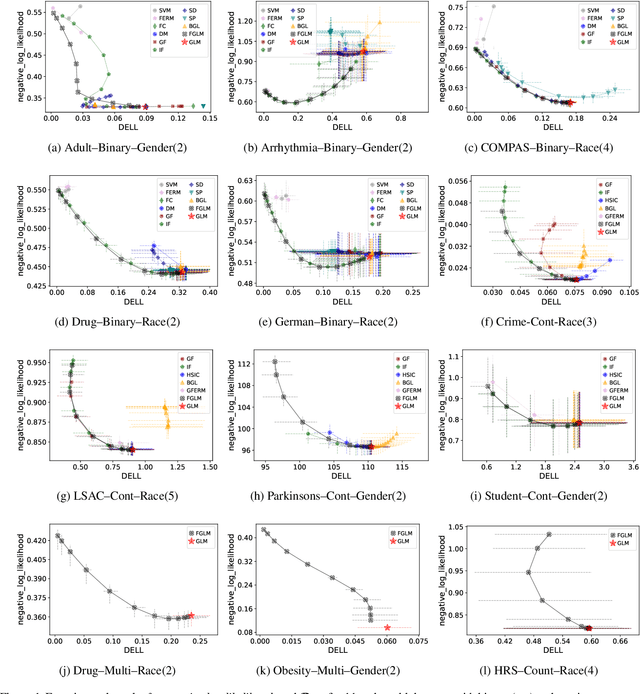

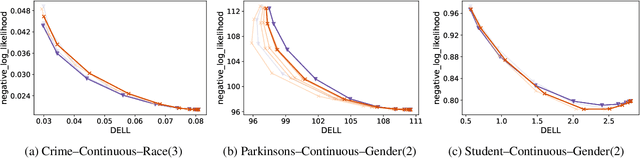
Despite recent advances in algorithmic fairness, methodologies for achieving fairness with generalized linear models (GLMs) have yet to be explored in general, despite GLMs being widely used in practice. In this paper we introduce two fairness criteria for GLMs based on equalizing expected outcomes or log-likelihoods. We prove that for GLMs both criteria can be achieved via a convex penalty term based solely on the linear components of the GLM, thus permitting efficient optimization. We also derive theoretical properties for the resulting fair GLM estimator. To empirically demonstrate the efficacy of the proposed fair GLM, we compare it with other well-known fair prediction methods on an extensive set of benchmark datasets for binary classification and regression. In addition, we demonstrate that the fair GLM can generate fair predictions for a range of response variables, other than binary and continuous outcomes.
Clear the Fog: Combat Value Assessment in Incomplete Information Games with Convolutional Encoder-Decoders
Nov 30, 2018StarCraft, one of the most popular real-time strategy games, is a compelling environment for artificial intelligence research for both micro-level unit control and macro-level strategic decision making. In this study, we address an eminent problem concerning macro-level decision making, known as the 'fog-of-war', which rises naturally from the fact that information regarding the opponent's state is always provided in the incomplete form. For intelligent agents to play like human players, it is obvious that making accurate predictions of the opponent's status under incomplete information will increase its chance of winning. To reflect this fact, we propose a convolutional encoder-decoder architecture that predicts potential counts and locations of the opponent's units based on only partially visible and noisy information. To evaluate the performance of our proposed method, we train an additional classifier on the encoder-decoder output to predict the game outcome (win or lose). Finally, we designed an agent incorporating the proposed method and conducted simulation games against rule-based agents to demonstrate both effectiveness and practicality. All experiments were conducted on actual game replay data acquired from professional players.