 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Offline Metrics for Autonomous Driving
Oct 09, 2025



Real-World evaluation of perception-based planning models for robotic systems, such as autonomous vehicles, can be safely and inexpensively conducted offline, i.e., by computing model prediction error over a pre-collected validation dataset with ground-truth annotations. However, extrapolating from offline model performance to online settings remains a challenge. In these settings, seemingly minor errors can compound and result in test-time infractions or collisions. This relationship is understudied, particularly across diverse closed-loop metrics and complex urban maneuvers. In this work, we revisit this undervalued question in policy evaluation through an extensive set of experiments across diverse conditions and metrics. Based on analysis in simulation, we find an even worse correlation between offline and online settings than reported by prior studies, casting doubts on the validity of current evaluation practices and metrics for driving policies. Next, we bridge the gap between offline and online evaluation. We investigate an offline metric based on epistemic uncertainty, which aims to capture events that are likely to cause errors in closed-loop settings. The resulting metric achieves over 13% improvement in correlation compared to previous offline metrics. We further validate the generalization of our findings beyond the simulation environment in real-world settings, where even greater gains are observed.
LatentGAN Autoencoder: Learning Disentangled Latent Distribution
Apr 05, 2022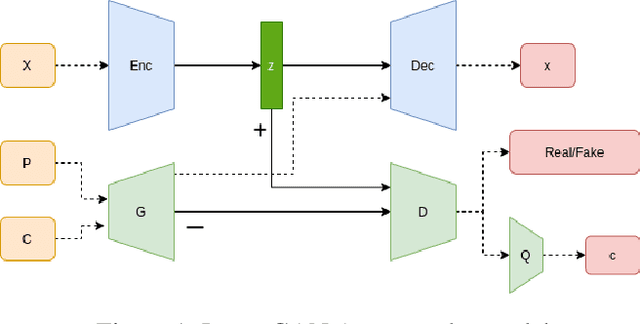
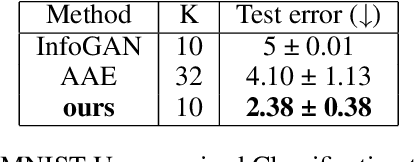


In autoencoder, the encoder generally approximates the latent distribution over the dataset, and the decoder generates samples using this learned latent distribution. There is very little control over the latent vector as using the random latent vector for generation will lead to trivial outputs. This work tries to address this issue by using the LatentGAN generator to directly learn to approximate the latent distribution of the autoencoder and show meaningful results on MNIST, 3D Chair, and CelebA datasets, an additional information-theoretic constrain is used which successfully learns to control autoencoder latent distribution. With this, our model also achieves an error rate of 2.38 on MNIST unsupervised image classification, which is better as compared to InfoGAN and AAE.