 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeG-LBM:Generative Low-dimensional Background Model Estimation from Video Sequences
Mar 16, 2020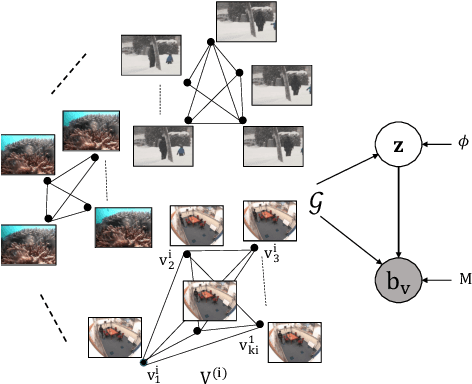
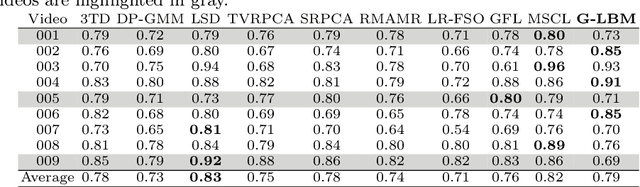
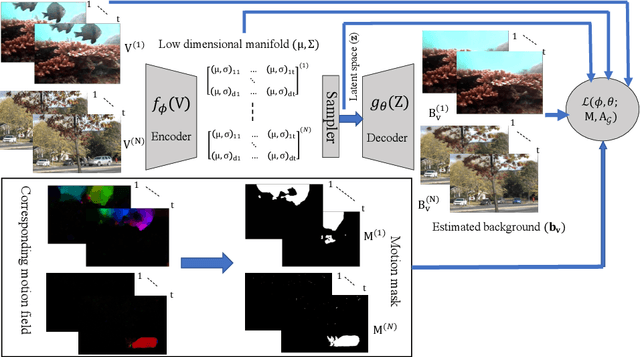
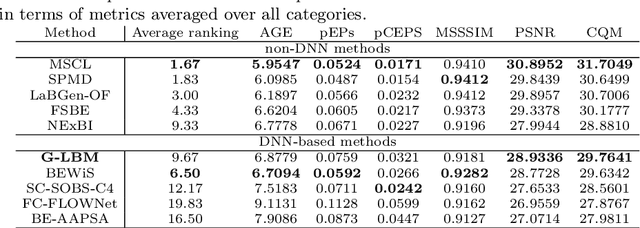
In this paper, we propose a computationally tractable and theoretically supported non-linear low-dimensional generative model to represent real-world data in the presence of noise and sparse outliers. The non-linear low-dimensional manifold discovery of data is done through describing a joint distribution over observations, and their low-dimensional representations (i.e. manifold coordinates). Our model, called generative low-dimensional background model (G-LBM) admits variational operations on the distribution of the manifold coordinates and simultaneously generates a low-rank structure of the latent manifold given the data. Therefore, our probabilistic model contains the intuition of the non-probabilistic low-dimensional manifold learning. G-LBM selects the intrinsic dimensionality of the underling manifold of the observations, and its probabilistic nature models the noise in the observation data. G-LBM has direct application in the background scenes model estimation from video sequences and we have evaluated its performance on SBMnet-2016 and BMC2012 datasets, where it achieved a performance higher or comparable to other state-of-the-art methods while being agnostic to the background scenes in videos. Besides, in challenges such as camera jitter and background motion, G-LBM is able to robustly estimate the background by effectively modeling the uncertainties in video observations in these scenarios.
