 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA mathematical theory of balancing relational generalization and memorization
May 21, 2026Humans, animals, and modern machine learning models exhibit impressive abilities to learn complex behaviors and generalize these behaviors to unseen situations. This ability requires us to learn rules and regularities that allow for such generalizations. At the same time, in most complex environments, any rule will have its exceptions. How do learning systems balance between learning general regularities and memorizing exceptions? We argue that a lack of task paradigms has hindered the study of this essential ability. To address this gap, we introduce a novel task, transitive inference with exceptions, that tests for relational generalization and memorization of an exception to the relational rule. We then analytically characterize the behavior of a simple, theoretically tractable model of neural network learning (kernel ridge regression) across a broad family of representations and task parameters. We find that these models can balance between relational generalization and memorization, but unlike for transitive inference without an exception, successful generalization is sensitive to the specific representational geometry. We explain why this task is more challenging mechanistically by drawing on our analytical theory. Finally, we validate our theoretical insights in pretrained language models that are finetuned on ordered relations, finding that these models successfully generalize according to the transitive rule, but also make the kinds of systematic mistakes predicted by our theory. Overall, our theory shows how learning systems can balance between relational generalization and memorization, explains how this can go wrong, and emphasizes the need for new task paradigms designed to probe this ability.
A Theory of How Pretraining Shapes Inductive Bias in Fine-Tuning
Feb 23, 2026Pretraining and fine-tuning are central stages in modern machine learning systems. In practice, feature learning plays an important role across both stages: deep neural networks learn a broad range of useful features during pretraining and further refine those features during fine-tuning. However, an end-to-end theoretical understanding of how choices of initialization impact the ability to reuse and refine features during fine-tuning has remained elusive. Here we develop an analytical theory of the pretraining-fine-tuning pipeline in diagonal linear networks, deriving exact expressions for the generalization error as a function of initialization parameters and task statistics. We find that different initialization choices place the network into four distinct fine-tuning regimes that are distinguished by their ability to support feature learning and reuse, and therefore by the task statistics for which they are beneficial. In particular, a smaller initialization scale in earlier layers enables the network to both reuse and refine its features, leading to superior generalization on fine-tuning tasks that rely on a subset of pretraining features. We demonstrate empirically that the same initialization parameters impact generalization in nonlinear networks trained on CIFAR-100. Overall, our results demonstrate analytically how data and network initialization interact to shape fine-tuning generalization, highlighting an important role for the relative scale of initialization across different layers in enabling continued feature learning during fine-tuning.
When does compositional structure yield compositional generalization? A kernel theory
May 26, 2024Compositional generalization (the ability to respond correctly to novel combinations of familiar components) is thought to be a cornerstone of intelligent behavior. Compositionally structured (e.g. disentangled) representations are essential for this; however, the conditions under which they yield compositional generalization remain unclear. To address this gap, we present a general theory of compositional generalization in kernel models with fixed, potentially nonlinear representations (which also applies to neural networks in the "lazy regime"). We prove that these models are functionally limited to adding up values assigned to conjunctions/combinations of components that have been seen during training ("conjunction-wise additivity"), and identify novel compositionality failure modes that arise from the data and model structure, even for disentangled inputs. For models in the representation learning (or "rich") regime, we show that networks can generalize on an important non-additive task (associative inference), and give a mechanistic explanation for why. Finally, we validate our theory empirically, showing that it captures the behavior of deep neural networks trained on a set of compositional tasks. In sum, our theory characterizes the principles giving rise to compositional generalization in kernel models and shows how representation learning can overcome their limitations. We further provide a formally grounded, novel generalization class for compositional tasks that highlights fundamental differences in the required learning mechanisms (conjunction-wise additivity).
Implicit regularization of multi-task learning and finetuning in overparameterized neural networks
Oct 03, 2023



It is common in deep learning to train networks on auxiliary tasks with the expectation that the learning will transfer, at least partially, to another task of interest. In this work, we investigate the inductive biases that result from learning auxiliary tasks, either simultaneously (multi-task learning, MTL) or sequentially (pretraining and subsequent finetuning, PT+FT). In the simplified setting of two-layer diagonal linear networks trained with gradient descent, we identify implicit regularization penalties associated with MTL and PT+FT, both of which incentivize feature sharing between tasks and sparsity in learned task-specific features. Notably, our results imply that during finetuning, networks operate in a hybrid of the kernel (or "lazy") regime and the feature learning ("rich") regime identified in prior work. Moreover, PT+FT can exhibit a novel "nested feature learning" behavior not captured by either regime, which biases it to extract a sparse subset of the features learned during pretraining. In ReLU networks, we reproduce all of these qualitative behaviors. We also observe that PT+FT (but not MTL) is biased to learn features that are correlated with (but distinct from) those needed for the auxiliary task, while MTL is biased toward using identical features for both tasks. As a result, we find that in realistic settings, MTL generalizes better when comparatively little data is available for the task of interest, while PT+FT outperforms it with more data available. We show that our findings hold qualitatively for a deep architecture trained on image classification tasks. Our characterization of the nested feature learning regime also motivates a modification to PT+FT that we find empirically improves performance. Overall, our results shed light on the impact of auxiliary task learning and suggest ways to leverage it more effectively.
The Implicit Bias of Gradient Descent on Generalized Gated Linear Networks
Feb 05, 2022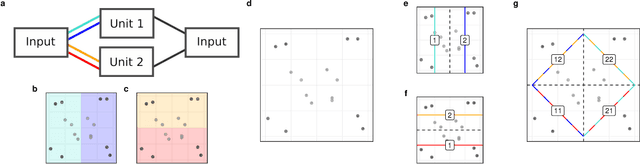
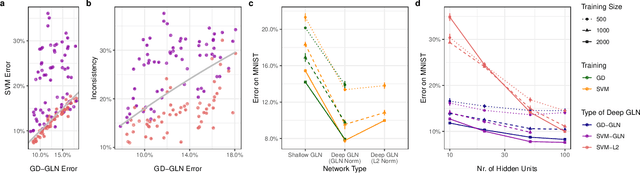

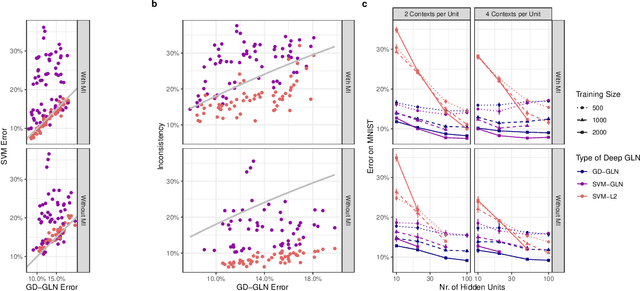
Understanding the asymptotic behavior of gradient-descent training of deep neural networks is essential for revealing inductive biases and improving network performance. We derive the infinite-time training limit of a mathematically tractable class of deep nonlinear neural networks, gated linear networks (GLNs), and generalize these results to gated networks described by general homogeneous polynomials. We study the implications of our results, focusing first on two-layer GLNs. We then apply our theoretical predictions to GLNs trained on MNIST and show how architectural constraints and the implicit bias of gradient descent affect performance. Finally, we show that our theory captures a substantial portion of the inductive bias of ReLU networks. By making the inductive bias explicit, our framework is poised to inform the development of more efficient, biologically plausible, and robust learning algorithms.