 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Optimization for Categorical and Category-Specific Continuous Inputs
Nov 28, 2019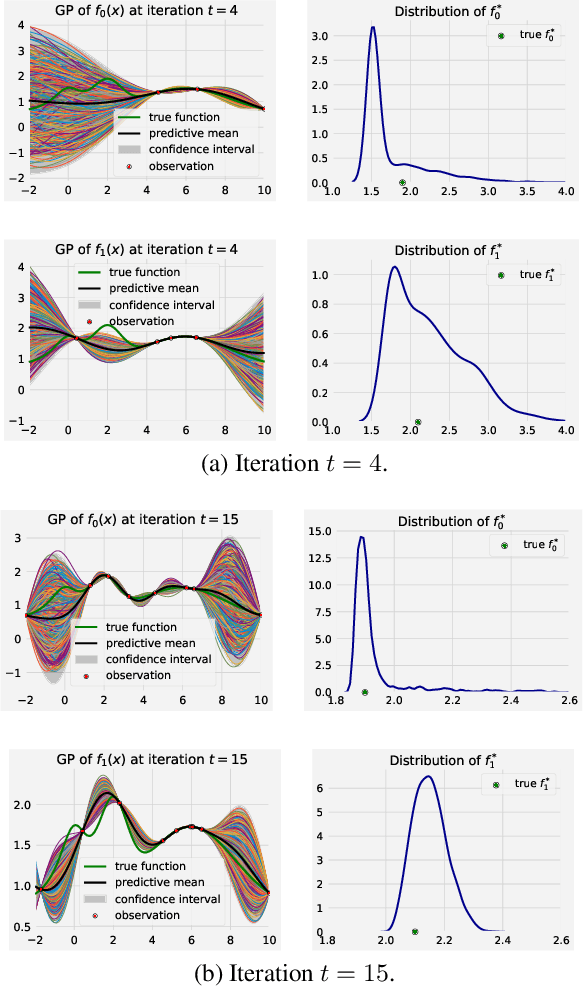
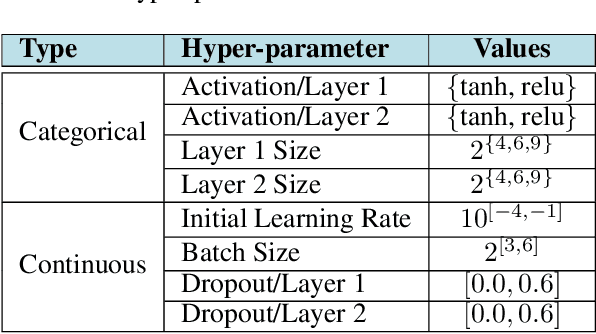
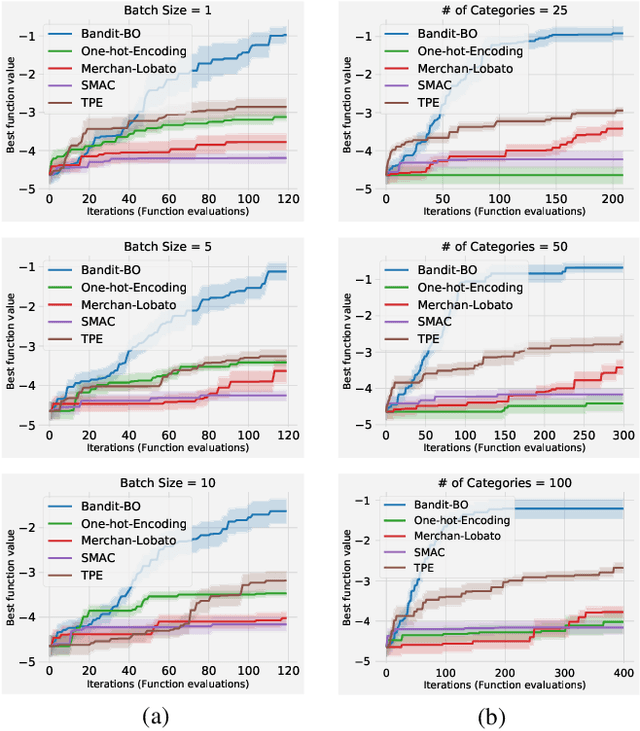
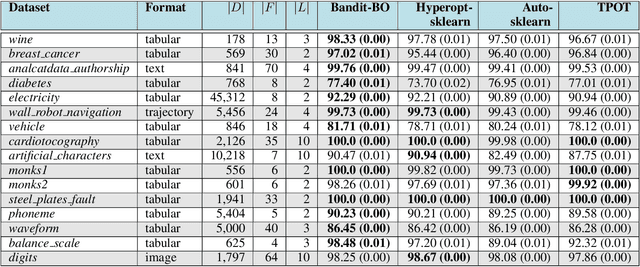
Many real-world functions are defined over both categorical and category-specific continuous variables and thus cannot be optimized by traditional Bayesian optimization (BO) methods. To optimize such functions, we propose a new method that formulates the problem as a multi-armed bandit problem, wherein each category corresponds to an arm with its reward distribution centered around the optimum of the objective function in continuous variables. Our goal is to identify the best arm and the maximizer of the corresponding continuous function simultaneously. Our algorithm uses a Thompson sampling scheme that helps connecting both multi-arm bandit and BO in a unified framework. We extend our method to batch BO to allow parallel optimization when multiple resources are available. We theoretically analyze our method for convergence and prove sub-linear regret bounds. We perform a variety of experiments: optimization of several benchmark functions, hyper-parameter tuning of a neural network, and automatic selection of the best machine learning model along with its optimal hyper-parameters (a.k.a automated machine learning). Comparisons with other methods demonstrate the effectiveness of our proposed method.
Trading Convergence Rate with Computational Budget in High Dimensional Bayesian Optimization
Nov 27, 2019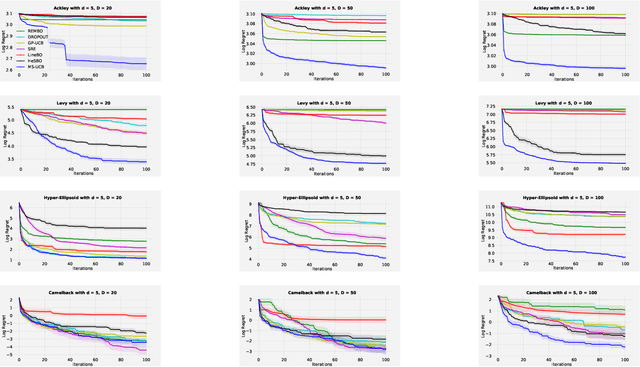
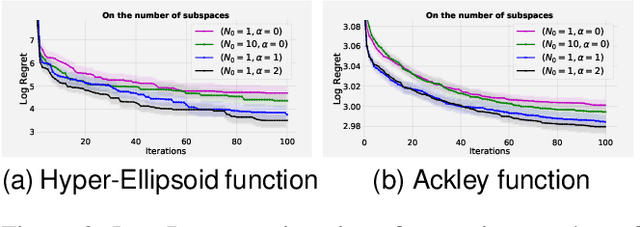
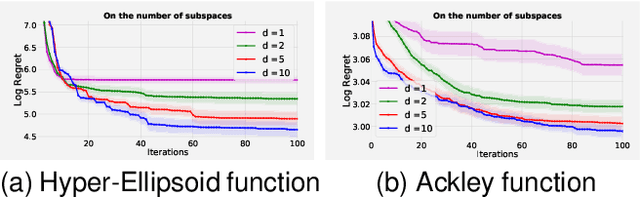
