 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Theory of How Pretraining Shapes Inductive Bias in Fine-Tuning
Feb 23, 2026Pretraining and fine-tuning are central stages in modern machine learning systems. In practice, feature learning plays an important role across both stages: deep neural networks learn a broad range of useful features during pretraining and further refine those features during fine-tuning. However, an end-to-end theoretical understanding of how choices of initialization impact the ability to reuse and refine features during fine-tuning has remained elusive. Here we develop an analytical theory of the pretraining-fine-tuning pipeline in diagonal linear networks, deriving exact expressions for the generalization error as a function of initialization parameters and task statistics. We find that different initialization choices place the network into four distinct fine-tuning regimes that are distinguished by their ability to support feature learning and reuse, and therefore by the task statistics for which they are beneficial. In particular, a smaller initialization scale in earlier layers enables the network to both reuse and refine its features, leading to superior generalization on fine-tuning tasks that rely on a subset of pretraining features. We demonstrate empirically that the same initialization parameters impact generalization in nonlinear networks trained on CIFAR-100. Overall, our results demonstrate analytically how data and network initialization interact to shape fine-tuning generalization, highlighting an important role for the relative scale of initialization across different layers in enabling continued feature learning during fine-tuning.
Position: Solve Layerwise Linear Models First to Understand Neural Dynamical Phenomena (Neural Collapse, Emergence, Lazy/Rich Regime, and Grokking)
Feb 28, 2025


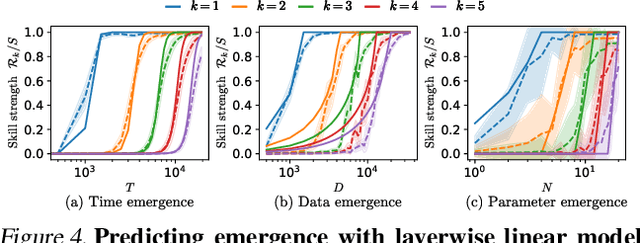
In physics, complex systems are often simplified into minimal, solvable models that retain only the core principles. In machine learning, layerwise linear models (e.g., linear neural networks) act as simplified representations of neural network dynamics. These models follow the dynamical feedback principle, which describes how layers mutually govern and amplify each other's evolution. This principle extends beyond the simplified models, successfully explaining a wide range of dynamical phenomena in deep neural networks, including neural collapse, emergence, lazy and rich regimes, and grokking. In this position paper, we call for the use of layerwise linear models retaining the core principles of neural dynamical phenomena to accelerate the science of deep learning.