 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARTA: Collection and Classification of Ambiguous Requests and Thoughtful Actions
Jun 15, 2021


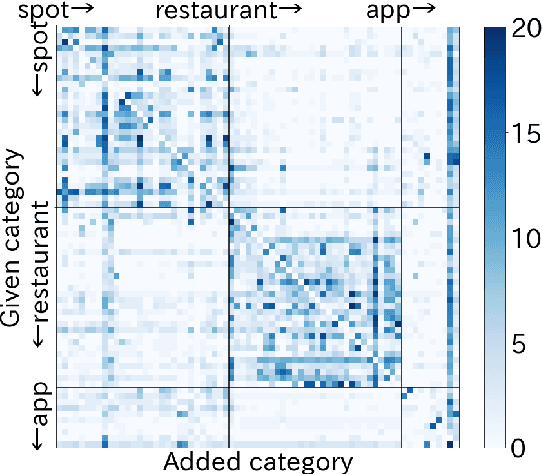
Human-assisting systems such as dialogue systems must take thoughtful, appropriate actions not only for clear and unambiguous user requests, but also for ambiguous user requests, even if the users themselves are not aware of their potential requirements. To construct such a dialogue agent, we collected a corpus and developed a model that classifies ambiguous user requests into corresponding system actions. In order to collect a high-quality corpus, we asked workers to input antecedent user requests whose pre-defined actions could be regarded as thoughtful. Although multiple actions could be identified as thoughtful for a single user request, annotating all combinations of user requests and system actions is impractical. For this reason, we fully annotated only the test data and left the annotation of the training data incomplete. In order to train the classification model on such training data, we applied the positive/unlabeled (PU) learning method, which assumes that only a part of the data is labeled with positive examples. The experimental results show that the PU learning method achieved better performance than the general positive/negative (PN) learning method to classify thoughtful actions given an ambiguous user request.
Simultaneous Speech-to-Speech Translation System with Neural Incremental ASR, MT, and TTS
Nov 11, 2020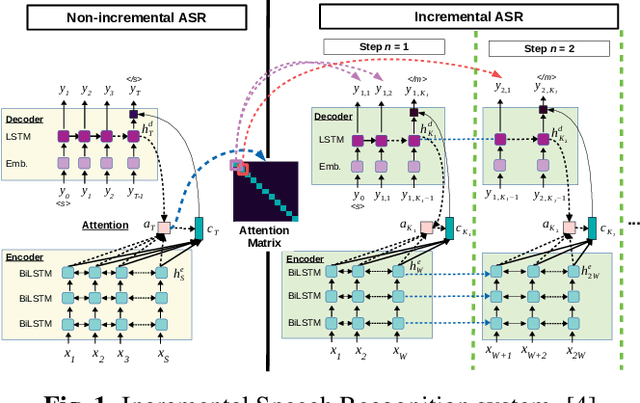
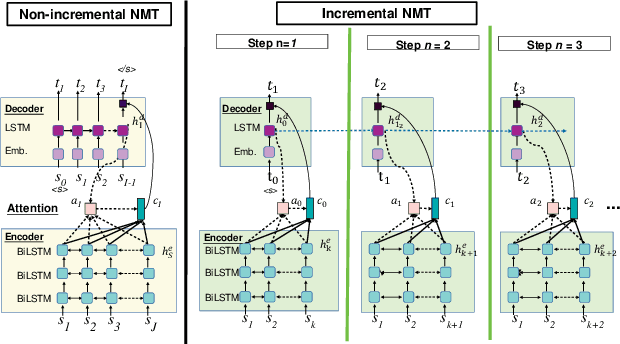
This paper presents a newly developed, simultaneous neural speech-to-speech translation system and its evaluation. The system consists of three fully-incremental neural processing modules for automatic speech recognition (ASR), machine translation (MT), and text-to-speech synthesis (TTS). We investigated its overall latency in the system's Ear-Voice Span and speaking latency along with module-level performance.