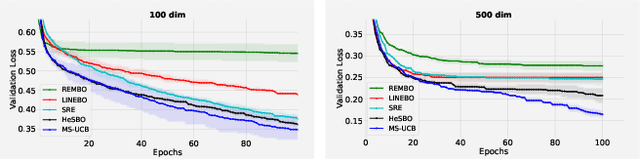
Scaling Bayesian optimisation (BO) to high-dimensional search spaces is a active and open research problems particularly when no assumptions are made on function structure. The main reason is that at each iteration, BO requires to find global maximisation of acquisition function, which itself is a non-convex optimization problem in the original search space. With growing dimensions, the computational budget for this maximisation gets increasingly short leading to inaccurate solution of the maximisation. This inaccuracy adversely affects both the convergence and the efficiency of BO. We propose a novel approach where the acquisition function only requires maximisation on a discrete set of low dimensional subspaces embedded in the original high-dimensional search space. Our method is free of any low dimensional structure assumption on the function unlike many recent high-dimensional BO methods. Optimising acquisition function in low dimensional subspaces allows our method to obtain accurate solutions within limited computational budget. We show that in spite of this convenience, our algorithm remains convergent. In particular, cumulative regret of our algorithm only grows sub-linearly with the number of iterations. More importantly, as evident from our regret bounds, our algorithm provides a way to trade the convergence rate with the number of subspaces used in the optimisation. Finally, when the number of subspaces is "sufficiently large", our algorithm's cumulative regret is at most $\mathcal{O}^{*}(\sqrt{T\gamma_T})$ as opposed to $\mathcal{O}^{*}(\sqrt{DT\gamma_T})$ for the GP-UCB of Srinivas et al. (2012), reducing a crucial factor $\sqrt{D}$ where $D$ being the dimensional number of input space.
