 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLive Stream Temporally Embedded 3D Human Body Pose and Shape Estimation
Jul 25, 2022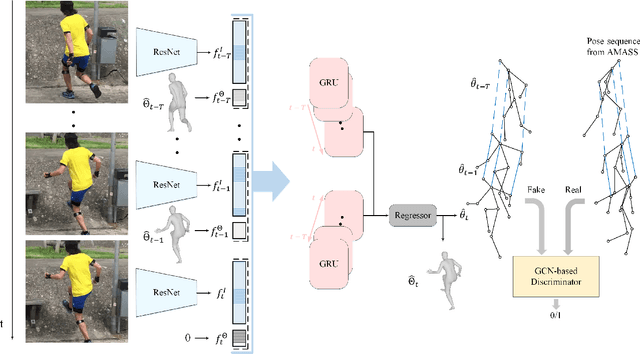

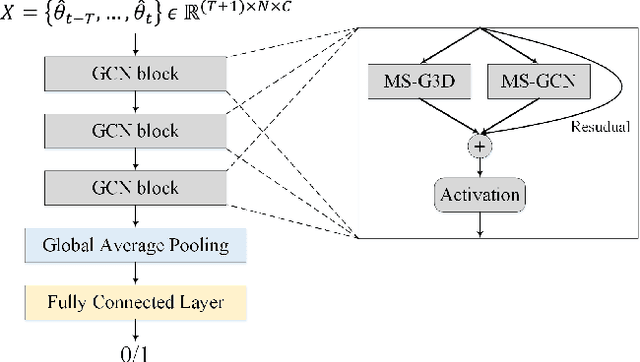
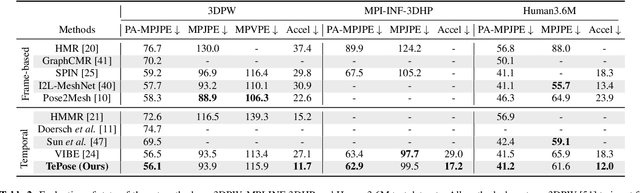
3D Human body pose and shape estimation within a temporal sequence can be quite critical for understanding human behavior. Despite the significant progress in human pose estimation in the recent years, which are often based on single images or videos, human motion estimation on live stream videos is still a rarely-touched area considering its special requirements for real-time output and temporal consistency. To address this problem, we present a temporally embedded 3D human body pose and shape estimation (TePose) method to improve the accuracy and temporal consistency of pose estimation in live stream videos. TePose uses previous predictions as a bridge to feedback the error for better estimation in the current frame and to learn the correspondence between data frames and predictions in the history. A multi-scale spatio-temporal graph convolutional network is presented as the motion discriminator for adversarial training using datasets without any 3D labeling. We propose a sequential data loading strategy to meet the special start-to-end data processing requirement of live stream. We demonstrate the importance of each proposed module with extensive experiments. The results show the effectiveness of TePose on widely-used human pose benchmarks with state-of-the-art performance.
