 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOvercoming Catastrophic Forgetting by Incremental Moment Matching
Jan 30, 2018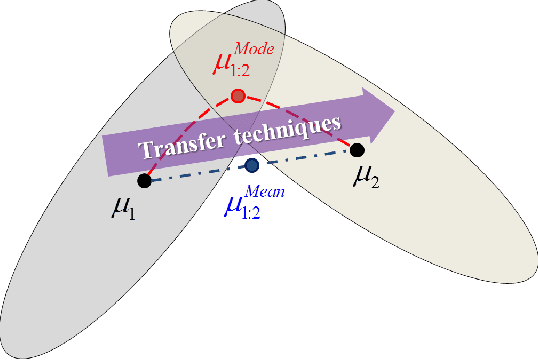
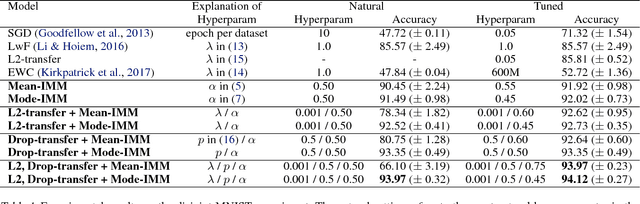
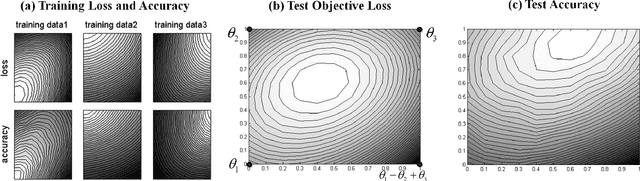

Catastrophic forgetting is a problem of neural networks that loses the information of the first task after training the second task. Here, we propose a method, i.e. incremental moment matching (IMM), to resolve this problem. IMM incrementally matches the moment of the posterior distribution of the neural network which is trained on the first and the second task, respectively. To make the search space of posterior parameter smooth, the IMM procedure is complemented by various transfer learning techniques including weight transfer, L2-norm of the old and the new parameter, and a variant of dropout with the old parameter. We analyze our approach on a variety of datasets including the MNIST, CIFAR-10, Caltech-UCSD-Birds, and Lifelog datasets. The experimental results show that IMM achieves state-of-the-art performance by balancing the information between an old and a new network.
Micro-Objective Learning : Accelerating Deep Reinforcement Learning through the Discovery of Continuous Subgoals
Mar 11, 2017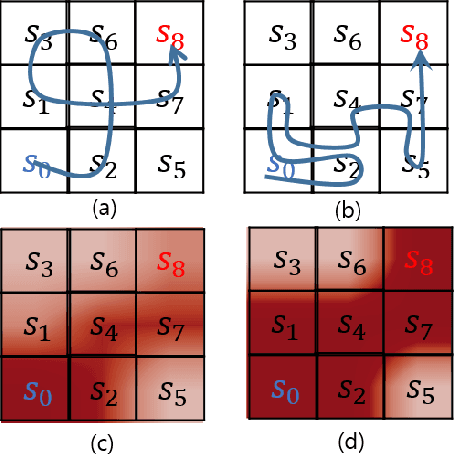
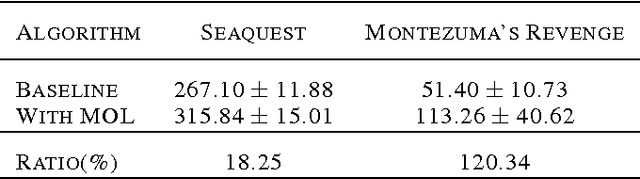
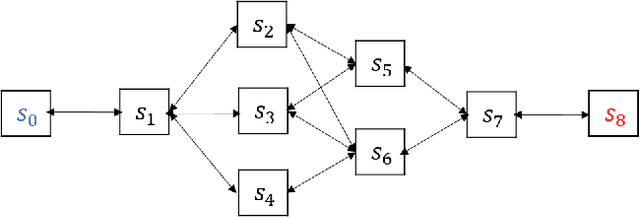
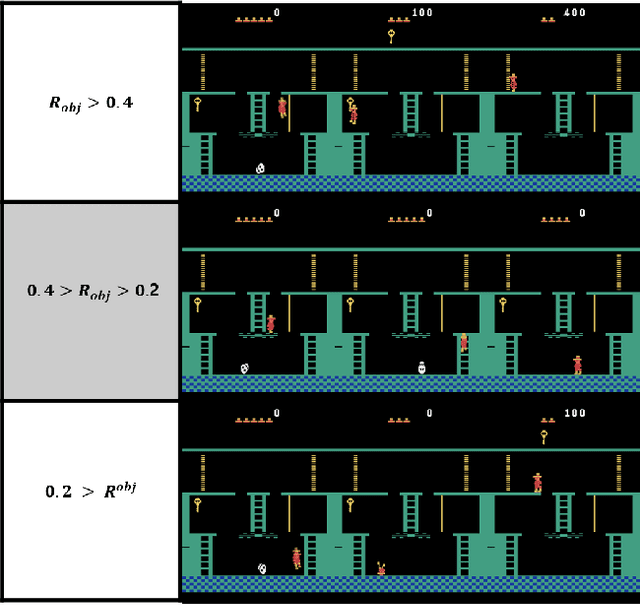
Recently, reinforcement learning has been successfully applied to the logical game of Go, various Atari games, and even a 3D game, Labyrinth, though it continues to have problems in sparse reward settings. It is difficult to explore, but also difficult to exploit, a small number of successes when learning policy. To solve this issue, the subgoal and option framework have been proposed. However, discovering subgoals online is too expensive to be used to learn options in large state spaces. We propose Micro-objective learning (MOL) to solve this problem. The main idea is to estimate how important a state is while training and to give an additional reward proportional to its importance. We evaluated our algorithm in two Atari games: Montezuma's Revenge and Seaquest. With three experiments to each game, MOL significantly improved the baseline scores. Especially in Montezuma's Revenge, MOL achieved two times better results than the previous state-of-the-art model.