Bayesian Optimization with Unknown Search Space
Oct 29, 2019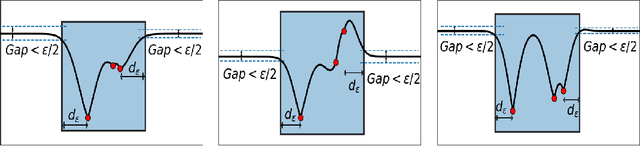


Applying Bayesian optimization in problems wherein the search space is unknown is challenging. To address this problem, we propose a systematic volume expansion strategy for the Bayesian optimization. We devise a strategy to guarantee that in iterative expansions of the search space, our method can find a point whose function value within epsilon of the objective function maximum. Without the need to specify any parameters, our algorithm automatically triggers a minimal expansion required iteratively. We derive analytic expressions for when to trigger the expansion and by how much to expand. We also provide theoretical analysis to show that our method achieves epsilon-accuracy after a finite number of iterations. We demonstrate our method on both benchmark test functions and machine learning hyper-parameter tuning tasks and demonstrate that our method outperforms baselines.
* 33rd Conference on Neural Information Processing Systems (NeurIPS 2019), Vancouver, Canada
Learning Transferable Domain Priors for Safe Exploration in Reinforcement Learning
Sep 11, 2019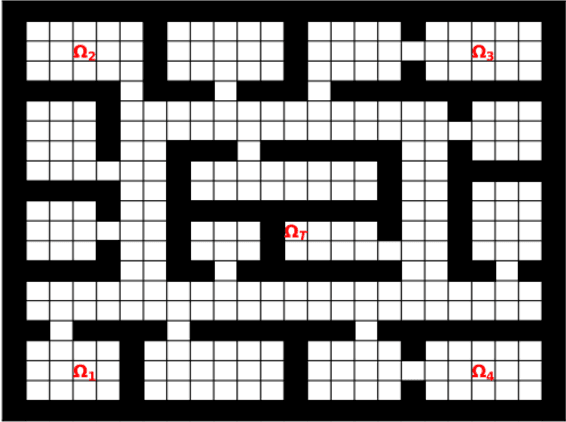
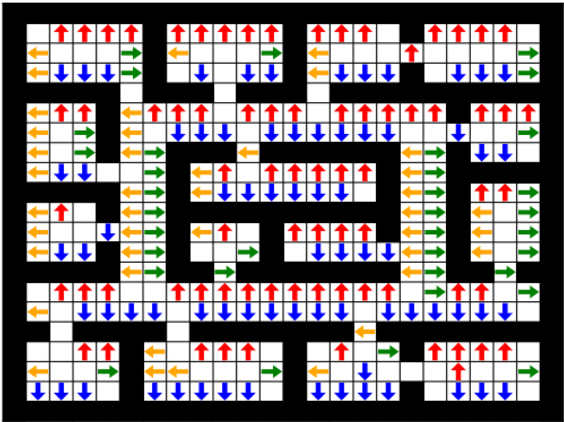
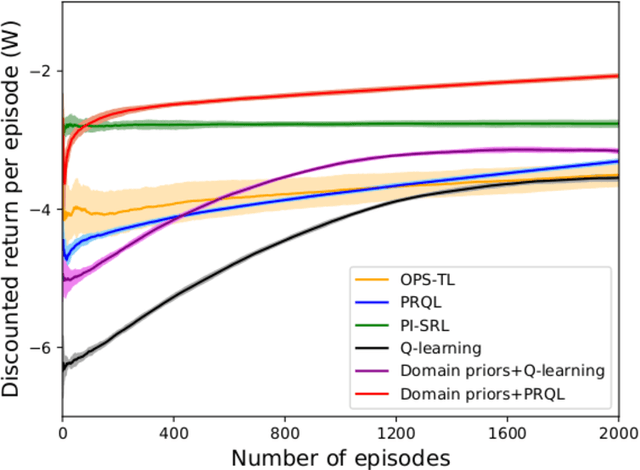
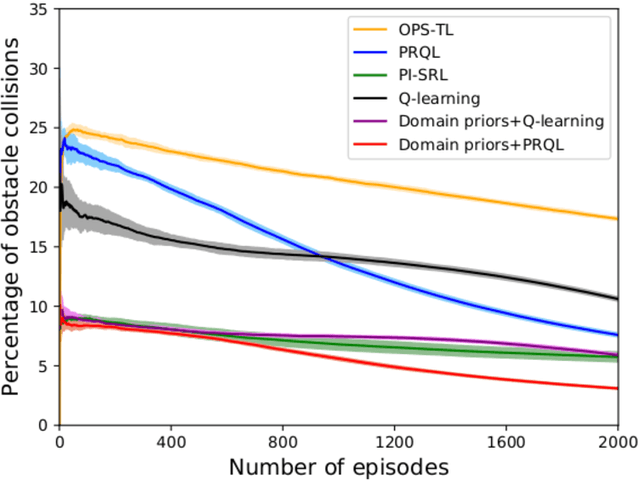
Prior access to domain knowledge could significantly improve the performance of a reinforcement learning agent. In particular, it could help agents avoid potentially catastrophic exploratory actions, which would otherwise have to be experienced during learning. In this work, we identify