Computer Vision to the Rescue: Infant Postural Symmetry Estimation from Incongruent Annotations
Jul 19, 2022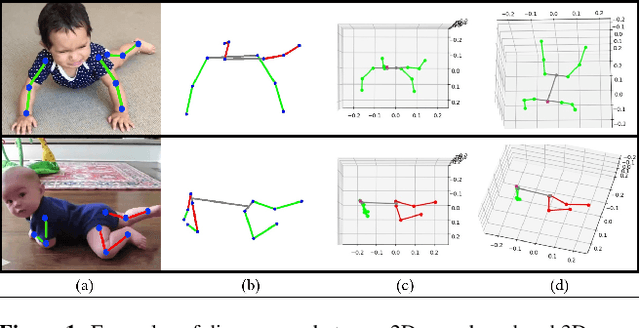

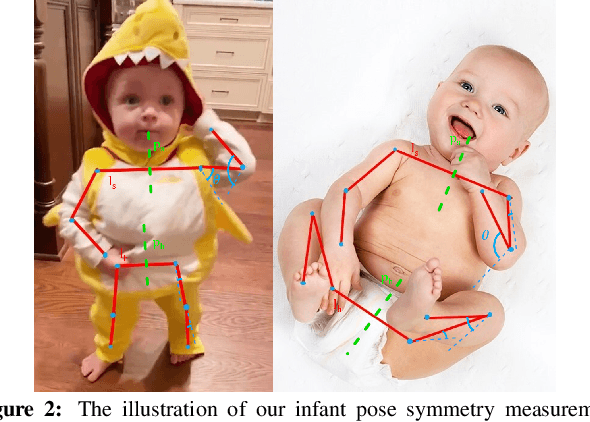
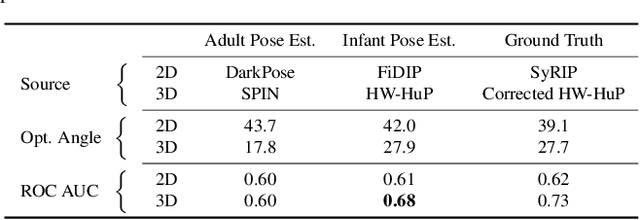
Bilateral postural symmetry plays a key role as a potential risk marker for autism spectrum disorder (ASD) and as a symptom of congenital muscular torticollis (CMT) in infants, but current methods of assessing symmetry require laborious clinical expert assessments. In this paper, we develop a computer vision based infant symmetry assessment system, leveraging 3D human pose estimation for infants. Evaluation and calibration of our system against ground truth assessments is complicated by our findings from a survey of human ratings of angle and symmetry, that such ratings exhibit low inter-rater reliability. To rectify this, we develop a Bayesian estimator of the ground truth derived from a probabilistic graphical model of fallible human raters. We show that the 3D infant pose estimation model can achieve 68% area under the receiver operating characteristic curve performance in predicting the Bayesian aggregate labels, compared to only 61% from a 2D infant pose estimation model and 60% from a 3D adult pose estimation model, highlighting the importance of 3D poses and infant domain knowledge in assessing infant body symmetry. Our survey analysis also suggests that human ratings are susceptible to higher levels of bias and inconsistency, and hence our final 3D pose-based symmetry assessment system is calibrated but not directly supervised by Bayesian aggregate human ratings, yielding higher levels of consistency and lower levels of inter-limb assessment bias.
Pressure Eye: In-bed Contact Pressure Estimation via Contact-less Imaging
Jan 27, 2022
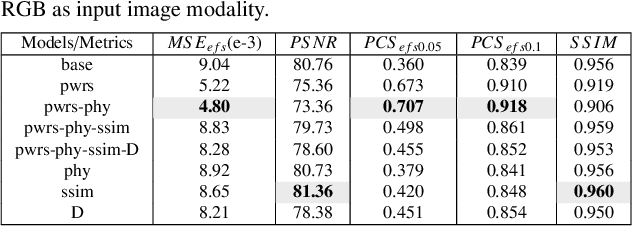
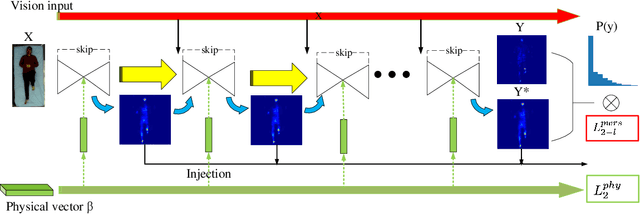
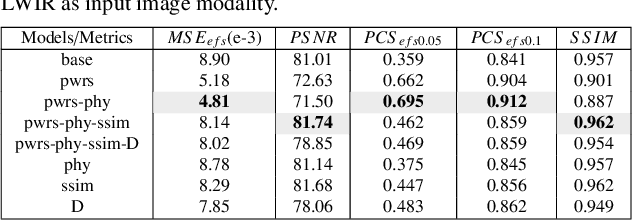
Computer vision has achieved great success in interpreting semantic meanings from images, yet estimating underlying (non-visual) physical properties of an object is often limited to their bulk values rather than reconstructing a dense map. In this work, we present our pressure eye (PEye) approach to estimate contact pressure between a human body and the surface she is lying on with high resolution from vision signals directly. PEye approach could ultimately enable the prediction and early detection of pressure ulcers in bed-bound patients, that currently depends on the use of expensive pressure mats. Our PEye network is configured in a dual encoding shared decoding form to fuse visual cues and some relevant physical parameters in order to reconstruct high resolution pressure maps (PMs). We also present a pixel-wise resampling approach based on Naive Bayes assumption to further enhance the PM regression performance. A percentage of correct sensing (PCS) tailored for sensing estimation accuracy evaluation is also proposed which provides another perspective for performance evaluation under varying error tolerances. We tested our approach via a series of extensive experiments using multimodal sensing technologies to collect data from 102 subjects while lying on a bed. The individual's high resolution contact pressure data could be estimated from their RGB or long wavelength infrared (LWIR) images with 91.8% and 91.2% estimation accuracies in $PCS_{efs0.1}$ criteria, superior to state-of-the-art methods in the related image regression/translation tasks.
