 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAction Recognition based on Cross-Situational Action-object Statistics
Aug 15, 2022

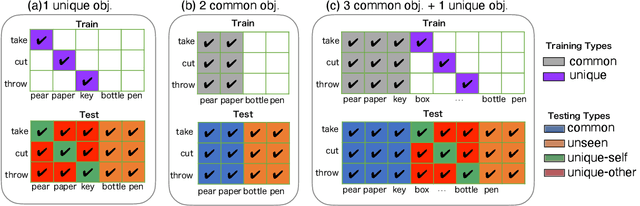
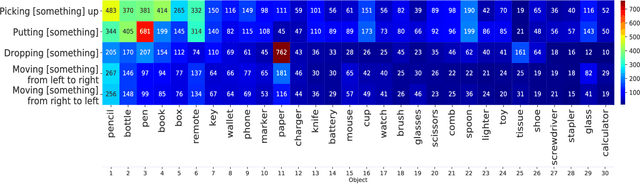
Machine learning models of visual action recognition are typically trained and tested on data from specific situations where actions are associated with certain objects. It is an open question how action-object associations in the training set influence a model's ability to generalize beyond trained situations. We set out to identify properties of training data that lead to action recognition models with greater generalization ability. To do this, we take inspiration from a cognitive mechanism called cross-situational learning, which states that human learners extract the meaning of concepts by observing instances of the same concept across different situations. We perform controlled experiments with various types of action-object associations, and identify key properties of action-object co-occurrence in training data that lead to better classifiers. Given that these properties are missing in the datasets that are typically used to train action classifiers in the computer vision literature, our work provides useful insights on how we should best construct datasets for efficiently training for better generalization.
Novel View Synthesis for High-fidelity Headshot Scenes
May 31, 2022
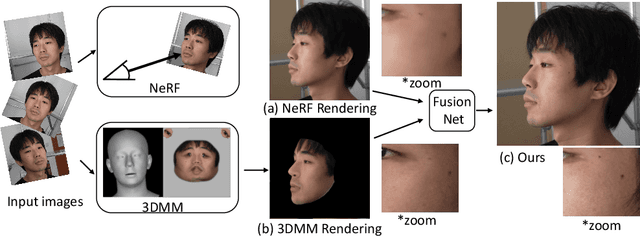
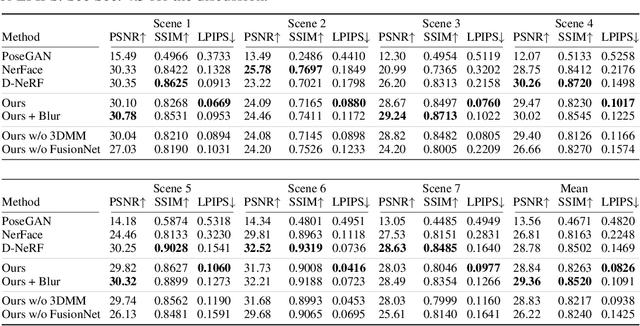
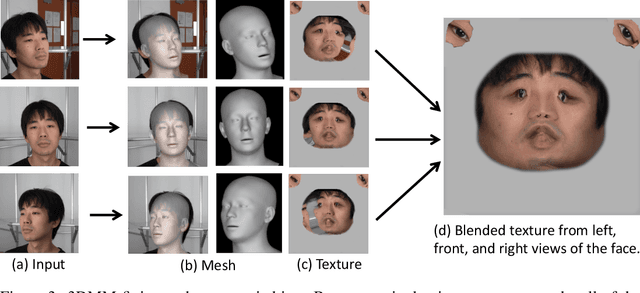
Rendering scenes with a high-quality human face from arbitrary viewpoints is a practical and useful technique for many real-world applications. Recently, Neural Radiance Fields (NeRF), a rendering technique that uses neural networks to approximate classical ray tracing, have been considered as one of the promising approaches for synthesizing novel views from a sparse set of images. We find that NeRF can render new views while maintaining geometric consistency, but it does not properly maintain skin details, such as moles and pores. These details are important particularly for faces because when we look at an image of a face, we are much more sensitive to details than when we look at other objects. On the other hand, 3D Morpable Models (3DMMs) based on traditional meshes and textures can perform well in terms of skin detail despite that it has less precise geometry and cannot cover the head and the entire scene with background. Based on these observations, we propose a method to use both NeRF and 3DMM to synthesize a high-fidelity novel view of a scene with a face. Our method learns a Generative Adversarial Network (GAN) to mix a NeRF-synthesized image and a 3DMM-rendered image and produces a photorealistic scene with a face preserving the skin details. Experiments with various real-world scenes demonstrate the effectiveness of our approach. The code will be available on https://github.com/showlab/headshot .