consistently undesirable actions in a set of previously learned tasks, and use pseudo-rewards associated with them to learn a prior policy. In addition to enabling safe exploratory behaviors in subsequent tasks in the domain, these priors are transferable to similar environments, and can be learned off-policy and in parallel with the learning of other tasks in the domain. We compare our approach to established, state-of-the-art algorithms in a grid-world navigation environment, and demonstrate that it exhibits a superior performance with respect to avoiding unsafe actions while learning to perform arbitrary tasks in the domain. We also present some theoretical analysis to support these results, and discuss the implications and some alternative formulations of this approach, which could also be useful to accelerate learning in certain scenarios.
Cost-aware Multi-objective Bayesian optimisation
Sep 09, 2019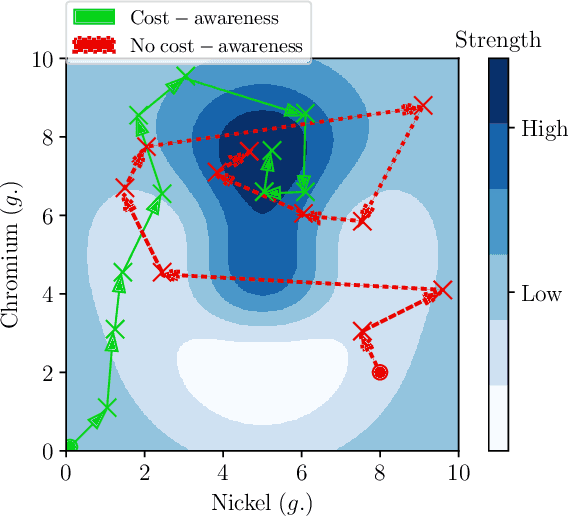
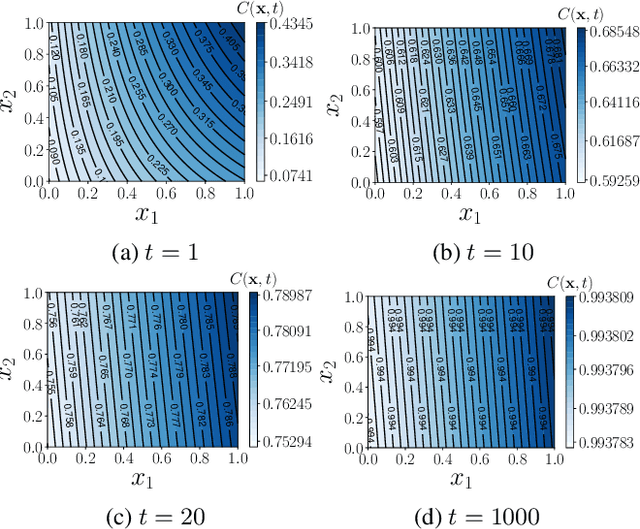
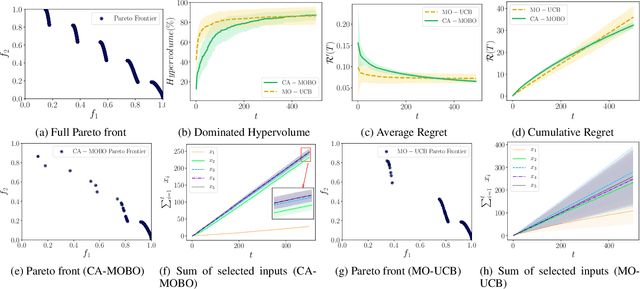
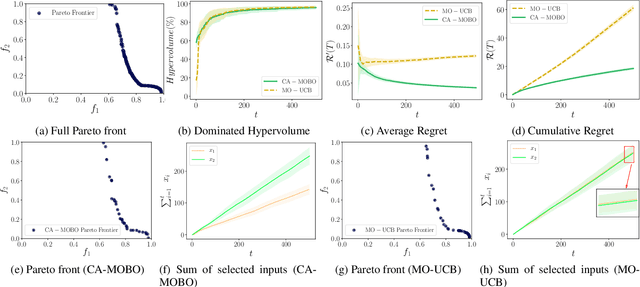
The notion of expense in Bayesian optimisation generally refers to the uniformly expensive cost of function evaluations over the whole search space. However, in some scenarios, the cost of evaluation for black-box objective functions is non-uniform since different inputs from search space may incur different costs for function evaluations. We introduce a cost-aware multi-objective Bayesian optimisation with non-uniform evaluation cost over objective functions by defining cost-aware constraints over the search space. The cost-aware constraints are a