Cross-Lingual Machine Speech Chain for Javanese, Sundanese, Balinese, and Bataks Speech Recognition and Synthesis
Nov 04, 2020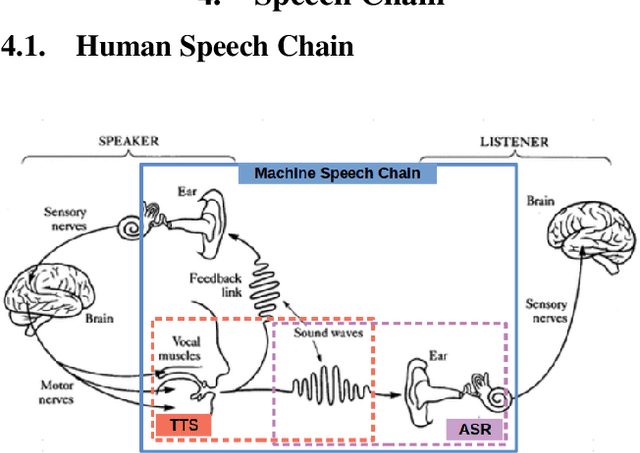


Even though over seven hundred ethnic languages are spoken in Indonesia, the available technology remains limited that could support communication within indigenous communities as well as with people outside the villages. As a result, indigenous communities still face isolation due to cultural barriers; languages continue to disappear. To accelerate communication, speech-to-speech translation (S2ST) technology is one approach that can overcome language barriers. However, S2ST systems require machine translation (MT), speech recognition (ASR), and synthesis (TTS) that rely heavily on supervised training and a broad set of language resources that can be difficult to collect from ethnic communities. Recently, a machine speech chain mechanism was proposed to enable ASR and TTS to assist each other in semi-supervised learning. The framework was initially implemented only for monolingual languages. In this study, we focus on developing speech recognition and synthesis for these Indonesian ethnic languages: Javanese, Sundanese, Balinese, and Bataks. We first separately train ASR and TTS of standard Indonesian in supervised training. We then develop ASR and TTS of ethnic languages by utilizing Indonesian ASR and TTS in a cross-lingual machine speech chain framework with only text or only speech data removing the need for paired speech-text data of those ethnic languages.
