 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Flow Estimation using Geometric Regularization with Applications to Camera Image and Grid Map Sequences
Apr 17, 2019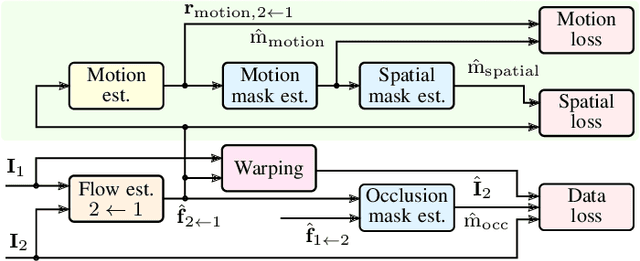

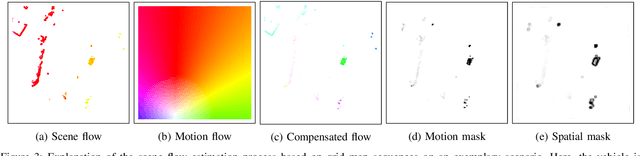
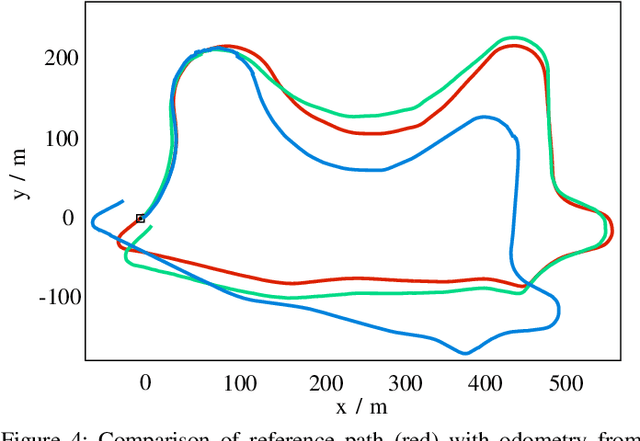
We present a self-supervised approach to estimate flow in camera image and top-view grid map sequences using fully convolutional neural networks in the domain of automated driving. We extend existing approaches for self-supervised optical flow estimation by adding a regularizer expressing motion consistency assuming a static environment. However, as this assumption is violated for other moving traffic participants we also estimate a mask to scale this regularization. Adding a regularization towards motion consistency improves convergence and flow estimation accuracy. Furthermore, we scale the errors due to spatial flow inconsistency by a mask that we derive from the motion mask. This improves accuracy in regions where the flow drastically changes due to a better separation between static and dynamic environment. We apply our approach to optical flow estimation from camera image sequences, validate on odometry estimation and suggest a method to iteratively increase optical flow estimation accuracy using the generated motion masks. Finally, we provide quantitative and qualitative results based on the KITTI odometry and tracking benchmark for scene flow estimation based on grid map sequences. We show that we can improve accuracy and convergence when applying motion and spatial consistency regularization.