A Review on Human Pose Estimation
Oct 13, 2021



The phenomenon of Human Pose Estimation (HPE) is a problem that has been explored over the years, particularly in computer vision. But what exactly is it? To answer this, the concept of a pose must first be understood. Pose can be defined as the arrangement of human joints in a specific manner. Therefore, we can define the problem of Human Pose Estimation as the localization of human joints or predefined landmarks in images and videos. There are several types of pose estimation, including body, face, and hand, as well as many aspects to it. This paper will cover them, starting with the classical approaches to HPE to the Deep Learning based models.
Interpreting Face Inference Models using Hierarchical Network Dissection
Aug 23, 2021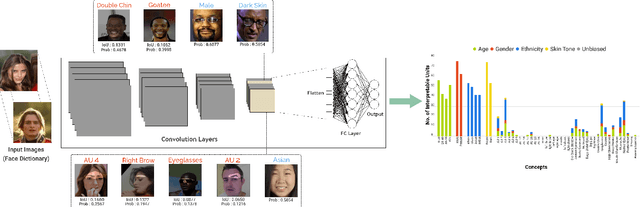

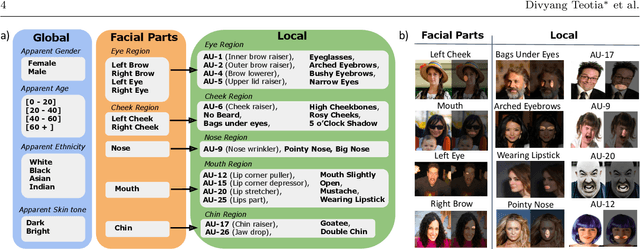
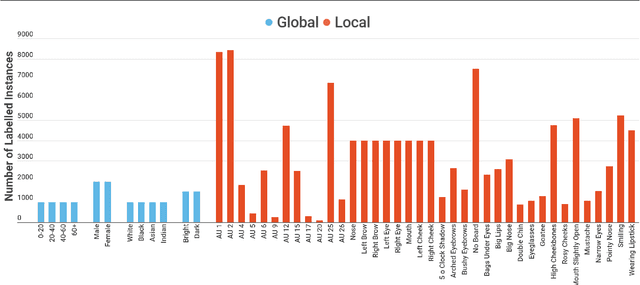
This paper presents Hierarchical Network Dissection, a general pipeline to interpret the internal representation of face-centric inference models. Using a probabilistic formulation, Hierarchical Network Dissection pairs units of the model with concepts in our "Face Dictionary" (a collection of facial concepts with corresponding sample images). Our pipeline is inspired by Network Dissection, a popular interpretability model for object-centric and scene-centric models. However, our formulation allows to deal with two important challenges of face-centric models that Network Dissection cannot address: (1) spacial overlap of concepts: there are different facial concepts that simultaneously occur in the same region of the image, like "nose" (facial part) and "pointy nose" (facial attribute); and (2) global concepts: there are units with affinity to concepts that do not refer to specific locations of the face (e.g. apparent age). To validate the effectiveness of our unit-concept pairing formulation, we first conduct controlled experiments on biased data. These experiments illustrate how Hierarchical Network Dissection can be used to discover bias in the training data. Then, we dissect different face-centric inference models trained on widely-used facial datasets. The results show models trained for different tasks have different internal representations. Furthermore, the interpretability results reveal some biases in the training data and some interesting characteristics of the face-centric inference tasks.
