 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing the Geolocation Capabilities, Limitations and Societal Risks of Generative Vision-Language Models
Aug 27, 2025Geo-localization is the task of identifying the location of an image using visual cues alone. It has beneficial applications, such as improving disaster response, enhancing navigation, and geography education. Recently, Vision-Language Models (VLMs) are increasingly demonstrating capabilities as accurate image geo-locators. This brings significant privacy risks, including those related to stalking and surveillance, considering the widespread uses of AI models and sharing of photos on social media. The precision of these models is likely to improve in the future. Despite these risks, there is little work on systematically evaluating the geolocation precision of Generative VLMs, their limits and potential for unintended inferences. To bridge this gap, we conduct a comprehensive assessment of the geolocation capabilities of 25 state-of-the-art VLMs on four benchmark image datasets captured in diverse environments. Our results offer insight into the internal reasoning of VLMs and highlight their strengths, limitations, and potential societal risks. Our findings indicate that current VLMs perform poorly on generic street-level images yet achieve notably high accuracy (61\%) on images resembling social media content, raising significant and urgent privacy concerns.
VLM-Guided Visual Place Recognition for Planet-Scale Geo-Localization
Jul 23, 2025Geo-localization from a single image at planet scale (essentially an advanced or extreme version of the kidnapped robot problem) is a fundamental and challenging task in applications such as navigation, autonomous driving and disaster response due to the vast diversity of locations, environmental conditions, and scene variations. Traditional retrieval-based methods for geo-localization struggle with scalability and perceptual aliasing, while classification-based approaches lack generalization and require extensive training data. Recent advances in vision-language models (VLMs) offer a promising alternative by leveraging contextual understanding and reasoning. However, while VLMs achieve high accuracy, they are often prone to hallucinations and lack interpretability, making them unreliable as standalone solutions. In this work, we propose a novel hybrid geo-localization framework that combines the strengths of VLMs with retrieval-based visual place recognition (VPR) methods. Our approach first leverages a VLM to generate a prior, effectively guiding and constraining the retrieval search space. We then employ a retrieval step, followed by a re-ranking mechanism that selects the most geographically plausible matches based on feature similarity and proximity to the initially estimated coordinates. We evaluate our approach on multiple geo-localization benchmarks and show that it consistently outperforms prior state-of-the-art methods, particularly at street (up to 4.51%) and city level (up to 13.52%). Our results demonstrate that VLM-generated geographic priors in combination with VPR lead to scalable, robust, and accurate geo-localization systems.
Image-based Geo-localization for Robotics: Are Black-box Vision-Language Models there yet?
Jan 28, 2025



The advances in Vision-Language models (VLMs) offer exciting opportunities for robotic applications involving image geo-localization, the problem of identifying the geo-coordinates of a place based on visual data only. Recent research works have focused on using a VLM as embeddings extractor for geo-localization, however, the most sophisticated VLMs may only be available as black boxes that are accessible through an API, and come with a number of limitations: there is no access to training data, model features and gradients; retraining is not possible; the number of predictions may be limited by the API; training on model outputs is often prohibited; and queries are open-ended. The utilization of a VLM as a stand-alone, zero-shot geo-localization system using a single text-based prompt is largely unexplored. To bridge this gap, this paper undertakes the first systematic study, to the best of our knowledge, to investigate the potential of some of the state-of-the-art VLMs as stand-alone, zero-shot geo-localization systems in a black-box setting with realistic constraints. We consider three main scenarios for this thorough investigation: a) fixed text-based prompt; b) semantically-equivalent text-based prompts; and c) semantically-equivalent query images. We also take into account the auto-regressive and probabilistic generation process of the VLMs when investigating their utility for geo-localization task by using model consistency as a metric in addition to traditional accuracy. Our work provides new insights in the capabilities of different VLMs for the above-mentioned scenarios.
A Complementarity-Based Switch-Fuse System for Improved Visual Place Recognition
Mar 01, 2023



Recently several fusion and switching based approaches have been presented to solve the problem of Visual Place Recognition. In spite of these systems demonstrating significant boost in VPR performance they each have their own set of limitations. The multi-process fusion systems usually involve employing brute force and running all available VPR techniques simultaneously while the switching method attempts to negate this practise by only selecting the best suited VPR technique for given query image. But switching does fail at times when no available suitable technique can be identified. An innovative solution would be an amalgamation of the two otherwise discrete approaches to combine their competitive advantages while negating their shortcomings. The proposed, Switch-Fuse system, is an interesting way to combine both the robustness of switching VPR techniques based on complementarity and the force of fusing the carefully selected techniques to significantly improve performance. Our system holds a structure superior to the basic fusion methods as instead of simply fusing all or any random techniques, it is structured to first select the best possible VPR techniques for fusion, according to the query image. The system combines two significant processes, switching and fusing VPR techniques, which together as a hybrid model substantially improve performance on all major VPR data sets illustrated using PR curves.
Visual Place Recognition for Aerial Robotics: Exploring Accuracy-Computation Trade-off for Local Image Descriptors
Aug 01, 2019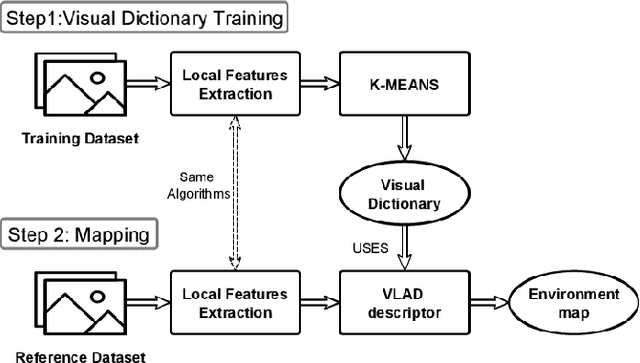
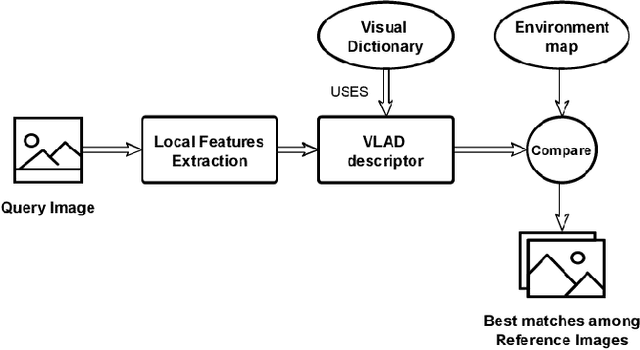


Visual Place Recognition (VPR) is a fundamental yet challenging task for small Unmanned Aerial Vehicle (UAV). The core reasons are the extreme viewpoint changes, and limited computational power onboard a UAV which restricts the applicability of robust but computation intensive state-of-the-art VPR methods. In this context, a viable approach is to use local image descriptors for performing VPR as these can be computed relatively efficiently without the need of any special hardware, such as a GPU. However, the choice of a local feature descriptor is not trivial and calls for a detailed investigation as there is a trade-off between VPR accuracy and the required computational effort. To fill this research gap, this paper examines the performance of several state-of-the-art local feature descriptors, both from accuracy and computational perspectives, specifically for VPR application utilizing standard aerial datasets. The presented results confirm that a trade-off between accuracy and computational effort is inevitable while executing VPR on resource-constrained hardware.