Development of Use-specific High Performance Cyber-Nanomaterial Optical Detectors by Effective Choice of Machine Learning Algorithms
Jan 03, 2020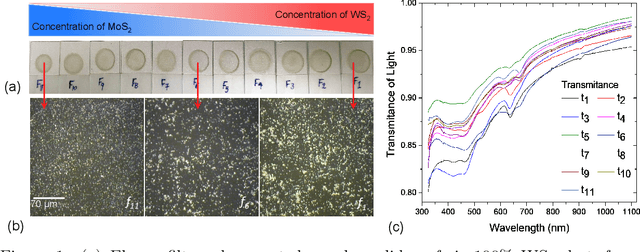
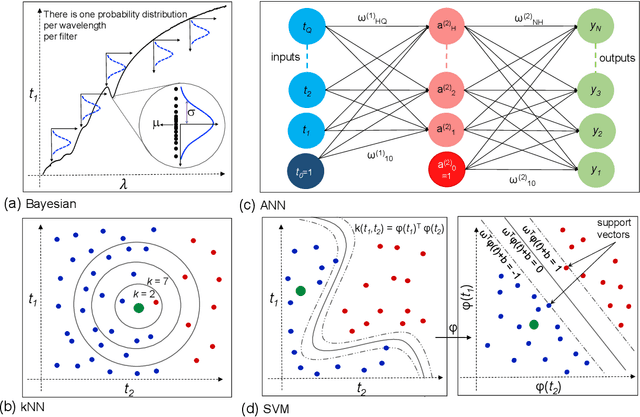
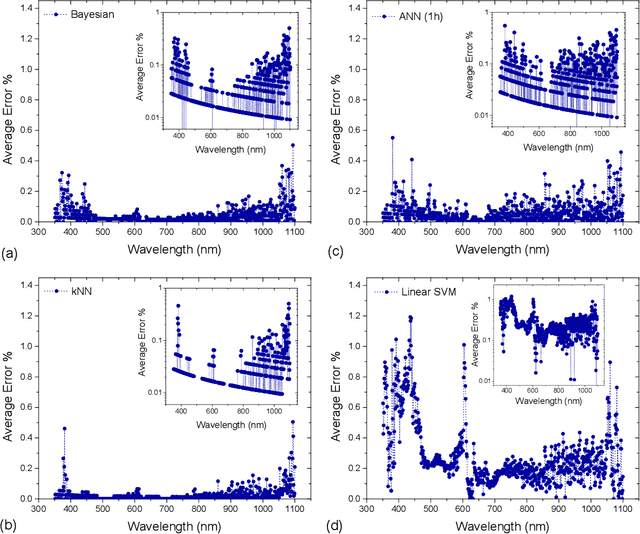
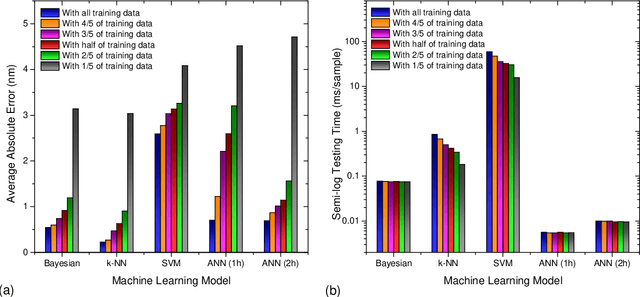
Due to their inherent variabilities,nanomaterial-based sensors are challenging to translate into real-world applications,where reliability/reproducibility is key.Recently we showed Bayesian inference can be employed on engineered variability in layered nanomaterial-based optical transmission filters to determine optical wavelengths with high accuracy/precision.In many practical applications the sensing cost/speed and long-term reliability can be equal or more important considerations.Though various machine learning tools are frequently used on sensor/detector networks to address these,nonetheless their effectiveness on nanomaterial-based sensors has not been explored.Here we show the best choice of ML algorithm in a cyber-nanomaterial detector is mainly determined by specific use considerations,e.g.,accuracy, computational cost,speed, and resilience against drifts/ageing effects.When sufficient data/computing resources are provided,highest sensing accuracy can be achieved by the kNN and Bayesian inference algorithms,but but can be computationally expensive for real-time applications.In contrast,artificial neural networks are computationally expensive to train,but provide the fastest result under testing conditions and remain reasonably accurate.When data is limited,SVMs perform well even with small training sets,while other algorithms show considerable reduction in accuracy if data is scarce,hence,setting a lower limit on the size of required training data.We show by tracking/modeling the long-term drifts of the detector performance over large (1year) period,it is possible to improve the predictive accuracy with no need for recalibration.Our research shows for the first time if the ML algorithm is chosen specific to use-case,low-cost solution-processed cyber-nanomaterial detectors can be practically implemented under diverse operational requirements,despite their inherent variabilities.