Dynamical Deep Generative Latent Modeling of 3D Skeletal Motion
Jun 18, 2021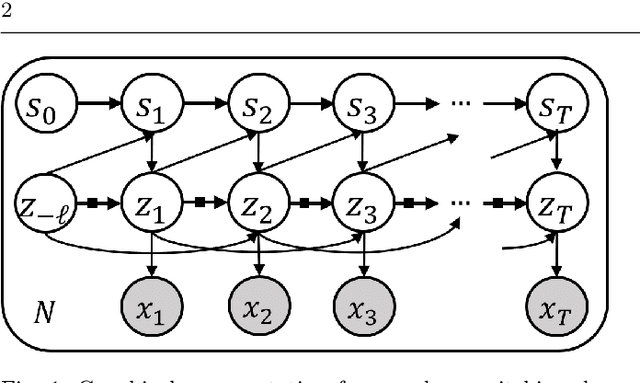
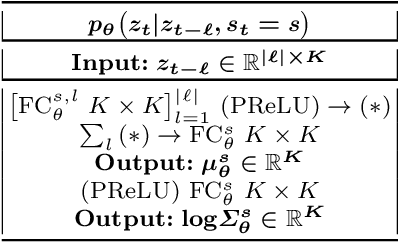
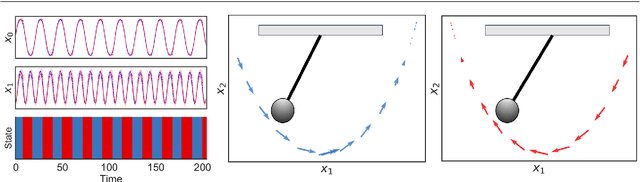
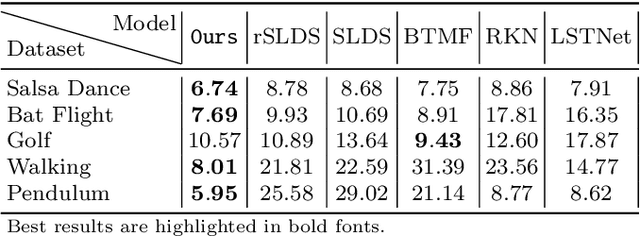
In this paper, we propose a Bayesian switching dynamical model for segmentation of 3D pose data over time that uncovers interpretable patterns in the data and is generative. Our model decomposes highly correlated skeleton data into a set of few spatial basis of switching temporal processes in a low-dimensional latent framework. We parameterize these temporal processes with regard to a switching deep vector autoregressive prior in order to accommodate both multimodal and higher-order nonlinear inter-dependencies. This results in a dynamical deep generative latent model that parses the meaningful intrinsic states in the dynamics of 3D pose data using approximate variational inference, and enables a realistic low-level dynamical generation and segmentation of complex skeleton movements. Our experiments on four biological motion data containing bat flight, salsa dance, walking, and golf datasets substantiate superior performance of our model in comparison with the state-of-the-art methods.