sorted tuple of indexes that demonstrate the ordering of dimensions of the search space based on the user's prior knowledge about their cost of usage. We formulate a new multi-objective Bayesian optimisation acquisition function with detailed analysis of the convergence that incorporates this cost-aware constraints while optimising the objective functions. We demonstrate our algorithm based on synthetic and real-world problems in hyperparameter tuning of neural networks and random forests.
Accelerating Experimental Design by Incorporating Experimenter Hunches
Jul 22, 2019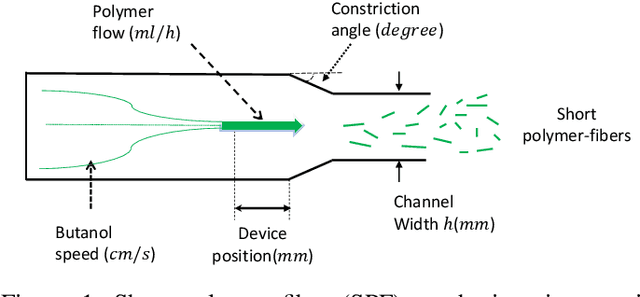
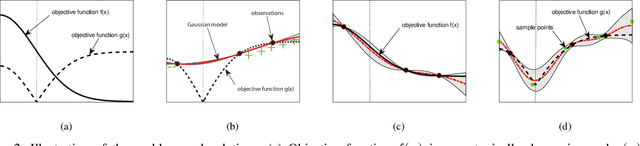
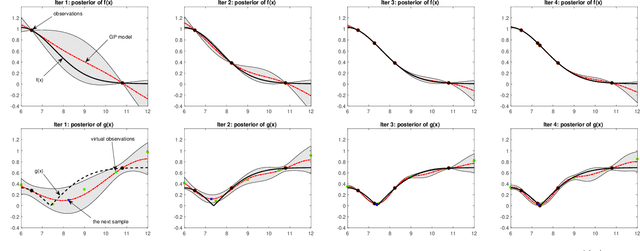
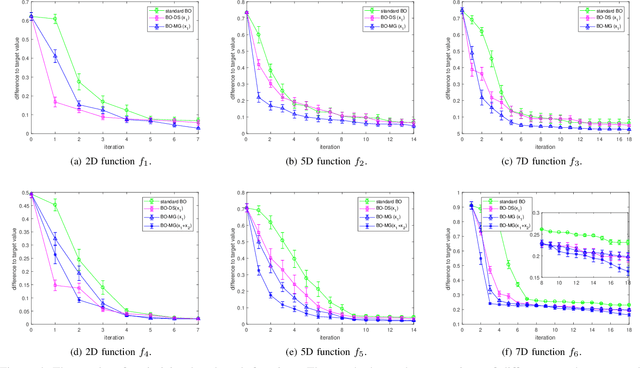
Experimental design is a process of obtaining a product with target property via experimentation. Bayesian optimization offers a sample-efficient tool for experimental design when experiments are expensive. Often, expert experimenters have 'hunches' about the behavior of the experimental system, offering potentials to further improve the efficiency. In this paper, we consider per-variable monotonic trend in the underlying property that results in a unimodal trend in those variables for a target value optimization. For example, sweetness of a candy is monotonic to the sugar content. However, to obtain a target sweetness, the utility of the sugar content becomes a unimodal function, which peaks at the value giving the target sweetness and falls off both ways. In this paper, we propose a novel method to solve such problems that achieves two main objectives: a) the monotonicity information