Sequence-to-Sequence Learning via Attention Transfer for Incremental Speech Recognition
Nov 04, 2020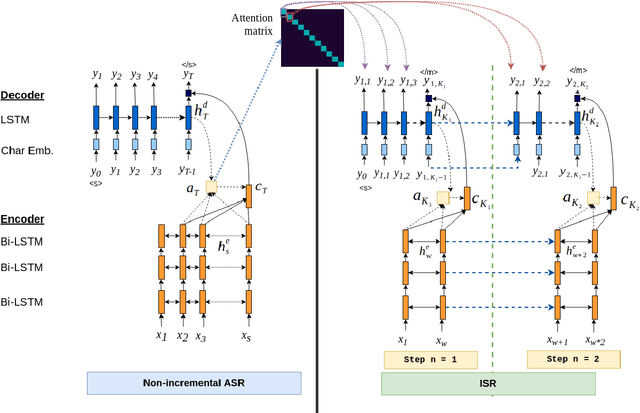
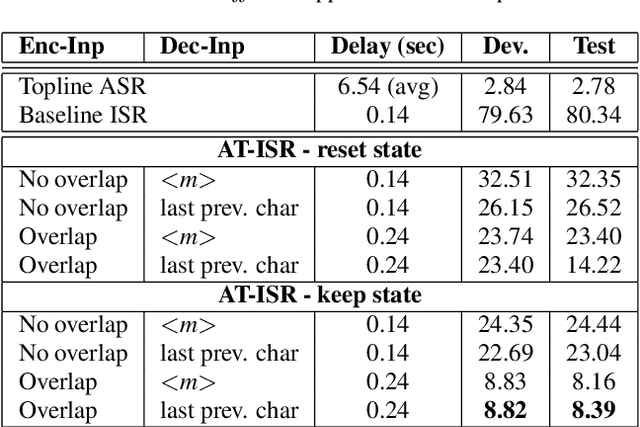
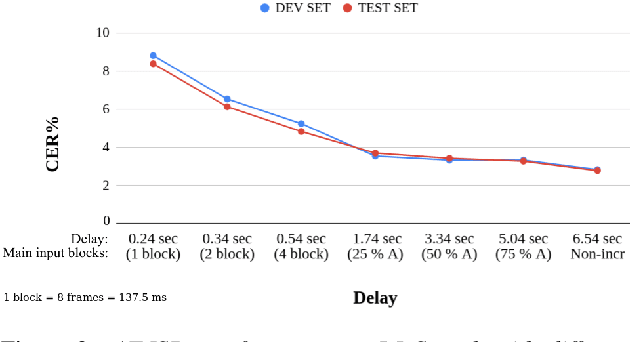
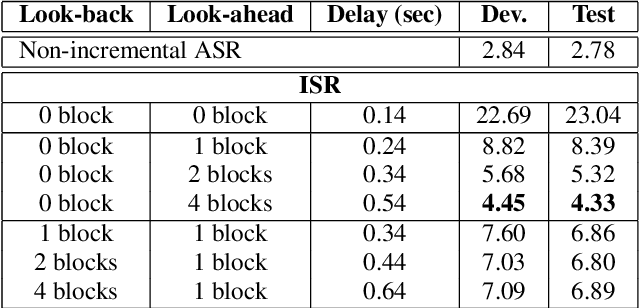
Attention-based sequence-to-sequence automatic speech recognition (ASR) requires a significant delay to recognize long utterances because the output is generated after receiving entire input sequences. Although several studies recently proposed sequence mechanisms for incremental speech recognition (ISR), using different frameworks and learning algorithms is more complicated than the standard ASR model. One main reason is because the model needs to decide the incremental steps and learn the transcription that aligns with the current short speech segment. In this work, we investigate whether it is possible to employ the original architecture of attention-based ASR for ISR tasks by treating a full-utterance ASR as the teacher model and the ISR as the student model. We design an alternative student network that, instead of using a thinner or a shallower model, keeps the original architecture of the teacher model but with shorter sequences (few encoder and decoder states). Using attention transfer, the student network learns to mimic the same alignment between the current input short speech segments and the transcription. Our experiments show that by delaying the starting time of recognition process with about 1.7 sec, we can achieve comparable performance to one that needs to wait until the end.