Multimodal Residual Learning for Visual QA
Aug 31, 2016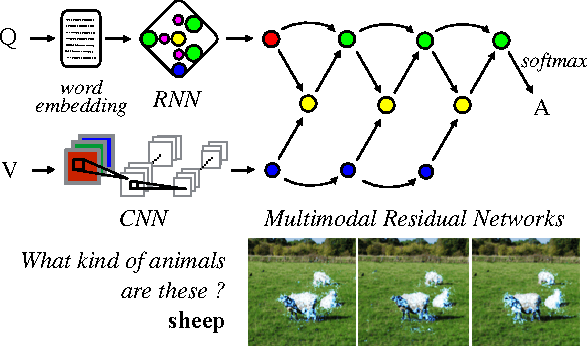
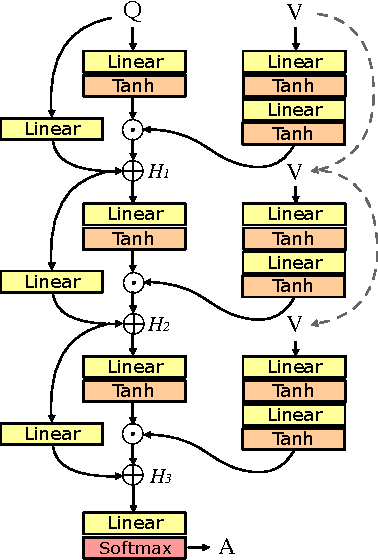
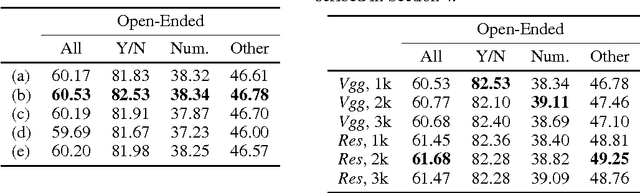
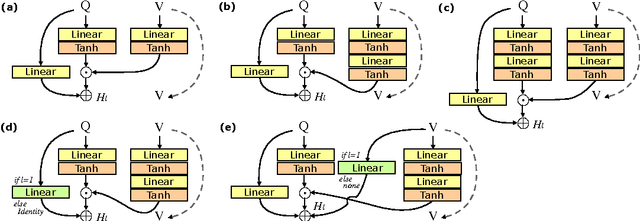
Deep neural networks continue to advance the state-of-the-art of image recognition tasks with various methods. However, applications of these methods to multimodality remain limited. We present Multimodal Residual Networks (MRN) for the multimodal residual learning of visual question-answering, which extends the idea of the deep residual learning. Unlike the deep residual learning, MRN effectively learns the joint representation from vision and language information. The main idea is to use element-wise multiplication for the joint residual mappings exploiting the residual learning of the attentional models in recent studies. Various alternative models introduced by multimodality are explored based on our study. We achieve the state-of-the-art results on the Visual QA dataset for both Open-Ended and Multiple-Choice tasks. Moreover, we introduce a novel method to visualize the attention effect of the joint representations for each learning block using back-propagation algorithm, even though the visual features are collapsed without spatial information.