is used to the fullest extent possible, whilst ensuring that b) the convergence guarantee remains intact. This is achieved by a two-stage Gaussian process modeling, where the first stage uses the monotonicity trend to model the underlying property, and the second stage uses `virtual' samples, sampled from the first, to model the target value optimization function. The process is made theoretically consistent by adding appropriate adjustment factor in the posterior computation, necessitated because of using the `virtual' samples. The proposed method is evaluated through both simulations and real world experimental design problems of a) new short polymer fiber with the target length, and b) designing of a new three dimensional porous scaffolding with a target porosity. In all scenarios our method demonstrates faster convergence than the basic Bayesian optimization approach not using such `hunches'.
Sparse Spectrum Gaussian Process for Bayesian Optimisation
Jun 21, 2019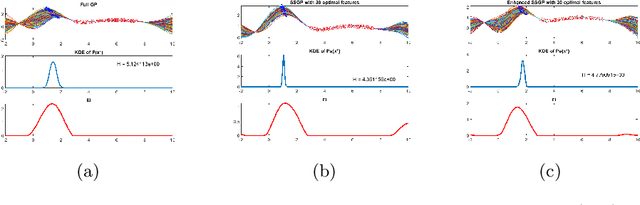
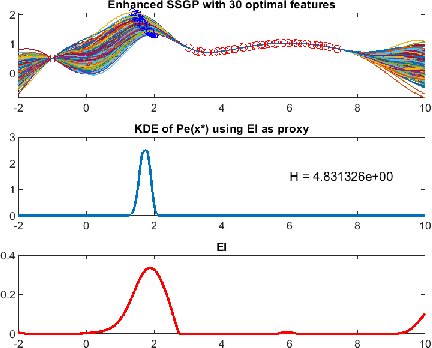
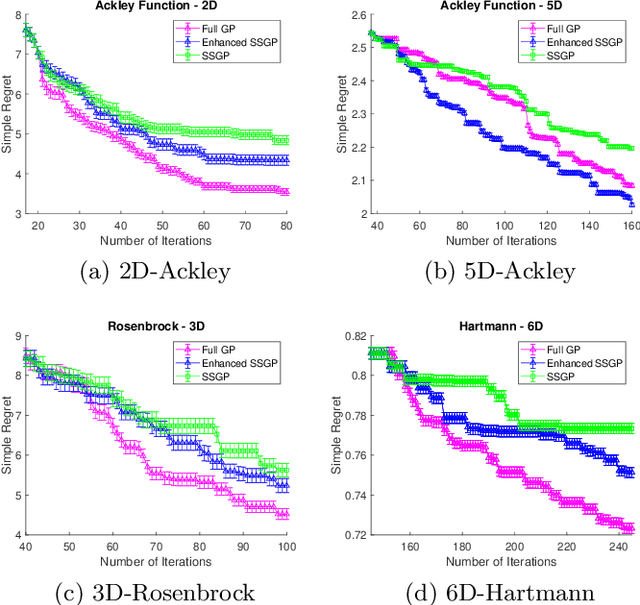
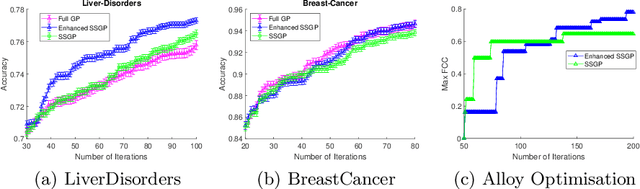
We propose a novel sparse spectrum approximation of Gaussian process (GP) tailored for Bayesian optimisation. Whilst the current sparse spectrum methods provide good approximations for regression problems, it is observed that this particular form of sparse approximations generates an overconfident GP, i.e. it predicts less variance than the original GP. Since the balance between predictive mean and the predictive variance is a key determinant in the success of Bayesian optimisation, the