Target-Specific Action Classification for Automated Assessment of Human Motor Behavior from Video
Sep 20, 2019
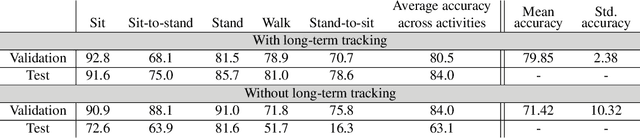
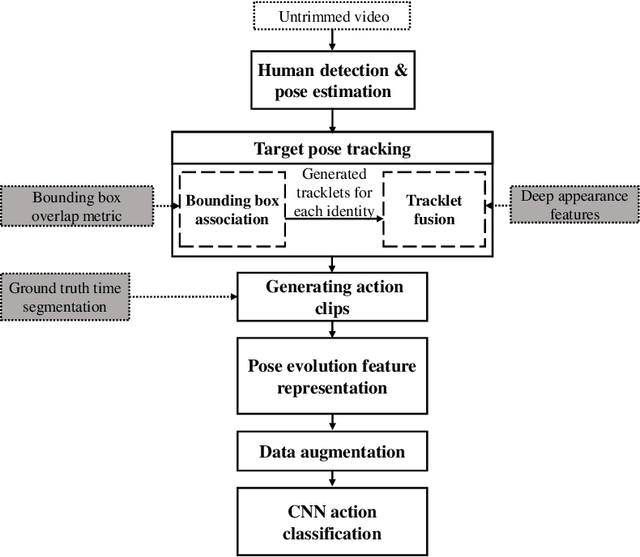
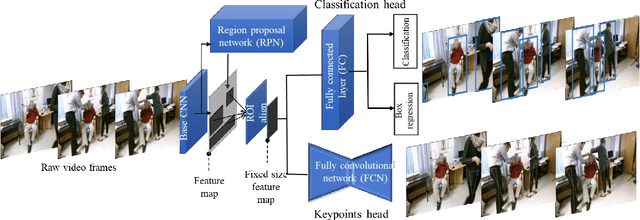
Objective monitoring and assessment of human motor behavior can improve the diagnosis and management of several medical conditions. Over the past decade, significant advances have been made in the use of wearable technology for continuously monitoring human motor behavior in free-living conditions. However, wearable technology remains ill-suited for applications which require monitoring and interpretation of complex motor behaviors (e.g. involving interactions with the environment). Recent advances in computer vision and deep learning have opened up new possibilities for extracting information from video recordings. In this paper, we present a hierarchical vision-based behavior phenotyping method for classification of basic human actions in video recordings performed using a single RGB camera. Our method addresses challenges associated with tracking multiple human actors and classification of actions in videos recorded in changing environments with different fields of view. We implement a cascaded pose tracker that uses temporal relationships between detections for short-term tracking and appearance-based tracklet fusion for long-term tracking. Furthermore, for action classification, we use pose evolution maps derived from the cascaded pose tracker as low-dimensional and interpretable representations of the movement sequences for training a convolutional neural network. The cascaded pose tracker achieves an average accuracy of 88\% in tracking the target human actor in our video recordings, and overall system achieves average test accuracy of 84\% for target-specific action classification in untrimmed video recordings.