Reinforcing Generated Images via Meta-learning for One-Shot Fine-Grained Visual Recognition
Apr 22, 2022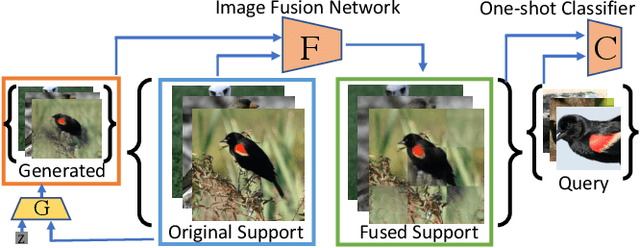

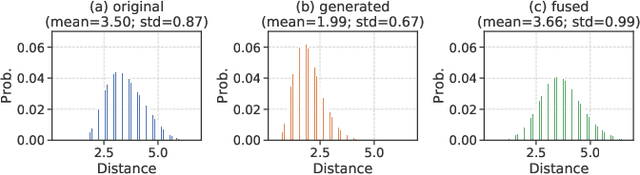
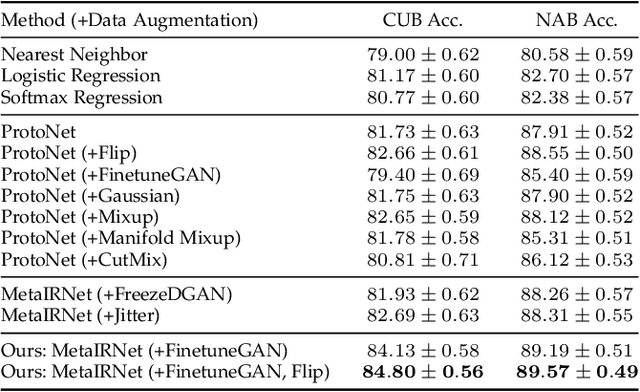
One-shot fine-grained visual recognition often suffers from the problem of having few training examples for new fine-grained classes. To alleviate this problem, off-the-shelf image generation techniques based on Generative Adversarial Networks (GANs) can potentially create additional training images. However, these GAN-generated images are often not helpful for actually improving the accuracy of one-shot fine-grained recognition. In this paper, we propose a meta-learning framework to combine generated images with original images, so that the resulting "hybrid" training images improve one-shot learning. Specifically, the generic image generator is updated by a few training instances of novel classes, and a Meta Image Reinforcing Network (MetaIRNet) is proposed to conduct one-shot fine-grained recognition as well as image reinforcement. Our experiments demonstrate consistent improvement over baselines on one-shot fine-grained image classification benchmarks. Furthermore, our analysis shows that the reinforced images have more diversity compared to the original and GAN-generated images.