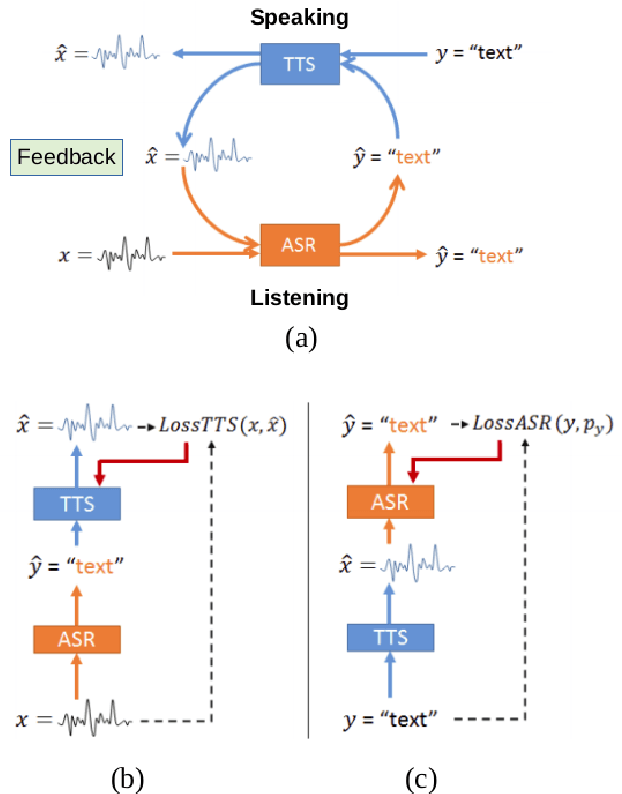
Incremental Machine Speech Chain Towards Enabling Listening while Speaking in Real-time
Nov 04, 2020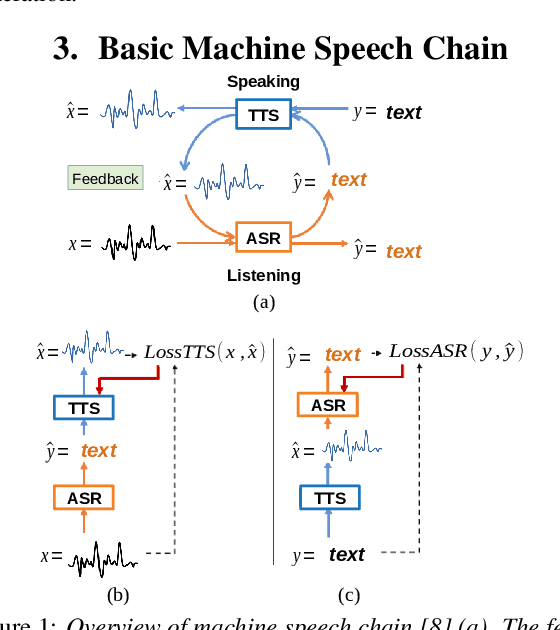
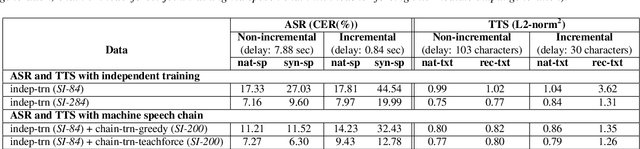
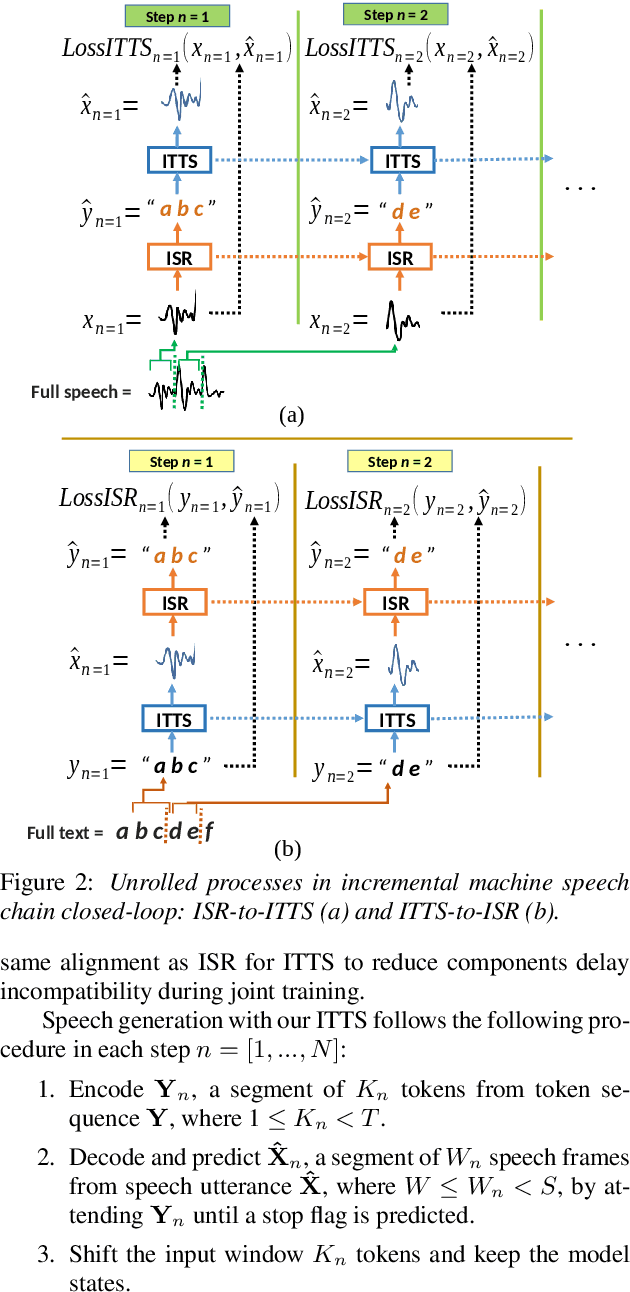
Inspired by a human speech chain mechanism, a machine speech chain framework based on deep learning was recently proposed for the semi-supervised development of automatic speech recognition (ASR) and text-to-speech synthesis TTS) systems. However, the mechanism to listen while speaking can be done only after receiving entire input sequences. Thus, there is a significant delay when encountering long utterances. By contrast, humans can listen to what hey speak in real-time, and if there is a delay in hearing, they won't be able to continue speaking. In this work, we propose an incremental machine speech chain towards enabling machine to listen while speaking in real-time. Specifically, we construct incremental ASR (ISR) and incremental TTS (ITTS) by letting both systems improve together through a short-term loop. Our experimental results reveal that our proposed framework is able to reduce delays due to long utterances while keeping a comparable performance to the non-incremental basic machine speech chain.