Heuristic Weakly Supervised 3D Human Pose Estimation in Novel Contexts without Any 3D Pose Ground Truth
May 23, 2021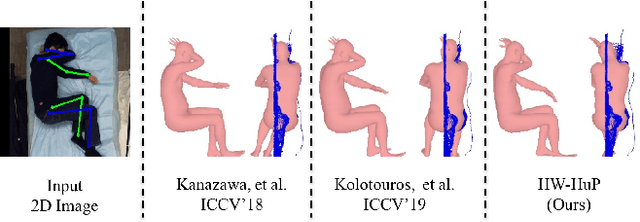
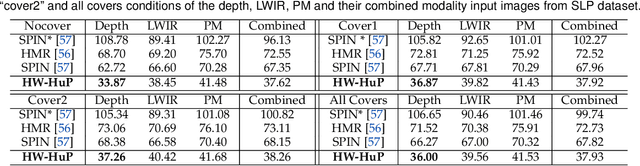
Monocular 3D human pose estimation from a single RGB image has received a lot attentions in the past few year. Pose inference models with competitive performance however require supervision with 3D pose ground truth data or at least known pose priors in their target domain. Yet, these data requirements in many real-world applications with data collection constraints may not be achievable. In this paper, we present a heuristic weakly supervised solution, called HW-HuP to estimate 3D human pose in contexts that no ground truth 3D data is accessible, even for fine-tuning. HW-HuP learns partial pose priors from public 3D human pose datasets and uses easy-to-access observations from the target domain to iteratively estimate 3D human pose and shape in an optimization and regression hybrid cycle. In our design, depth data as an auxiliary information is employed as weak supervision during training, yet it is not needed for the inference. We evaluate HW-HuP performance qualitatively on datasets of both in-bed human and infant poses, where no ground truth 3D pose is provided neither any target prior. We also test HW-HuP performance quantitatively on a publicly available motion capture dataset against the 3D ground truth. HW-HuP is also able to be extended to other input modalities for pose estimation tasks especially under adverse vision conditions, such as occlusion or full darkness. On the Human3.6M benchmark, HW-HuP shows 104.1mm in MPJPE and 50.4mm in PA MPJPE, comparable to the existing state-of-the-art approaches that benefit from full 3D pose supervision.
Adapted Human Pose: Monocular 3D Human Pose Estimation with Zero Real 3D Pose Data
May 23, 2021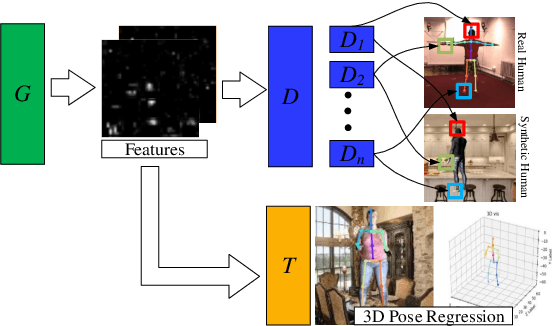
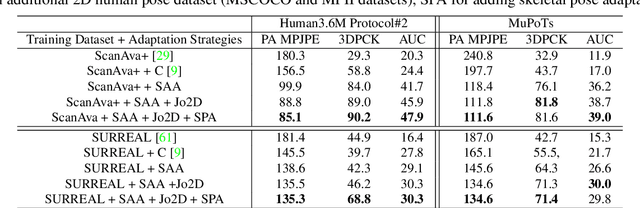
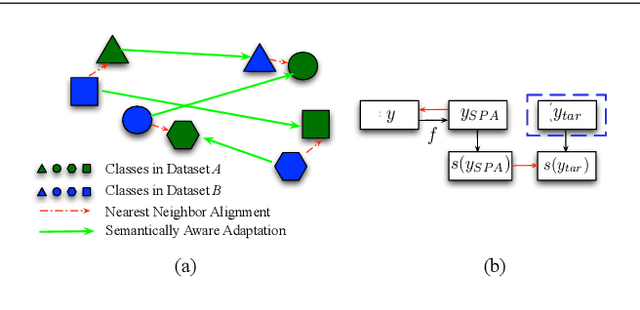
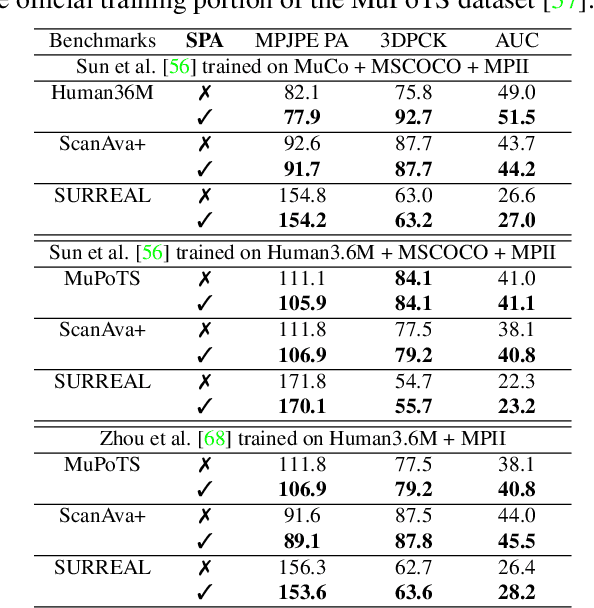
The ultimate goal for an inference model is to be robust and functional in real life applications. However, training vs. test data domain gaps often negatively affect model performance. This issue is especially critical for the monocular 3D human pose estimation problem, in which 3D human data is often collected in a controlled lab setting. In this paper, we focus on alleviating the negative effect of domain shift by presenting our adapted human