How You Move Your Head Tells What You Do: Self-supervised Video Representation Learning with Egocentric Cameras and IMU Sensors
Oct 04, 2021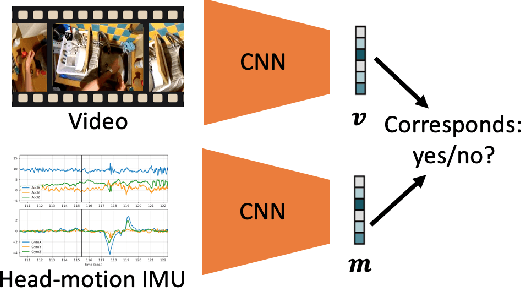
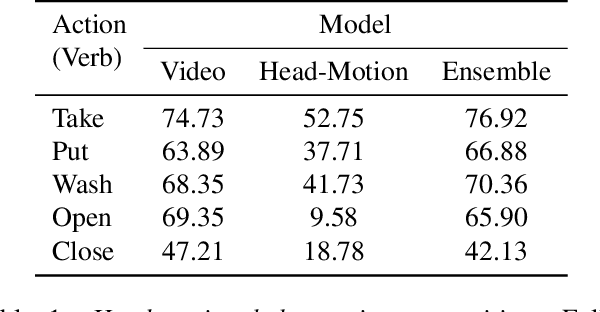
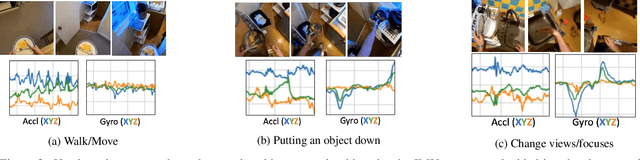
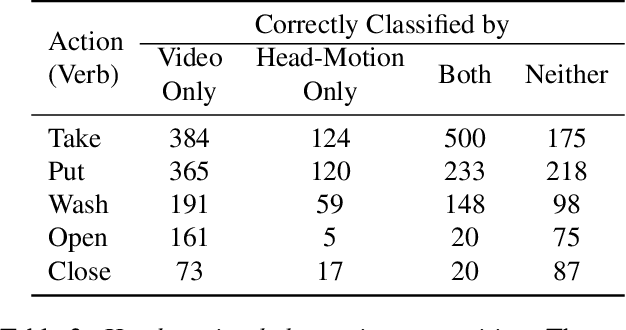
Understanding users' activities from head-mounted cameras is a fundamental task for Augmented and Virtual Reality (AR/VR) applications. A typical approach is to train a classifier in a supervised manner using data labeled by humans. This approach has limitations due to the expensive annotation cost and the closed coverage of activity labels. A potential way to address these limitations is to use self-supervised learning (SSL). Instead of relying on human annotations, SSL leverages intrinsic properties of data to learn representations. We are particularly interested in learning egocentric video representations benefiting from the head-motion generated by users' daily activities, which can be easily obtained from IMU sensors embedded in AR/VR devices. Towards this goal, we propose a simple but effective approach to learn video representation by learning to tell the corresponding pairs of video clip and head-motion. We demonstrate the effectiveness of our learned representation for recognizing egocentric activities of people and dogs.
Reverse-engineer the Distributional Structure of Infant Egocentric Views for Training Generalizable Image Classifiers
Jun 12, 2021
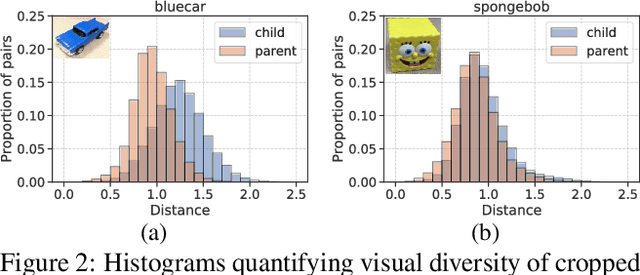
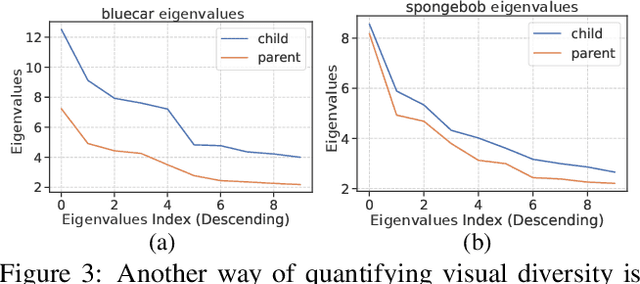
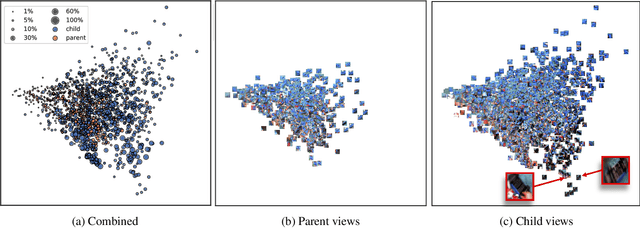
We analyze egocentric views of attended objects from infants. This paper shows 1) empirical evidence that children's egocentric views have more diverse distributions compared to adults' views, 2) we can computationally simulate the infants' distribution, and 3) the distribution is beneficial for training more generalized image classifiers not only for infant egocentric vision but for third-person computer vision.