Augmenting Images for ASR and TTS through Single-loop and Dual-loop Multimodal Chain Framework
Nov 04, 2020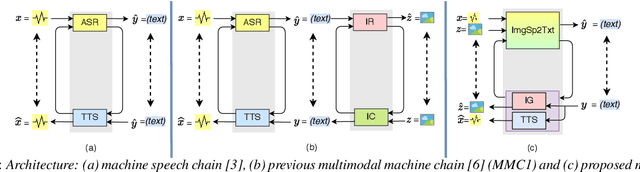
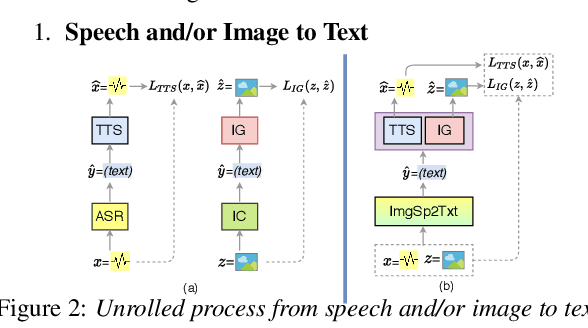
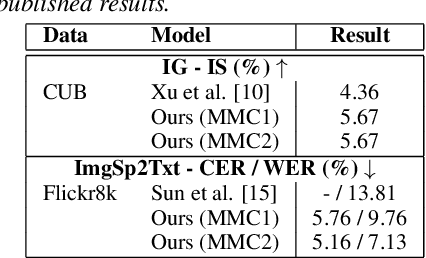
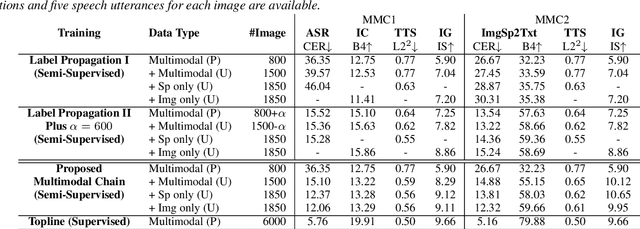
Previous research has proposed a machine speech chain to enable automatic speech recognition (ASR) and text-to-speech synthesis (TTS) to assist each other in semi-supervised learning and to avoid the need for a large amount of paired speech and text data. However, that framework still requires a large amount of unpaired (speech or text) data. A prototype multimodal machine chain was then explored to further reduce the need for a large amount of unpaired data, which could improve ASR or TTS even when no more speech or text data were available. Unfortunately, this framework relied on the image retrieval (IR) model, and thus it was limited to handling only those images that were already known during training. Furthermore, the performance of this framework was only investigated with single-speaker artificial speech data. In this study, we revamp the multimodal machine chain framework with image generation (IG) and investigate the possibility of augmenting image data for ASR and TTS using single-loop and dual-loop architectures on multispeaker natural speech data. Experimental results revealed that both single-loop and dual-loop multimodal chain frameworks enabled ASR and TTS to improve their performance using an image-only dataset.