Seeing Under the Cover: A Physics Guided Learning Approach for In-Bed Pose Estimation
Jul 17, 2019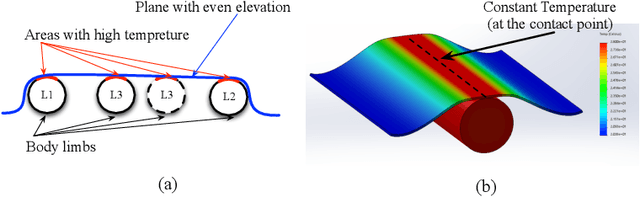
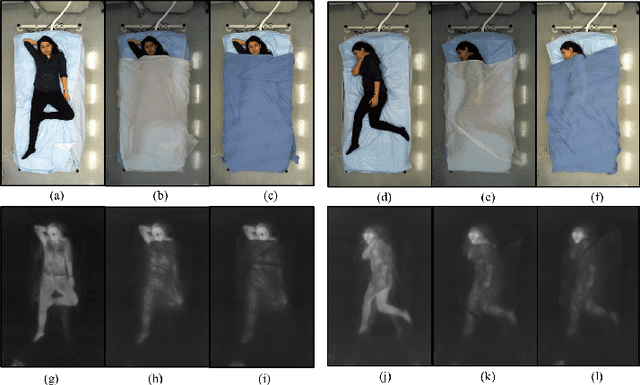
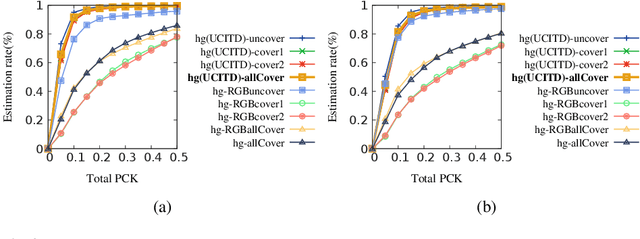
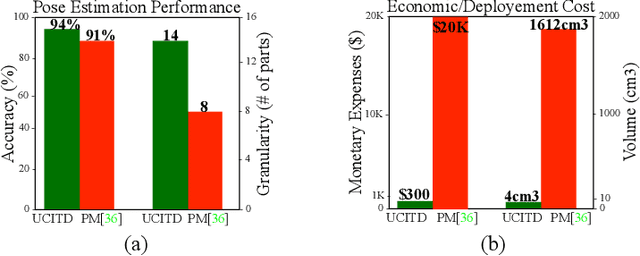
Human in-bed pose estimation has huge practical values in medical and healthcare applications yet still mainly relies on expensive pressure mapping (PM) solutions. In this paper, we introduce our novel physics inspired vision-based approach that addresses the challenging issues associated with the in-bed pose estimation problem including monitoring a fully covered person in complete darkness. We reformulated this problem using our proposed Under the Cover Imaging via Thermal Diffusion (UCITD) method to capture the high resolution pose information of the body even when it is fully covered by using a long wavelength IR technique. We proposed a physical hyperparameter concept through which we achieved high quality groundtruth pose labels in different modalities. A fully annotated in-bed pose dataset called Simultaneously-collected multimodal Lying Pose (SLP) is also formed/released with the same order of magnitude as most existing large-scale human pose datasets to support complex models' training and evaluation. A network trained from scratch on it and tested on two diverse settings, one in a living room and the other in a hospital room showed pose estimation performance of 99.5% and 95.7% in PCK0.2 standard, respectively. Moreover, in a multi-factor comparison with a state-of-the art in-bed pose monitoring solution based on PM, our solution showed significant superiority in all practical aspects by being 60 times cheaper, 300 times smaller, while having higher pose recognition granularity and accuracy.
Infant Contact-less Non-Nutritive Sucking Pattern Quantification via Facial Gesture Analysis
Jun 05, 2019
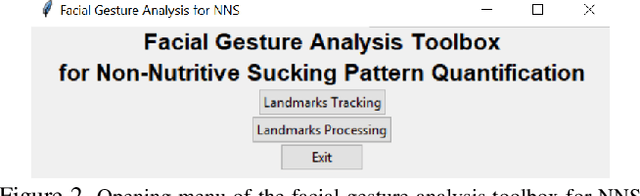
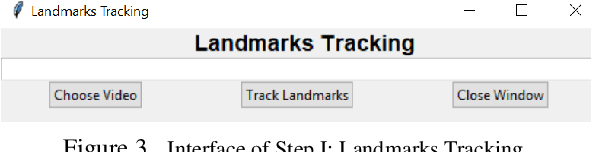
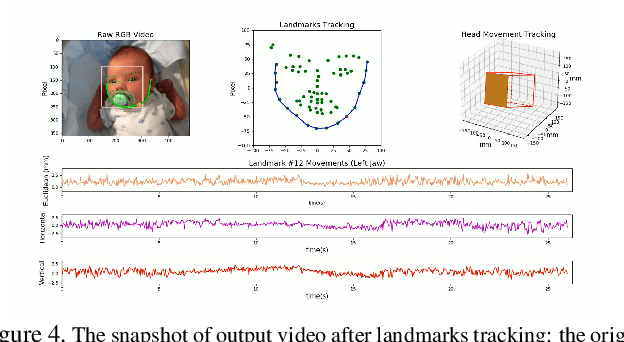
Non-nutritive sucking (NNS) is defined as the sucking action that occurs when a finger, pacifier, or other object is placed in the baby's mouth, but there is no nutrient delivered. In addition to providing a sense of safety, NNS even can be regarded as an indicator of infant's central nervous system development. The rich data, such as sucking frequency, the number of cycles, and their amplitude during baby's non-nutritive sucking is important clue for judging the brain development of infants or preterm infants. Nowadays most researchers are collecting NNS data by using some contact devices such as pressure transducers. However, such invasive contact will have a direct impact on the baby's natural sucking behavior, resulting in significant distortion in the collected data. Therefore, we propose a novel contact-less NNS data acquisition and quantification scheme, which leverages the facial landmarks tracking technology to extract the movement signals of baby's jaw from recorded baby's sucking video. Since completion of the sucking action requires a large amount of synchronous coordination and neural integration of the facial muscles and the cranial nerves, the facial muscle movement signals accompanying baby's sucking pacifier can indirectly replace the NNS signal. We have evaluated our method on videos collected from several infants during their NNS behaviors and we have achieved the quantified NNS patterns closely comparable to results from visual inspection as well as contact-based sensor readings.