Whose hand is this? Person Identification from Egocentric Hand Gestures
Nov 17, 2020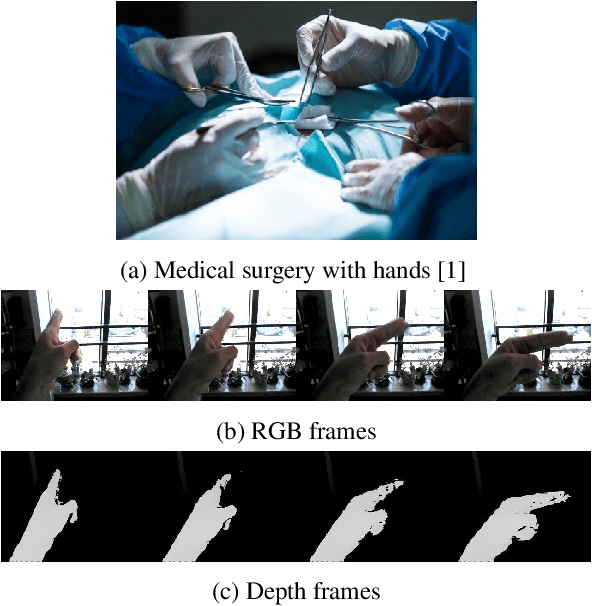
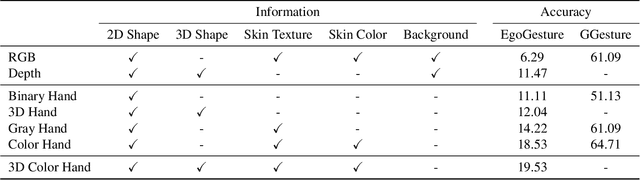
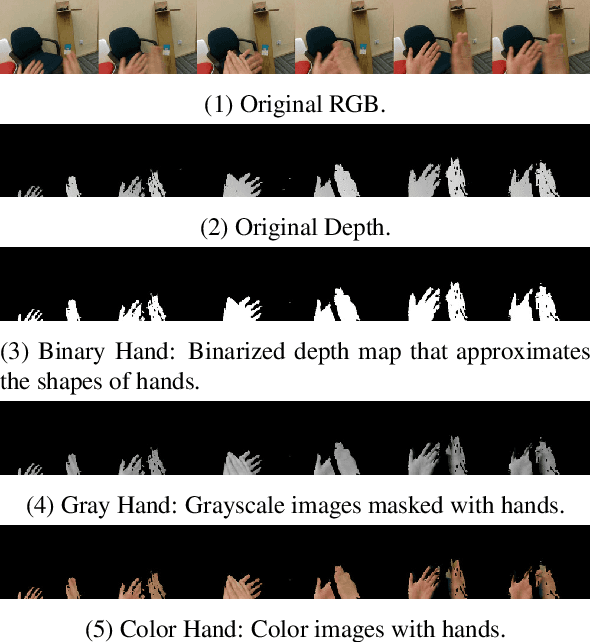

Recognizing people by faces and other biometrics has been extensively studied in computer vision. But these techniques do not work for identifying the wearer of an egocentric (first-person) camera because that person rarely (if ever) appears in their own first-person view. But while one's own face is not frequently visible, their hands are: in fact, hands are among the most common objects in one's own field of view. It is thus natural to ask whether the appearance and motion patterns of people's hands are distinctive enough to recognize them. In this paper, we systematically study the possibility of Egocentric Hand Identification (EHI) with unconstrained egocentric hand gestures. We explore several different visual cues, including color, shape, skin texture, and depth maps to identify users' hands. Extensive ablation experiments are conducted to analyze the properties of hands that are most distinctive. Finally, we show that EHI can improve generalization of other tasks, such as gesture recognition, by training adversarially to encourage these models to ignore differences between users.