Capturing Object Detection Uncertainty in Multi-Layer Grid Maps
Jan 31, 2019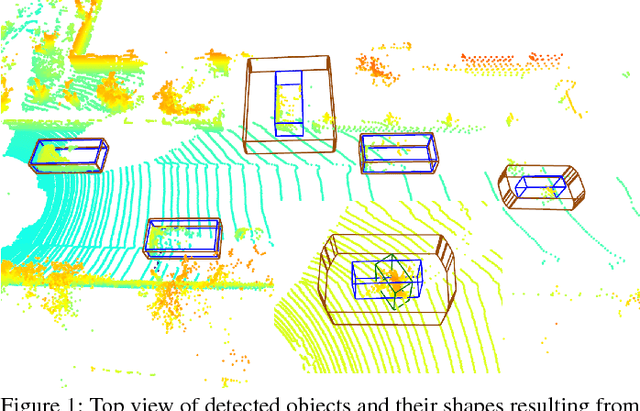
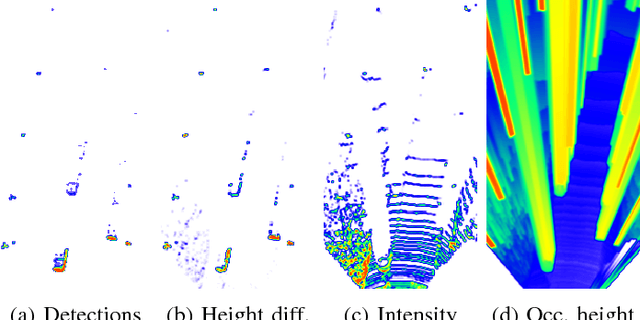
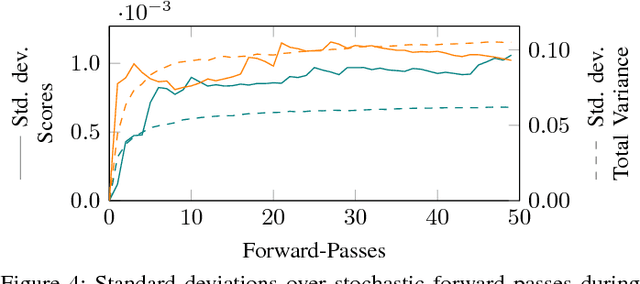
We propose a deep convolutional object detector for automated driving applications that also estimates classification, pose and shape uncertainty of each detected object. The input consists of a multi-layer grid map which is well-suited for sensor fusion, free-space estimation and machine learning. Based on the estimated pose and shape uncertainty we approximate object hulls with bounded collision probability which we find helpful for subsequent trajectory planning tasks. We train our models based on the KITTI object detection data set. In a quantitative and qualitative evaluation some models show a similar performance and superior robustness compared to previously developed object detectors. However, our evaluation also points to undesired data set properties which should be addressed when training data-driven models or creating new data sets.