DeepPBM: Deep Probabilistic Background Model Estimation from Video Sequences
Feb 03, 2019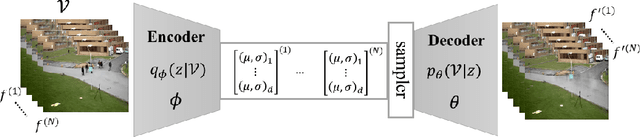
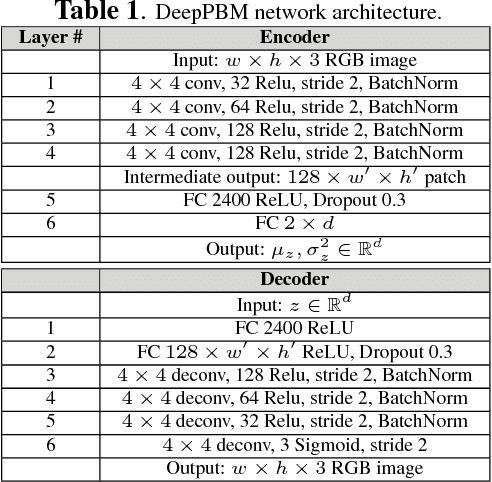
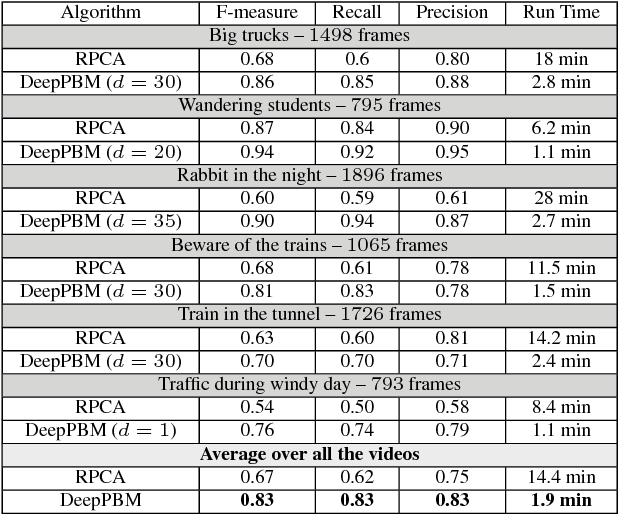

This paper presents a novel unsupervised probabilistic model estimation of visual background in video sequences using a variational autoencoder framework. Due to the redundant nature of the backgrounds in surveillance videos, visual information of the background can be compressed into a low-dimensional subspace in the encoder part of the variational autoencoder, while the highly variant information of its moving foreground gets filtered throughout its encoding-decoding process. Our deep probabilistic background model (DeepPBM) estimation approach is enabled by the power of deep neural networks in learning compressed representations of video frames and reconstructing them back to the original domain. We evaluated the performance of our DeepPBM in background subtraction on 9 surveillance videos from the background model challenge (BMC2012) dataset, and compared that with a standard subspace learning technique, robust principle component analysis (RPCA), which similarly estimates a deterministic low dimensional representation of the background in videos and is widely used for this application. Our method outperforms RPCA on BMC2012 dataset with 23% in average in F-measure score, emphasizing that background subtraction using the trained model can be done in more than 10 times faster.