A Computational Model of Early Word Learning from the Infant's Point of View
Jun 04, 2020
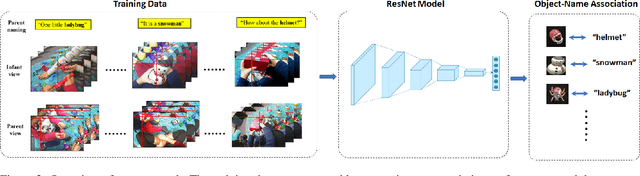


Human infants have the remarkable ability to learn the associations between object names and visual objects from inherently ambiguous experiences. Researchers in cognitive science and developmental psychology have built formal models that implement in-principle learning algorithms, and then used pre-selected and pre-cleaned datasets to test the abilities of the models to find statistical regularities in the input data. In contrast to previous modeling approaches, the present study used egocentric video and gaze data collected from infant learners during natural toy play with their parents. This allowed us to capture the learning environment from the perspective of the learner's own point of view. We then used a Convolutional Neural Network (CNN) model to process sensory data from the infant's point of view and learn name-object associations from scratch. As the first model that takes raw egocentric video to simulate infant word learning, the present study provides a proof of principle that the problem of early word learning can be solved, using actual visual data perceived by infant learners. Moreover, we conducted simulation experiments to systematically determine how visual, perceptual, and attentional properties of infants' sensory experiences may affect word learning.
Meta-Reinforced Synthetic Data for One-Shot Fine-Grained Visual Recognition
Nov 17, 2019
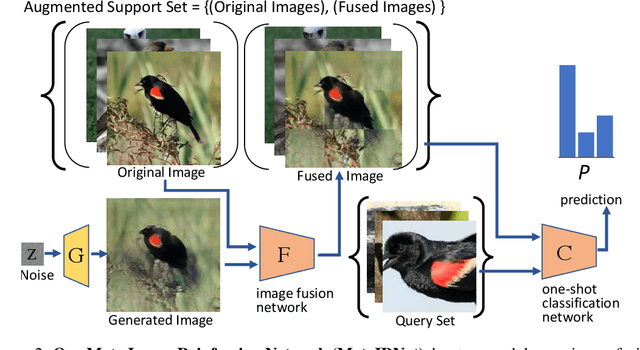
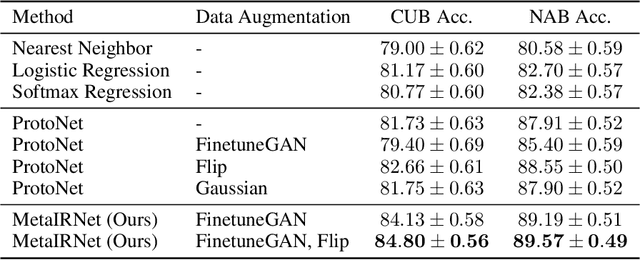
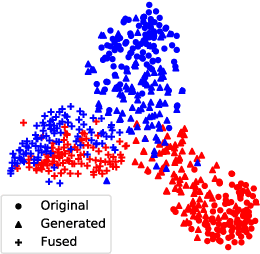
One-shot fine-grained visual recognition often suffers from the problem of training data scarcity for new fine-grained classes. To alleviate this problem, an off-the-shelf image generator can be applied to synthesize additional training images, but these synthesized images are often not helpful for actually improving the accuracy of one-shot fine-grained recognition. This paper proposes a meta-learning framework to combine generated images with original images, so that the resulting ``hybrid'' training images can improve one-shot learning. Specifically, the generic image generator is updated by a few training instances of novel classes, and a Meta Image Reinforcing Network (MetaIRNet) is proposed to conduct one-shot fine-grained recognition as well as image reinforcement. The model is trained in an end-to-end manner, and our experiments demonstrate consistent improvement over baselines on one-shot fine-grained image classification benchmarks.
Active Object Manipulation Facilitates Visual Object Learning: An Egocentric Vision Study
Jun 04, 2019Inspired by the remarkable ability of the infant visual learning system, a recent study collected first-person images from children to analyze the `training data' that they receive. We conduct a follow-up study that investigates two additional directions. First, given that infants can quickly learn to recognize a new object without much supervision (i.e. few-shot learning), we limit the number of training images. Second, we investigate how children control the supervision signals they receive during learning based on hand manipulation of objects. Our experimental results suggest that supervision with hand manipulation is better than without hands, and the trend is consistent even when a small number of images is available.