Image Captioning with Visual Object Representations Grounded in the Textual Modality
Oct 20, 2020
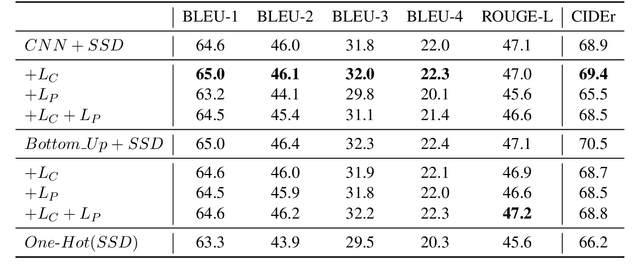
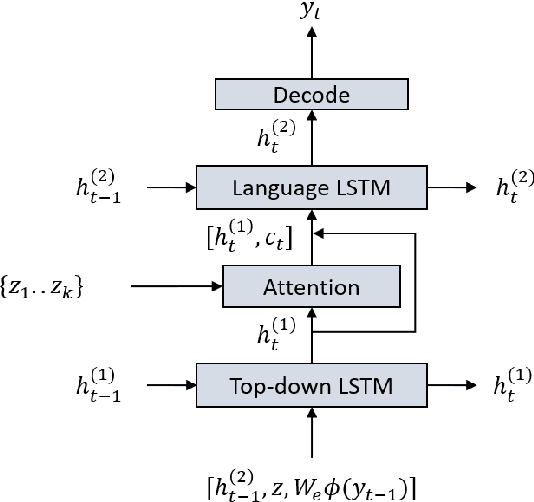
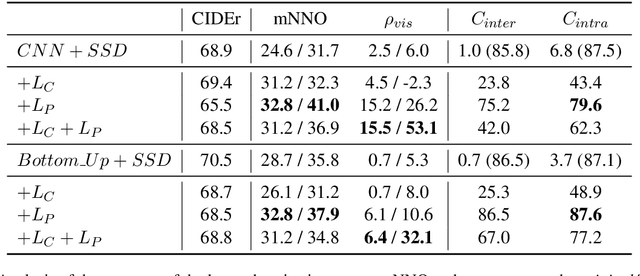
We present our work in progress exploring the possibilities of a shared embedding space between textual and visual modality. Leveraging the textual nature of object detection labels and the hypothetical expressiveness of extracted visual object representations, we propose an approach opposite to the current trend, grounding of the representations in the word embedding space of the captioning system instead of grounding words or sentences in their associated images. Based on the previous work, we apply additional grounding losses to the image captioning training objective aiming to force visual object representations to create more heterogeneous clusters based on their class label and copy a semantic structure of the word embedding space. In addition, we provide an analysis of the learned object vector space projection and its impact on the IC system performance. With only slight change in performance, grounded models reach the stopping criterion during training faster than the unconstrained model, needing about two to three times less training updates. Additionally, an improvement in structural correlation between the word embeddings and both original and projected object vectors suggests that the grounding is actually mutual.
ReMOTS: Self-Supervised Refining Multi-Object Tracking and Segmentation
Jul 08, 2020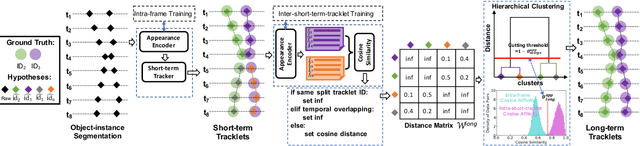
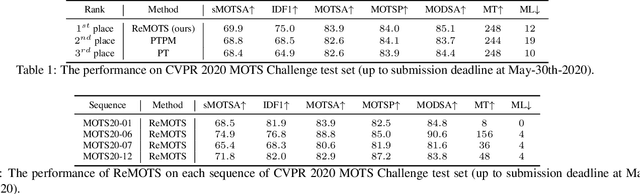
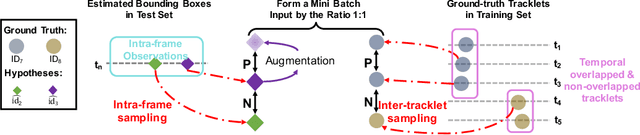
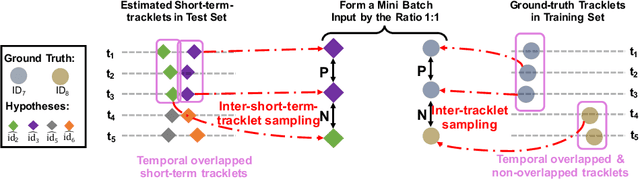
We aim to improve the performance of Multiple Object Tracking and Segmentation (MOTS) by refinement. However, it remains challenging for refining MOTS results, which could be attributed to that appearance features are not adapted to target videos and it is also difficult to find proper thresholds to discriminate them. To tackle this issue, we propose a self-supervised refining MOTS (i.e., ReMOTS) framework. ReMOTS mainly takes four steps to refine MOTS results from the data association perspective. (1) Training the appearance encoder using predicted masks. (2) Associating observations across adjacent frames to form short-term tracklets. (3) Training the appearance encoder using short-term tracklets as reliable pseudo labels. (4) Merging short-term tracklets to long-term tracklets utilizing adopted appearance features and thresholds that are automatically obtained from statistical information. Using ReMOTS, we reached the $1^{st}$ place on CVPR 2020 MOTS Challenge 1, with an sMOTSA score of $69.9$.
