 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Low is Too Low? A Computational Perspective on Extremely Low-Resource Languages
May 30, 2021
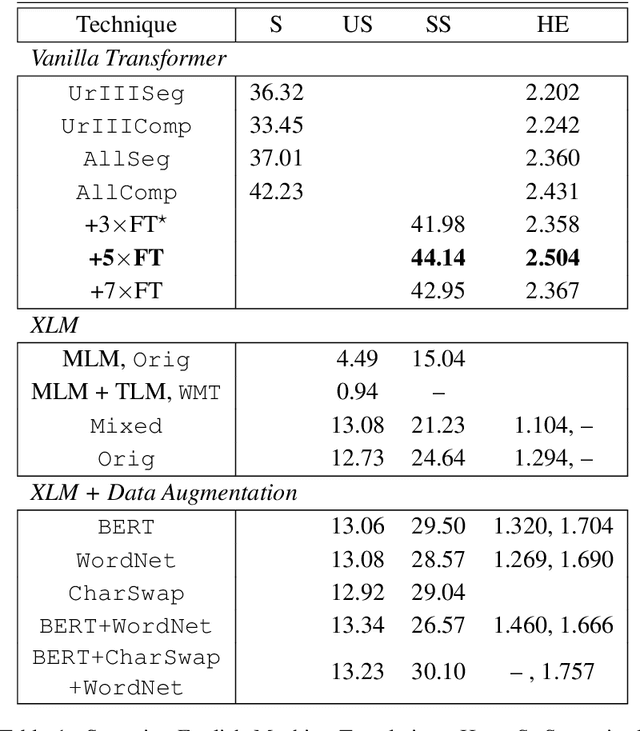
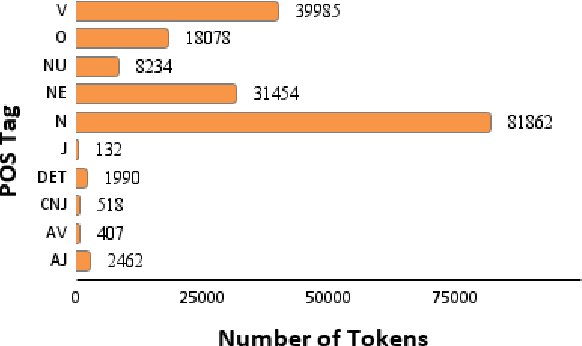
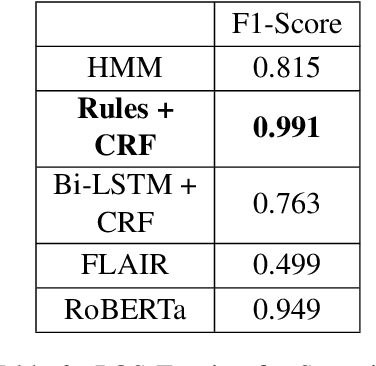
Despite the recent advancements of attention-based deep learning architectures across a majority of Natural Language Processing tasks, their application remains limited in a low-resource setting because of a lack of pre-trained models for such languages. In this study, we make the first attempt to investigate the challenges of adapting these techniques for an extremely low-resource language -- Sumerian cuneiform -- one of the world's oldest written languages attested from at least the beginning of the 3rd millennium BC. Specifically, we introduce the first cross-lingual information extraction pipeline for Sumerian, which includes part-of-speech tagging, named entity recognition, and machine translation. We further curate InterpretLR, an interpretability toolkit for low-resource NLP, and use it alongside human attributions to make sense of the models. We emphasize on human evaluations to gauge all our techniques. Notably, most components of our pipeline can be generalised to any other language to obtain an interpretable execution of the techniques, especially in a low-resource setting. We publicly release all software, model checkpoints, and a novel dataset with domain-specific pre-processing to promote further research.
A Recurrent Neural Model with Attention for the Recognition of Chinese Implicit Discourse Relations
Apr 26, 2017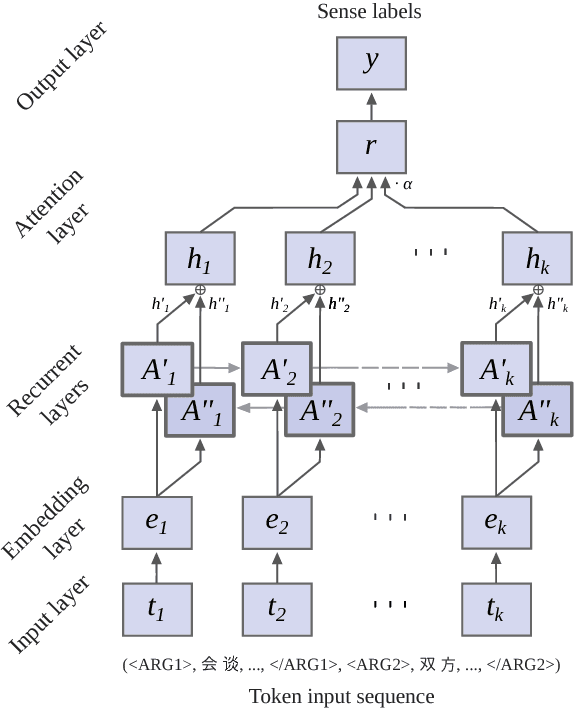
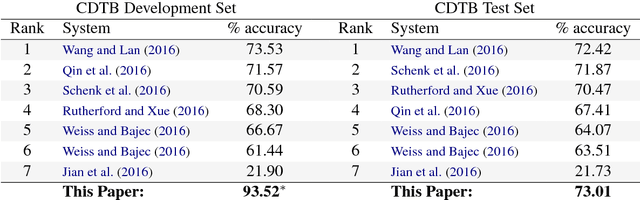
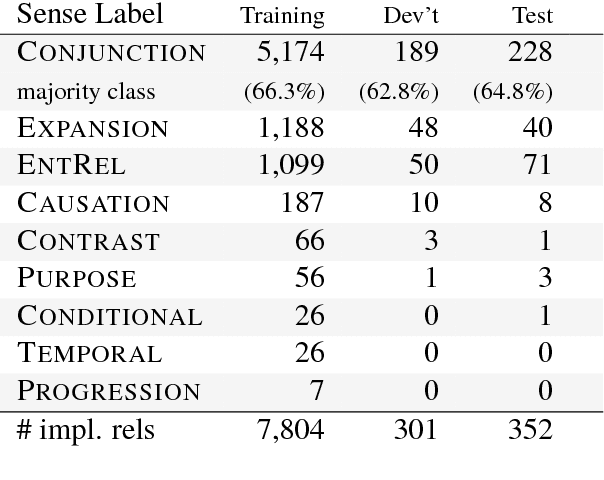

We introduce an attention-based Bi-LSTM for Chinese implicit discourse relations and demonstrate that modeling argument pairs as a joint sequence can outperform word order-agnostic approaches. Our model benefits from a partial sampling scheme and is conceptually simple, yet achieves state-of-the-art performance on the Chinese Discourse Treebank. We also visualize its attention activity to illustrate the model's ability to selectively focus on the relevant parts of an input sequence.