Combining Pyramid Pooling and Attention Mechanism for Pelvic MR Image Semantic Segmentaion
Jun 28, 2018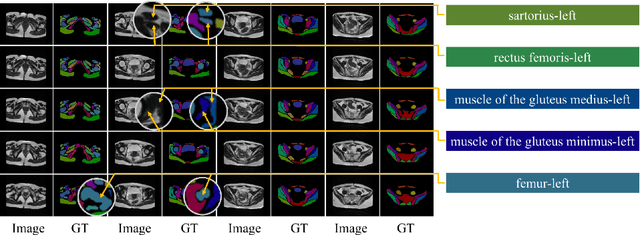
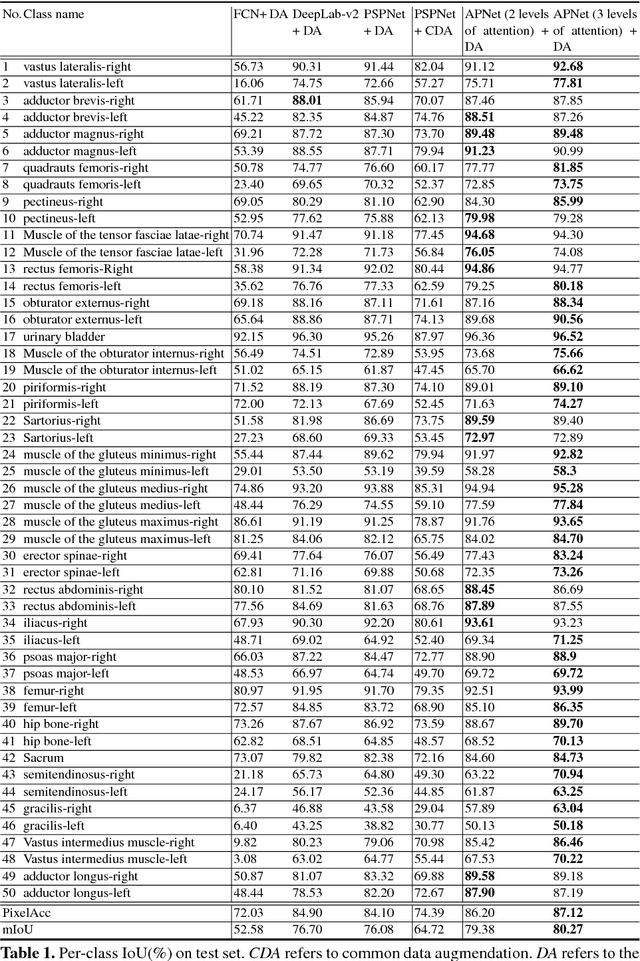

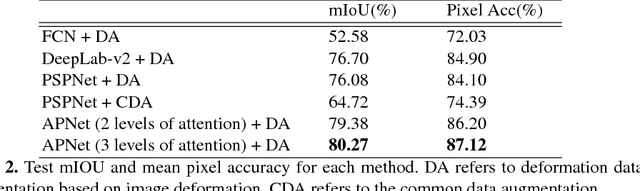
One of the time-consuming routine work for a radiologist is to discern anatomical structures from tomographic images. For assisting radiologists, this paper develops an automatic segmentation method for pelvic magnetic resonance (MR) images. The task has three major challenges 1) A pelvic organ can have various sizes and shapes depending on the axial image, which requires local contexts to segment correctly. 2) Different organs often have quite similar appearance in MR images, which requires global context to segment. 3) The number of available annotated images are very small to use the latest segmentation algorithms. To address the challenges, we propose a novel convolutional neural network called Attention-Pyramid network (APNet) that effectively exploits both local and global contexts, in addition to a data-augmentation technique that is particularly effective for MR images. In order to evaluate our method, we construct fine-grained (50 pelvic organs) MR image segmentation dataset, and experimentally confirm the superior performance of our techniques over the state-of-the-art image segmentation methods.