Reflection-based Word Attribute Transfer
Jul 07, 2020Word embeddings, which often represent such analogic relations as king - man + woman = queen, can be used to change a word's attribute, including its gender. For transferring king into queen in this analogy-based manner, we subtract a difference vector man - woman based on the knowledge that king is male. However, developing such knowledge is very costly for words and attributes. In this work, we propose a novel method for word attribute transfer based on reflection mappings without such an analogy operation. Experimental results show that our proposed method can transfer the word attributes of the given words without changing the words that do not have the target attributes.
Transformer VQ-VAE for Unsupervised Unit Discovery and Speech Synthesis: ZeroSpeech 2020 Challenge
May 24, 2020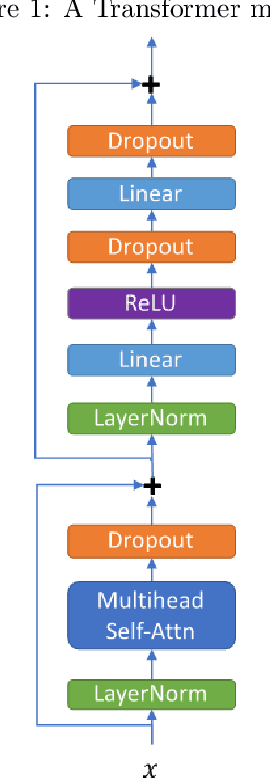
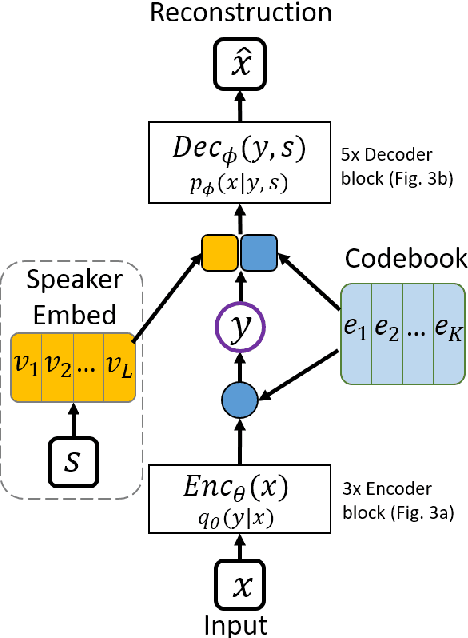

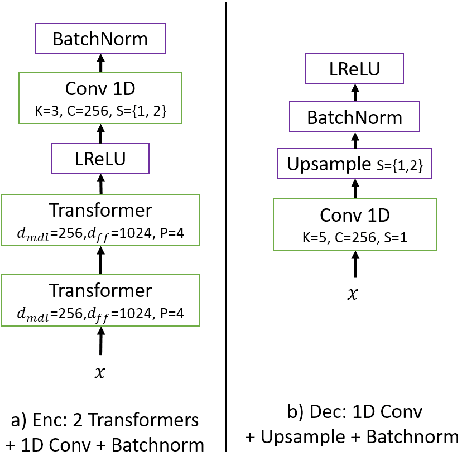
In this paper, we report our submitted system for the ZeroSpeech 2020 challenge on Track 2019. The main theme in this challenge is to build a speech synthesizer without any textual information or phonetic labels. In order to tackle those challenges, we build a system that must address two major components such as 1) given speech audio, extract subword units in an unsupervised way and 2) re-synthesize the audio from novel speakers. The system also needs to balance the codebook performance between the ABX error rate and the bitrate compression rate. Our main contribution here is we proposed Transformer-based VQ-VAE for unsupervised unit discovery and Transformer-based inverter for the speech synthesis given the extracted codebook. Additionally, we also explored several regularization methods to improve performance even further.