current sparse spectrum methods are less suitable. We derive a regularised marginal likelihood for finding the optimal frequencies in optimisation problems. The regulariser trades the accuracy in the model fitting with the targeted increase in the variance of the resultant GP. We first consider the entropy of the distribution over the maxima as the regulariser that needs to be maximised. Later we show that the Expected Improvement acquisition function can also be used as a proxy for that, thus making the optimisation less computationally expensive. Experiments show an increase in the Bayesian optimisation convergence rate over the vanilla sparse spectrum method.
Stable Bayesian Optimisation via Direct Stability Quantification
Feb 21, 2019
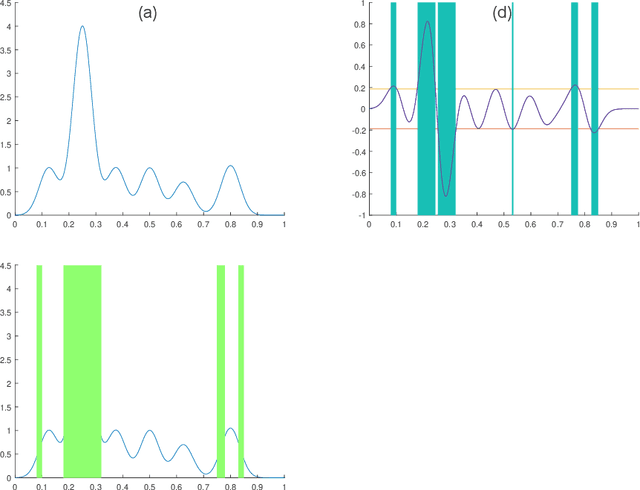
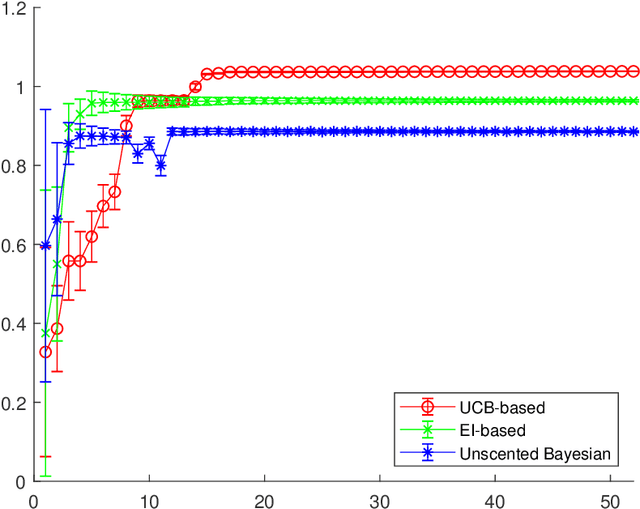
In this paper we consider the problem of finding stable maxima of expensive (to evaluate) functions. We are motivated by the optimisation of physical and industrial processes where, for some input ranges, small and unavoidable variations in inputs lead to unacceptably large variation in outputs. Our approach uses multiple gradient Gaussian Process models to estimate the probability that worst-case output variation for specified input perturbation exceeded the desired maxima, and these probabilities are then used to (a) guide the optimisation process toward solutions satisfying our stability criteria and (b) post-filter results to find the best stable solution. We exhibit our algorithm on synthetic and real-world problems and demonstrate that it is able to effectively find stable maxima.