Indoor GeoNet: Weakly Supervised Hybrid Learning for Depth and Pose Estimation
Nov 19, 2018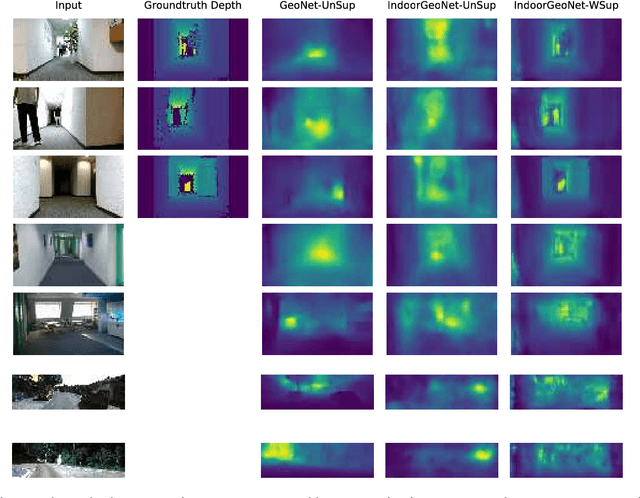



Humans naturally perceive a 3D scene in front of them through accumulation of information obtained from multiple interconnected projections of the scene and by interpreting their correspondence. This phenomenon has inspired artificial intelligence models to extract the depth and view angle of the observed scene by modeling the correspondence between different views of that scene. Our paper is built upon previous works in the field of unsupervised depth and relative camera pose estimation from temporal consecutive video frames using deep learning (DL) models. Our approach uses a hybrid learning framework introduced in a recent work called GeoNet, which leverages geometric constraints in the 3D scenes to synthesize a novel view from intermediate DL-based predicted depth and relative pose. However, the state-of-the-art unsupervised depth and pose estimation DL models are exclusively trained/tested on a few available outdoor scene datasets and we have shown they are hardly transferable to new scenes, especially from indoor environments, in which estimation requires higher precision and dealing with probable occlusions. This paper introduces "Indoor GeoNet", a weakly supervised depth and camera pose estimation model targeted for indoor scenes. In Indoor GeoNet, we take advantage of the availability of indoor RGBD datasets collected by human or robot navigators, and added partial (i.e. weak) supervision in depth training into the model. Experimental results showed that our model effectively generalizes to new scenes from different buildings. Indoor GeoNet demonstrated significant depth and pose estimation error reduction when compared to the original GeoNet, while showing 3 times more reconstruction accuracy in synthesizing novel views in indoor environments.
Facial Expression and Peripheral Physiology Fusion to Decode Individualized Affective Experience
Nov 18, 2018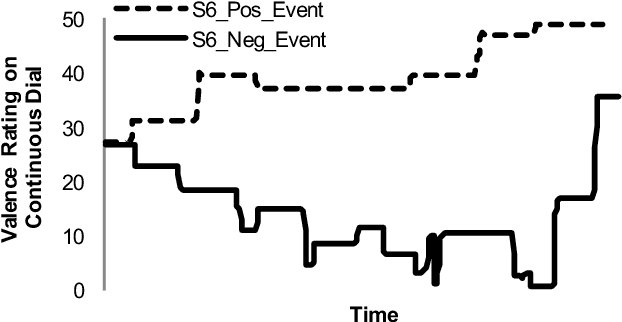
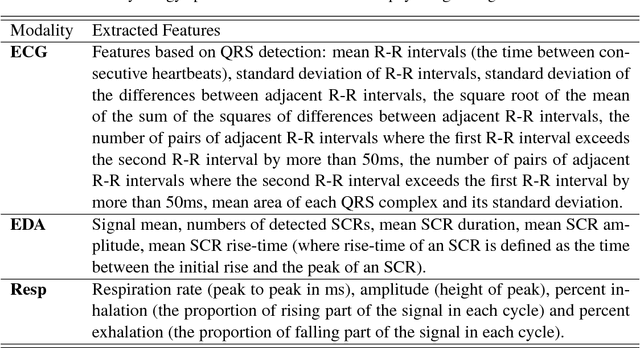
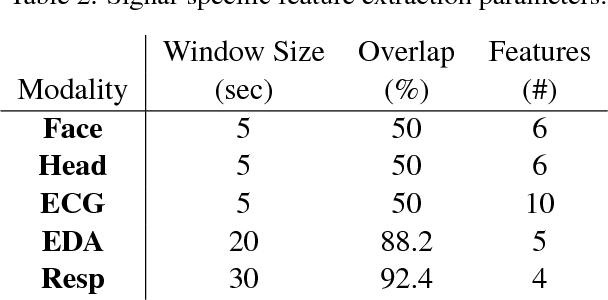
In this paper, we present a multimodal approach to simultaneously analyze facial movements and several peripheral physiological signals to decode individualized affective experiences under positive and negative emotional contexts, while considering their personalized resting dynamics. We propose a person-specific recurrence network to quantify the dynamics present in the person's facial movements and physiological data. Facial movement is represented using a robust head vs. 3D face landmark localization and tracking approach, and physiological data are processed by extracting known attributes related to the underlying affective experience. The dynamical coupling between different input modalities is then assessed through the extraction of several complex recurrent network metrics. Inference models are then trained using these metrics as features to predict individual's affective experience in a given context, after their resting dynamics are excluded from their response. We validated our approach using a multimodal dataset consists of (i) facial videos and (ii) several peripheral physiological signals, synchronously recorded from 12 participants while watching 4 emotion-eliciting video-based stimuli. The affective experience prediction results signified that our multimodal fusion method improves the prediction accuracy up to 19% when compared to the prediction using only one or a subset of the input modalities. Furthermore, we gained prediction improvement for affective experience by considering the effect of individualized resting dynamics.