Object Detection and Classification in Occupancy Grid Maps using Deep Convolutional Networks
Dec 05, 2018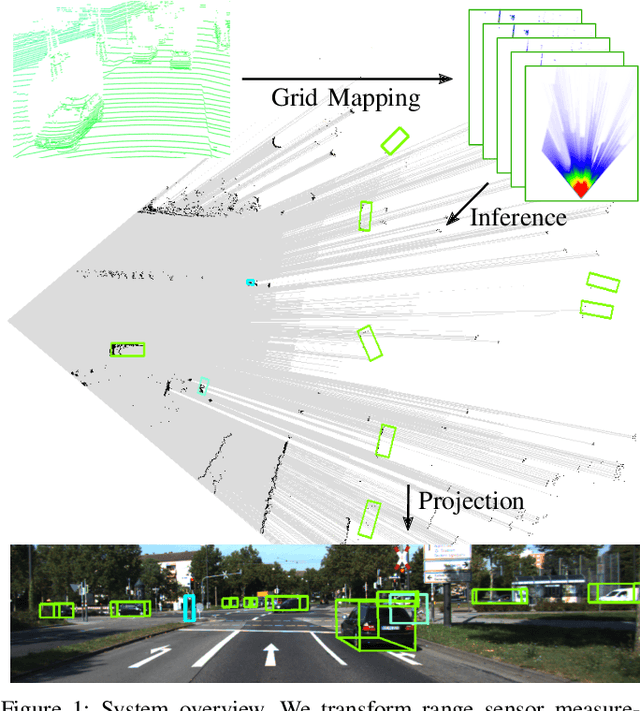
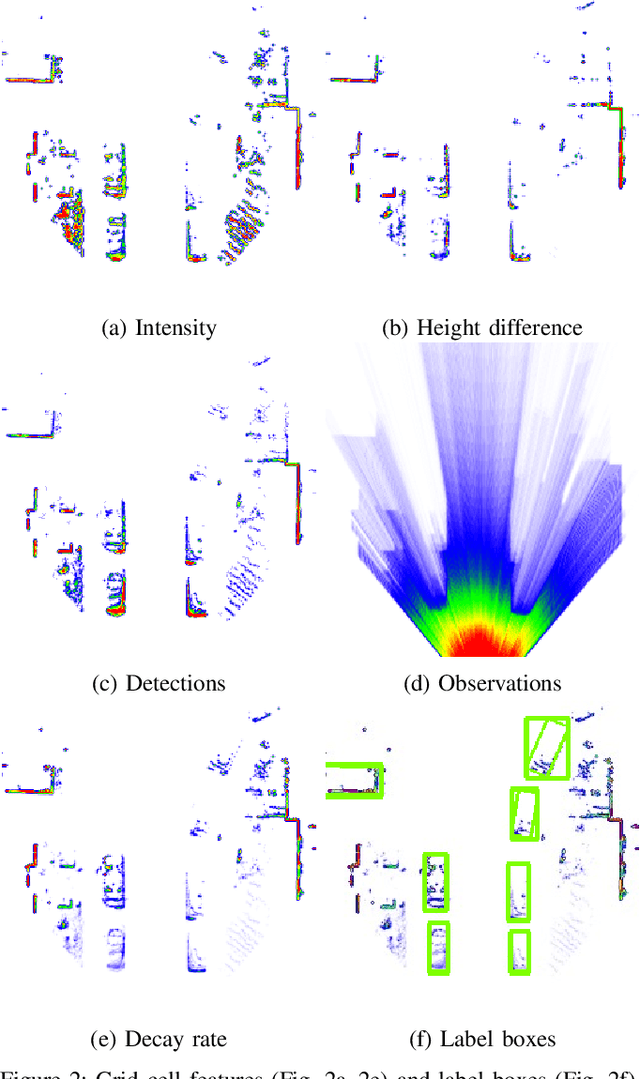
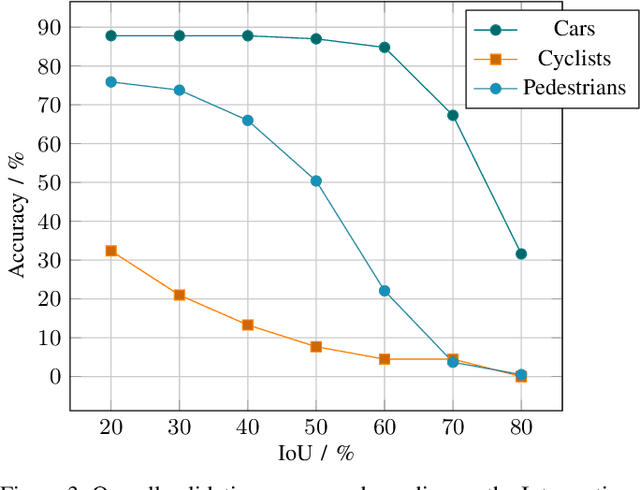

A detailed environment perception is a crucial component of automated vehicles. However, to deal with the amount of perceived information, we also require segmentation strategies. Based on a grid map environment representation, well-suited for sensor fusion, free-space estimation and machine learning, we detect and classify objects using deep convolutional neural networks. As input for our networks we use a multi-layer grid map efficiently encoding 3D range sensor information. The inference output consists of a list of rotated bounding boxes with associated semantic classes. We conduct extensive ablation studies, highlight important design considerations when using grid maps and evaluate our models on the KITTI Bird's Eye View benchmark. Qualitative and quantitative benchmark results show that we achieve robust detection and state of the art accuracy solely using top-view grid maps from range sensor data.