pose (AHuP) approach that addresses adaptation problems in both appearance and pose spaces. AHuP is built around a practical assumption that in real applications, data from target domain could be inaccessible or only limited information can be acquired. We illustrate the 3D pose estimation performance of AHuP in two scenarios. First, when source and target data differ significantly in both appearance and pose spaces, in which we learn from synthetic 3D human data (with zero real 3D human data) and show comparable performance with the state-of-the-art 3D pose estimation models that have full access to the real 3D human pose benchmarks for training. Second, when source and target datasets differ mainly in the pose space, in which AHuP approach can be applied to further improve the performance of the state-of-the-art models when tested on the datasets different from their training dataset.
Infant Pose Learning with Small Data
Oct 13, 2020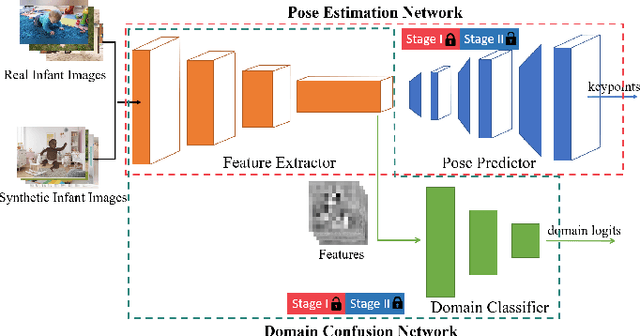
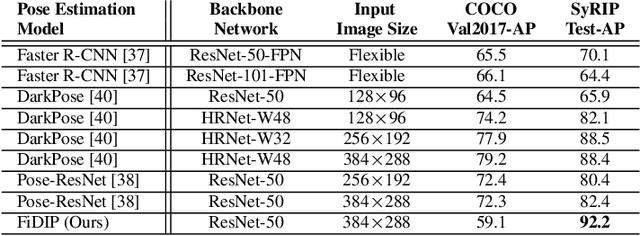

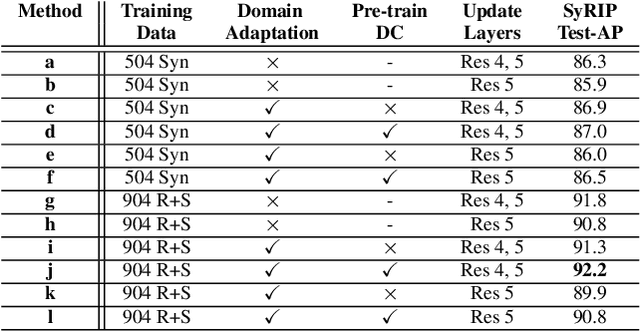
With the increasing maturity of the human pose estimation domain, its applications have become more and more broaden. Yet, the state-of-the-art pose estimation models performance degrades significantly in the applications that include novel subjects or poses, such as infants with their unique movements. Infant motion analysis is a topic with critical importance in child health and developmental studies. However, models trained on large-scale adult pose datasets are barely successful in estimating infant poses due to significant differences in their body ratio and the versatility of poses they can take compared to adults. Moreover, the privacy and security considerations hinder the availability of enough infant images required for training a robust pose estimation model from scratch. Here, we propose a fine-tuned domain-adapted infant pose (FiDIP) estimation model, that transfers the knowledge of adult poses into estimating infant pose with the supervision of a domain adaptation technique on a mixed real and synthetic infant pose dataset. In developing FiDIP, we also built a synthetic and real infant pose (SyRIP) dataset with diverse and fully-annotated real infant images and generated synthetic infant images. We demonstrated that our FiDIP model outperforms other state-of-the-art human pose estimation model for the infant pose estimation, with the mean average precision (AP) as high as 92.2.
