 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEscaping Saddle Points with Adaptive Gradient Methods
Jan 26, 2019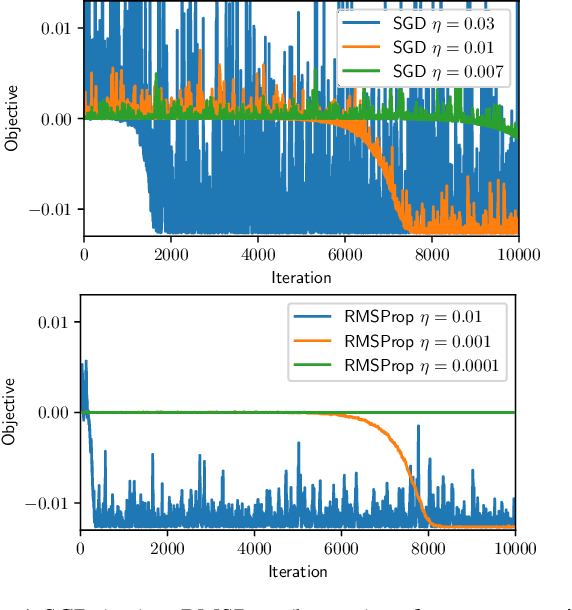
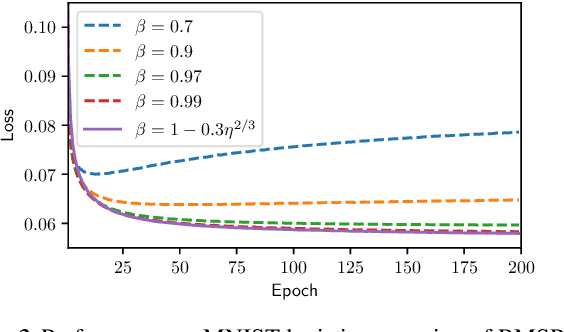
Adaptive methods such as Adam and RMSProp are widely used in deep learning but are not well understood. In this paper, we seek a crisp, clean and precise characterization of their behavior in nonconvex settings. To this end, we first provide a novel view of adaptive methods as preconditioned SGD, where the preconditioner is estimated in an online manner. By studying the preconditioner on its own, we elucidate its purpose: it rescales the stochastic gradient noise to be isotropic near stationary points, which helps escape saddle points. Furthermore, we show that adaptive methods can efficiently estimate the aforementioned preconditioner. By gluing together these two components, we provide the first (to our knowledge) second-order convergence result for any adaptive method. The key insight from our analysis is that, compared to SGD, adaptive methods escape saddle points faster, and can converge faster overall to second-order stationary points.
Stochastic Negative Mining for Learning with Large Output Spaces
Oct 16, 2018
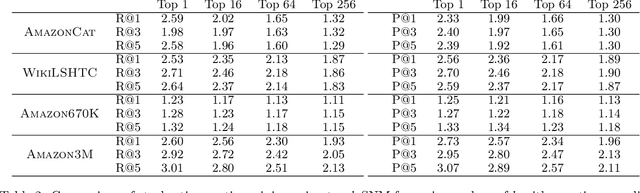
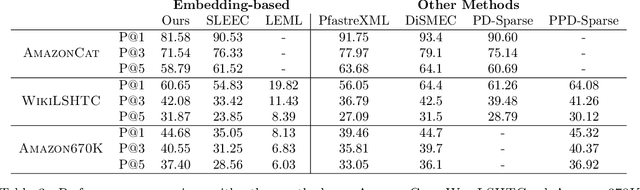
We consider the problem of retrieving the most relevant labels for a given input when the size of the output space is very large. Retrieval methods are modeled as set-valued classifiers which output a small set of classes for each input, and a mistake is made if the label is not in the output set. Despite its practical importance, a statistically principled, yet practical solution to this problem is largely missing. To this end, we first define a family of surrogate losses and show that they are calibrated and convex under certain conditions on the loss parameters and data distribution, thereby establishing a statistical and analytical basis for using these losses. Furthermore, we identify a particularly intuitive class of loss functions in the aforementioned family and show that they are amenable to practical implementation in the large output space setting (i.e. computation is possible without evaluating scores of all labels) by developing a technique called Stochastic Negative Mining. We also provide generalization error bounds for the losses in the family. Finally, we conduct experiments which demonstrate that Stochastic Negative Mining yields benefits over commonly used negative sampling approaches.