A Semi-Supervised Data Augmentation Approach using 3D Graphical Engines
Sep 28, 2018



Deep learning approaches have been rapidly adopted across a wide range of fields because of their accuracy and flexibility, but require large labeled training datasets. This presents a fundamental problem for applications with limited, expensive, or private data (i.e. small data), such as human pose and behavior estimation/tracking which could be highly personalized. In this paper, we present a semi-supervised data augmentation approach that can synthesize large scale labeled training datasets using 3D graphical engines based on a physically-valid low dimensional pose descriptor. To evaluate the performance of our synthesized datasets in training deep learning-based models, we generated a large synthetic human pose dataset, called ScanAva using 3D scans of only 7 individuals based on our proposed augmentation approach. A state-of-the-art human pose estimation deep learning model then was trained from scratch using our ScanAva dataset and could achieve the pose estimation accuracy of 91.2% at PCK0.5 criteria after applying an efficient domain adaptation on the synthetic images, in which its pose estimation accuracy was comparable to the same model trained on large scale pose data from real humans such as MPII dataset and much higher than the model trained on other synthetic human dataset such as SURREAL.
Inner Space Preserving Generative Pose Machine
Aug 06, 2018



Image-based generative methods, such as generative adversarial networks (GANs) have already been able to generate realistic images with much context control, specially when they are conditioned. However, most successful frameworks share a common procedure which performs an image-to-image translation with pose of figures in the image untouched. When the objective is reposing a figure in an image while preserving the rest of the image, the state-of-the-art mainly assumes a single rigid body with simple background and limited pose shift, which can hardly be extended to the images under normal settings. In this paper, we introduce an image "inner space" preserving model that assigns an interpretable low-dimensional pose descriptor (LDPD) to an articulated figure in the image. Figure reposing is then generated by passing the LDPD and the original image through multi-stage augmented hourglass networks in a conditional GAN structure, called inner space preserving generative pose machine (ISP-GPM). We evaluated ISP-GPM on reposing human figures, which are highly articulated with versatile variations. Test of a state-of-the-art pose estimator on our reposed dataset gave an accuracy over 80% on PCK0.5 metric. The results also elucidated that our ISP-GPM is able to preserve the background with high accuracy while reasonably recovering the area blocked by the figure to be reposed.
* http://www.northeastern.edu/ostadabbas/2018/07/23/inner-space-preserving-generative-pose-machine/