Dual Memory Architectures for Fast Deep Learning of Stream Data via an Online-Incremental-Transfer Strategy
Jun 15, 2015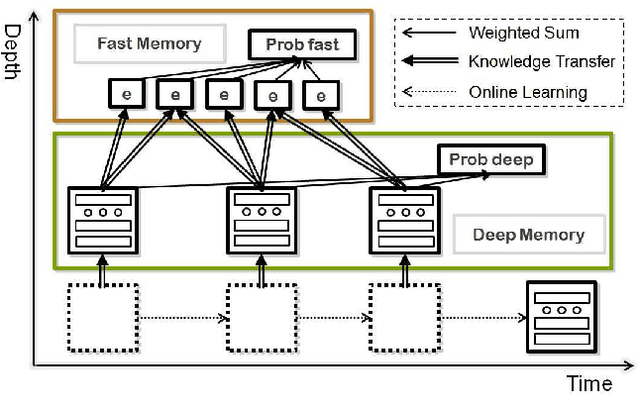
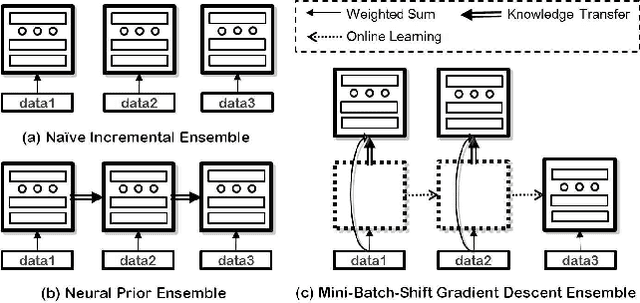
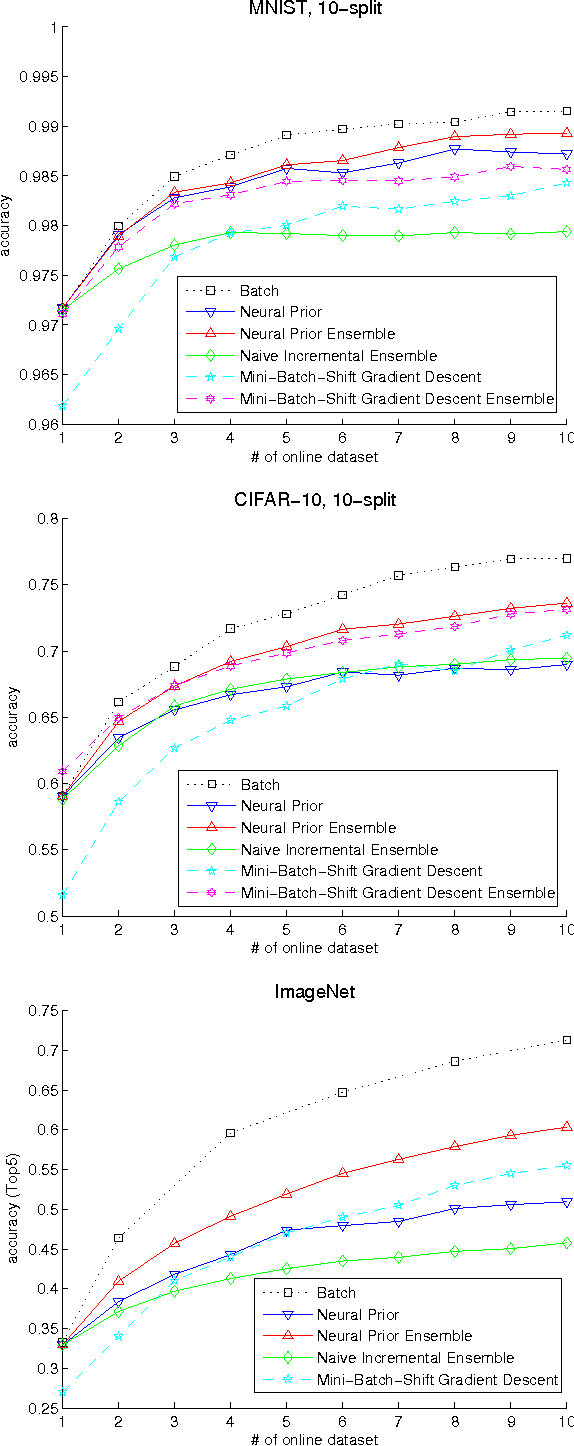
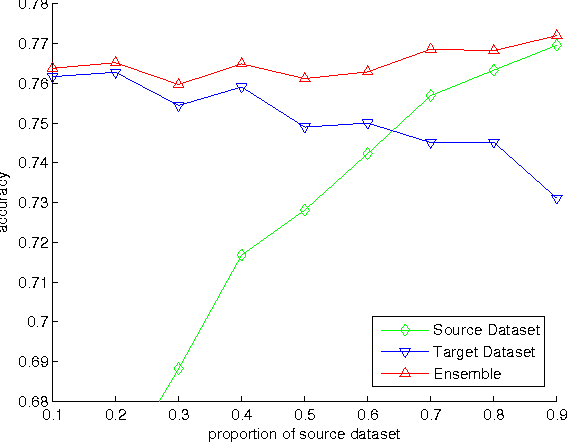
The online learning of deep neural networks is an interesting problem of machine learning because, for example, major IT companies want to manage the information of the massive data uploaded on the web daily, and this technology can contribute to the next generation of lifelong learning. We aim to train deep models from new data that consists of new classes, distributions, and tasks at minimal computational cost, which we call online deep learning. Unfortunately, deep neural network learning through classical online and incremental methods does not work well in both theory and practice. In this paper, we introduce dual memory architectures for online incremental deep learning. The proposed architecture consists of deep representation learners and fast learnable shallow kernel networks, both of which synergize to track the information of new data. During the training phase, we use various online, incremental ensemble, and transfer learning techniques in order to achieve lower error of the architecture. On the MNIST, CIFAR-10, and ImageNet image recognition tasks, the proposed dual memory architectures performs much better than the classical online and incremental ensemble algorithm, and their accuracies are similar to that of the batch learner.