Online Learning of Quantum States
Oct 01, 2018Suppose we have many copies of an unknown $n$-qubit state $\rho$. We measure some copies of $\rho$ using a known two-outcome measurement $E_{1}$, then other copies using a measurement $E_{2}$, and so on. At each stage $t$, we generate a current hypothesis $\sigma_{t}$ about the state $\rho$, using the outcomes of the previous measurements. We show that it is possible to do this in a way that guarantees that $|\operatorname{Tr}(E_{i} \sigma_{t}) - \operatorname{Tr}(E_{i}\rho) |$, the error in our prediction for the next measurement, is at least $\varepsilon$ at most $\operatorname{O}\!\left(n / \varepsilon^2 \right) $ times. Even in the "non-realizable" setting---where there could be arbitrary noise in the measurement outcomes---we show how to output hypothesis states that do significantly worse than the best possible states at most $\operatorname{O}\!\left(\sqrt {Tn}\right) $ times on the first $T$ measurements. These results generalize a 2007 theorem by Aaronson on the PAC-learnability of quantum states, to the online and regret-minimization settings. We give three different ways to prove our results---using convex optimization, quantum postselection, and sequential fat-shattering dimension---which have different advantages in terms of parameters and portability.
Logistic Regression: The Importance of Being Improper
Mar 25, 2018Learning linear predictors with the logistic loss---both in stochastic and online settings---is a fundamental task in learning and statistics, with direct connections to classification and boosting. Existing "fast rates" for this setting exhibit exponential dependence on the predictor norm, and Hazan et al. (2014) showed that this is unfortunately unimprovable. Starting with the simple observation that the logistic loss is 1-mixable, we design a new efficient improper learning algorithm for online logistic regression that circumvents the aforementioned lower bound with a regret bound exhibiting a doubly-exponential improvement in dependence on the predictor norm. This provides a positive resolution to a variant of the COLT 2012 open problem of McMahan and Streeter (2012) when improper learning is allowed. This improvement is obtained both in the online setting and, with some extra work, in the batch statistical setting with high probability. We also show that the improved dependency on predictor norm is also near-optimal. Leveraging this improved dependency on the predictor norm yields the following applications: (a) we give algorithms for online bandit multiclass learning with the logistic loss with an $\tilde{O}(\sqrt{n})$ relative mistake bound across essentially all parameter ranges, thus providing a solution to the COLT 2009 open problem of Abernethy and Rakhlin (2009), and (b) we give an adaptive algorithm for online multiclass boosting with optimal sample complexity, thus partially resolving an open problem of Beygelzimer et al. (2015) and Jung et al. (2017). Finally, we give information-theoretic bounds on the optimal rates for improper logistic regression with general function classes, thereby characterizing the extent to which our improvement for linear classes extends to other parameteric and even nonparametric settings.
Parameter-free online learning via model selection
Jan 03, 2018We introduce an efficient algorithmic framework for model selection in online learning, also known as parameter-free online learning. Departing from previous work, which has focused on highly structured function classes such as nested balls in Hilbert space, we propose a generic meta-algorithm framework that achieves online model selection oracle inequalities under minimal structural assumptions. We give the first computationally efficient parameter-free algorithms that work in arbitrary Banach spaces under mild smoothness assumptions; previous results applied only to Hilbert spaces. We further derive new oracle inequalities for matrix classes, non-nested convex sets, and $\mathbb{R}^{d}$ with generic regularizers. Finally, we generalize these results by providing oracle inequalities for arbitrary non-linear classes in the online supervised learning model. These results are all derived through a unified meta-algorithm scheme using a novel "multi-scale" algorithm for prediction with expert advice based on random playout, which may be of independent interest.
Adaptive Feature Selection: Computationally Efficient Online Sparse Linear Regression under RIP
Jun 14, 2017Online sparse linear regression is an online problem where an algorithm repeatedly chooses a subset of coordinates to observe in an adversarially chosen feature vector, makes a real-valued prediction, receives the true label, and incurs the squared loss. The goal is to design an online learning algorithm with sublinear regret to the best sparse linear predictor in hindsight. Without any assumptions, this problem is known to be computationally intractable. In this paper, we make the assumption that data matrix satisfies restricted isometry property, and show that this assumption leads to computationally efficient algorithms with sublinear regret for two variants of the problem. In the first variant, the true label is generated according to a sparse linear model with additive Gaussian noise. In the second, the true label is chosen adversarially.