Deep Switching Auto-Regressive Factorization:Application to Time Series Forecasting
Sep 10, 2020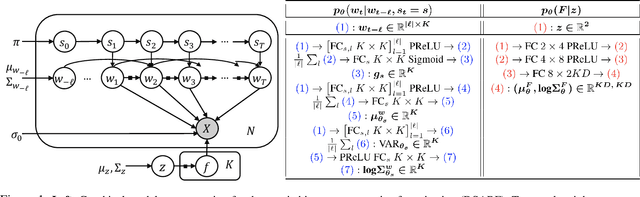
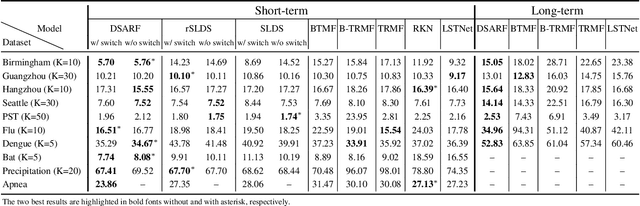
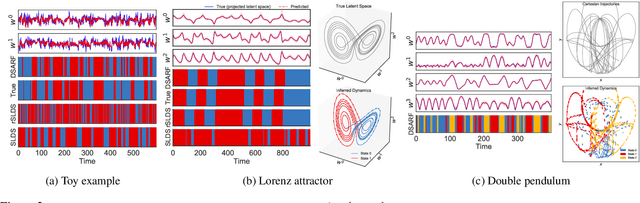
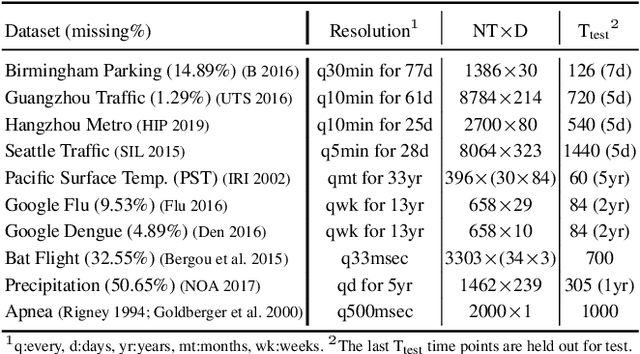
We introduce deep switching auto-regressive factorization (DSARF), a deep generative model for spatio-temporal data with the capability to unravel recurring patterns in the data and perform robust short- and long-term predictions. Similar to other factor analysis methods, DSARF approximates high dimensional data by a product between time dependent weights and spatially dependent factors. These weights and factors are in turn represented in terms of lower dimensional latent variables that are inferred using stochastic variational inference. DSARF is different from the state-of-the-art techniques in that it parameterizes the weights in terms of a deep switching vector auto-regressive likelihood governed with a Markovian prior, which is able to capture the non-linear inter-dependencies among weights to characterize multimodal temporal dynamics. This results in a flexible hierarchical deep generative factor analysis model that can be extended to (i) provide a collection of potentially interpretable states abstracted from the process dynamics, and (ii) perform short- and long-term vector time series prediction in a complex multi-relational setting. Our extensive experiments, which include simulated data and real data from a wide range of applications such as climate change, weather forecasting, traffic, infectious disease spread and nonlinear physical systems attest the superior performance of DSARF in terms of long- and short-term prediction error, when compared with the state-of-the-art methods.