Multi-objective Bayesian optimisation with preferences over objectives
Feb 12, 2019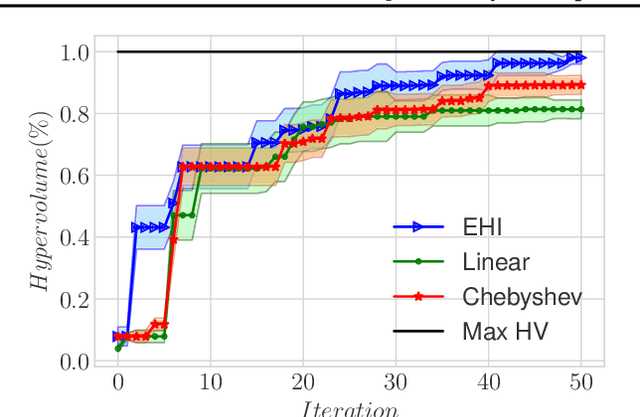


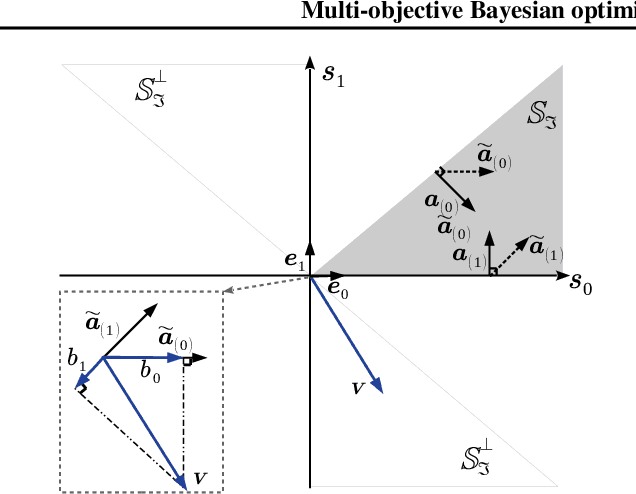
We present a Bayesian multi-objective optimisation algorithm that allows the user to express preference-order constraints on the objectives of the type `objective A is more important than objective B'. Rather than attempting to find a representative subset of the complete Pareto front, our algorithm searches for and returns only those Pareto-optimal points that satisfy these constraints. We formulate a new acquisition function based on expected improvement in dominated hypervolume (EHI) to ensure that the subset of Pareto front satisfying the constraints is thoroughly explored. The hypervolume calculation only includes those points that satisfy the preference-order constraints, where the probability of a point satisfying the constraints is calculated from a gradient Gaussian Process model. We demonstrate our algorithm on both synthetic and real-world problems.
Fast Hyperparameter Tuning using Bayesian Optimization with Directional Derivatives
Feb 06, 2019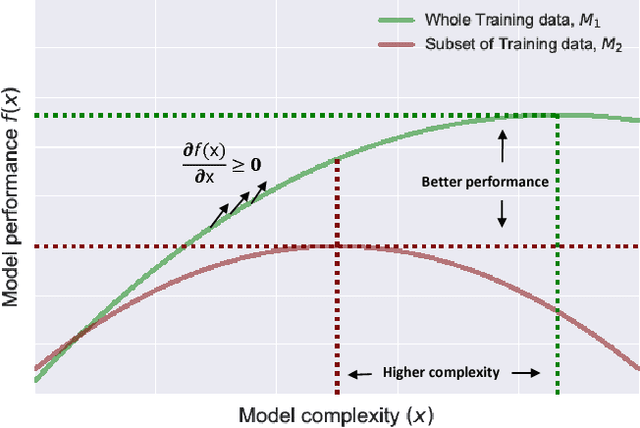



In this paper we develop a Bayesian optimization based hyperparameter tuning framework inspired by statistical learning theory for classifiers. We utilize two key facts from PAC learning theory; the generalization bound will be higher for a small subset of data compared to the whole, and the highest accuracy for a small subset of data can be achieved with a simple model. We initially tune the hyperparameters on a small subset of training data using Bayesian optimization. While tuning the hyperparameters on the whole training data, we leverage the insights from the learning theory to seek more complex models. We realize this by using directional derivative signs strategically placed in the hyperparameter search space to seek a more complex model than the one obtained with small data. We demonstrate the performance of our method on the tasks of tuning the hyperparameters of several machine learning algorithms.