Hardness of Online Sleeping Combinatorial Optimization Problems
Dec 19, 2016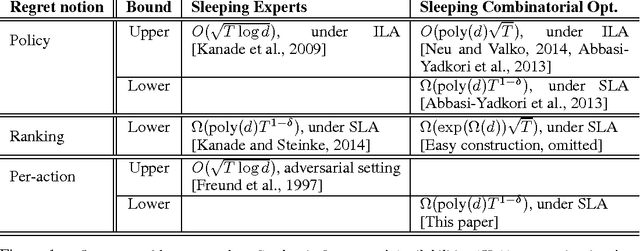
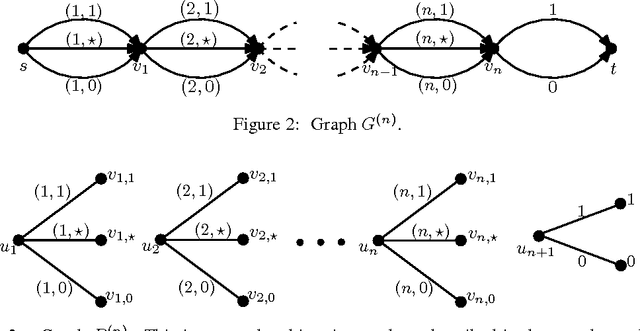

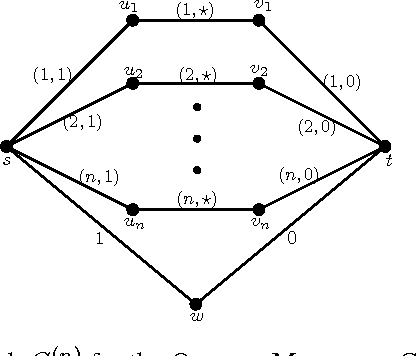
We show that several online combinatorial optimization problems that admit efficient no-regret algorithms become computationally hard in the sleeping setting where a subset of actions becomes unavailable in each round. Specifically, we show that the sleeping versions of these problems are at least as hard as PAC learning DNF expressions, a long standing open problem. We show hardness for the sleeping versions of Online Shortest Paths, Online Minimum Spanning Tree, Online $k$-Subsets, Online $k$-Truncated Permutations, Online Minimum Cut, and Online Bipartite Matching. The hardness result for the sleeping version of the Online Shortest Paths problem resolves an open problem presented at COLT 2015 (Koolen et al., 2015).
Online Sparse Linear Regression
Mar 07, 2016We consider the online sparse linear regression problem, which is the problem of sequentially making predictions observing only a limited number of features in each round, to minimize regret with respect to the best sparse linear regressor, where prediction accuracy is measured by square loss. We give an inefficient algorithm that obtains regret bounded by $\tilde{O}(\sqrt{T})$ after $T$ prediction rounds. We complement this result by showing that no algorithm running in polynomial time per iteration can achieve regret bounded by $O(T^{1-\delta})$ for any constant $\delta > 0$ unless $\text{NP} \subseteq \text{BPP}$. This computational hardness result resolves an open problem presented in COLT 2014 (Kale, 2014) and also posed by Zolghadr et al. (2013). This hardness result holds even if the algorithm is allowed to access more features than the best sparse linear regressor up to a logarithmic factor in the dimension.
Online Gradient Boosting
Oct 30, 2015We extend the theory of boosting for regression problems to the online learning setting. Generalizing from the batch setting for boosting, the notion of a weak learning algorithm is modeled as an online learning algorithm with linear loss functions that competes with a base class of regression functions, while a strong learning algorithm is an online learning algorithm with convex loss functions that competes with a larger class of regression functions. Our main result is an online gradient boosting algorithm which converts a weak online learning algorithm into a strong one where the larger class of functions is the linear span of the base class. We also give a simpler boosting algorithm that converts a weak online learning algorithm into a strong one where the larger class of functions is the convex hull of the base class, and prove its optimality.
Optimal and Adaptive Algorithms for Online Boosting
Feb 09, 2015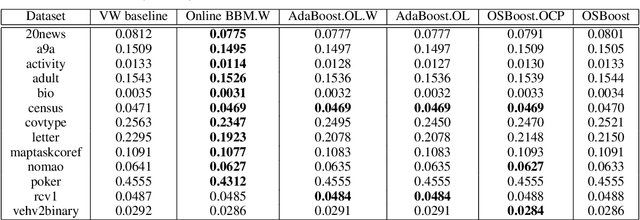
We study online boosting, the task of converting any weak online learner into a strong online learner. Based on a novel and natural definition of weak online learnability, we develop two online boosting algorithms. The first algorithm is an online version of boost-by-majority. By proving a matching lower bound, we show that this algorithm is essentially optimal in terms of the number of weak learners and the sample complexity needed to achieve a specified accuracy. This optimal algorithm is not adaptive however. Using tools from online loss minimization, we derive an adaptive online boosting algorithm that is also parameter-free, but not optimal. Both algorithms work with base learners that can handle example importance weights directly, as well as by rejection sampling examples with probability defined by the booster. Results are complemented with an extensive experimental study.