* 6 pages, 4 tables, 4 figures
Evidential Occupancy Grid Map Augmentation using Deep Learning
Dec 05, 2018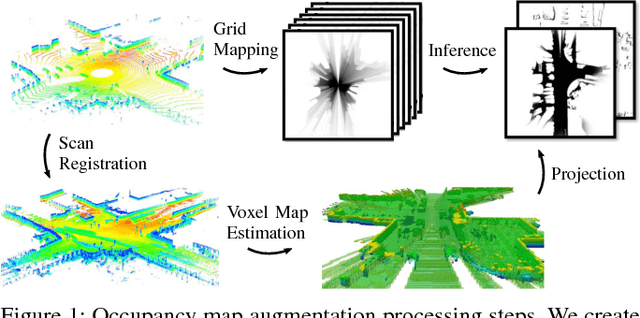

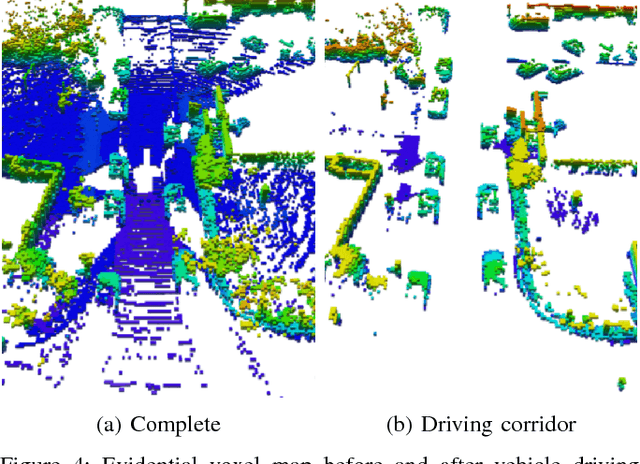
A detailed environment representation is a crucial component of automated vehicles. Using single range sensor scans, data is often too sparse and subject to occlusions. Therefore, we present a method to augment occupancy grid maps from single views to be similar to evidential occupancy maps acquired from different views using Deep Learning. To accomplish this, we estimate motion between subsequent range sensor measurements and create an evidential 3D voxel map in an extensive post-processing step. Within this voxel map, we explicitly model uncertainty using evidence theory and create a 2D projection using combination rules. As input for our neural networks, we use a multi-layer grid map consisting of the three features detections, transmissions and intensity, each for ground and non-ground measurements. Finally, we perform a quantitative and qualitative evaluation which shows that different network architectures accurately infer evidential measures in real-time.
* 6 pages, 5 figures
An Approach to Vehicle Trajectory Prediction Using Automatically Generated Traffic Maps
Jun 14, 2018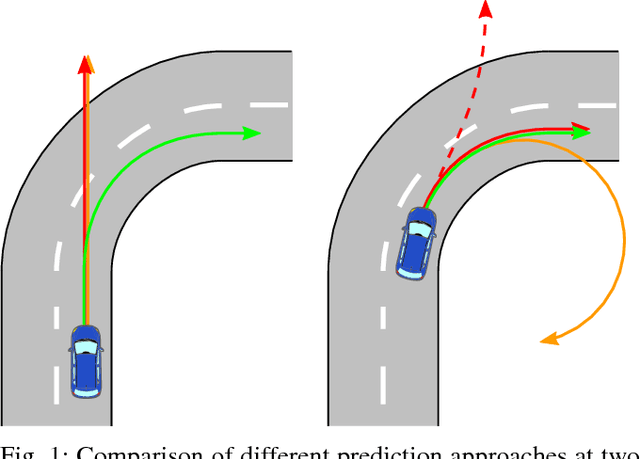

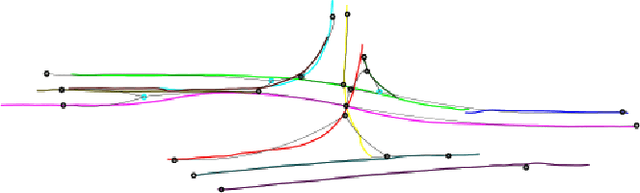
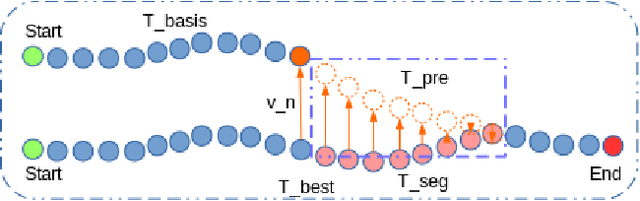
Trajectory and intention prediction of traffic participants is an important task in automated driving and crucial for safe interaction with the environment. In this paper, we present a new approach to vehicle trajectory prediction based on automatically generated maps containing statistical information about the behavior of traffic participants in a given area. These maps are generated based on trajectory observations using image processing and map matching techniques and contain all typical vehicle movements and probabilities in the considered area. Our prediction approach matches an observed trajectory to a behavior contained in the map and uses this information to generate a prediction. We evaluated our approach on a dataset containing over 14000 trajectories and found that it produces significantly more precise mid-term predictions compared to motion model-based prediction approaches.