 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranslate, then Detect: Leveraging Machine Translation for Cross-Lingual Toxicity Classification
Sep 17, 2025



Multilingual toxicity detection remains a significant challenge due to the scarcity of training data and resources for many languages. While prior work has leveraged the translate-test paradigm to support cross-lingual transfer across a range of classification tasks, the utility of translation in supporting toxicity detection at scale remains unclear. In this work, we conduct a comprehensive comparison of translation-based and language-specific/multilingual classification pipelines. We find that translation-based pipelines consistently outperform out-of-distribution classifiers in 81.3% of cases (13 of 16 languages), with translation benefits strongly correlated with both the resource level of the target language and the quality of the machine translation (MT) system. Our analysis reveals that traditional classifiers outperform large language model (LLM) judges, with this advantage being particularly pronounced for low-resource languages, where translate-classify methods dominate translate-judge approaches in 6 out of 7 cases. We additionally show that MT-specific fine-tuning on LLMs yields lower refusal rates compared to standard instruction-tuned models, but it can negatively impact toxicity detection accuracy for low-resource languages. These findings offer actionable guidance for practitioners developing scalable multilingual content moderation systems.
AbstentionBench: Reasoning LLMs Fail on Unanswerable Questions
Jun 10, 2025



For Large Language Models (LLMs) to be reliably deployed in both everyday and high-stakes domains, knowing when not to answer is equally critical as answering correctly. Real-world user queries, which can be underspecified, ill-posed, or fundamentally unanswerable, require LLMs to reason about uncertainty and selectively abstain -- i.e., refuse to answer definitively. However, abstention remains understudied, without a systematic evaluation framework for modern LLMs. In this work, we introduce AbstentionBench, a large-scale benchmark for holistically evaluating abstention across 20 diverse datasets, including questions with unknown answers, underspecification, false premises, subjective interpretations, and outdated information. Evaluating 20 frontier LLMs reveals abstention is an unsolved problem, and one where scaling models is of little use. While recent reasoning LLMs have shown impressive results in complex problem solving, surprisingly, we find that reasoning fine-tuning degrades abstention (by $24\%$ on average), even for math and science domains on which reasoning models are explicitly trained. We find that while a carefully crafted system prompt can boost abstention in practice, it does not resolve models' fundamental inability to reason about uncertainty. We release AbstentionBench to foster research into advancing LLM reliability.
Chained Tuning Leads to Biased Forgetting
Dec 21, 2024



Large language models (LLMs) are often fine-tuned for use on downstream tasks, though this can degrade capabilities learned during previous training. This phenomenon, often referred to as catastrophic forgetting, has important potential implications for the safety of deployed models. In this work, we first show that models trained on downstream tasks forget their safety tuning to a greater extent than models trained in the opposite order.Second, we show that forgetting disproportionately impacts safety information about certain groups. To quantify this phenomenon, we define a new metric we term biased forgetting. We conduct a systematic evaluation of the effects of task ordering on forgetting and apply mitigations that can help the model recover from the forgetting observed. We hope our findings can better inform methods for chaining the finetuning of LLMs in continual learning settings to enable training of safer and less toxic models.
On the Role of Speech Data in Reducing Toxicity Detection Bias
Nov 12, 2024



Text toxicity detection systems exhibit significant biases, producing disproportionate rates of false positives on samples mentioning demographic groups. But what about toxicity detection in speech? To investigate the extent to which text-based biases are mitigated by speech-based systems, we produce a set of high-quality group annotations for the multilingual MuTox dataset, and then leverage these annotations to systematically compare speech- and text-based toxicity classifiers. Our findings indicate that access to speech data during inference supports reduced bias against group mentions, particularly for ambiguous and disagreement-inducing samples. Our results also suggest that improving classifiers, rather than transcription pipelines, is more helpful for reducing group bias. We publicly release our annotations and provide recommendations for future toxicity dataset construction.
The Multiple Dimensions of Spuriousness in Machine Learning
Nov 07, 2024Learning correlations from data forms the foundation of today's machine learning (ML) and artificial intelligence (AI) research. While such an approach enables the automatic discovery of patterned relationships within big data corpora, it is susceptible to failure modes when unintended correlations are captured. This vulnerability has expanded interest in interrogating spuriousness, often critiqued as an impediment to model performance, fairness, and robustness. In this article, we trace deviations from the conventional definition of statistical spuriousness-which denotes a non-causal observation arising from either coincidence or confounding variables-to articulate how ML researchers make sense of spuriousness in practice. Drawing on a broad survey of ML literature, we conceptualize the "multiple dimensions of spuriousness," encompassing: relevance ("Models should only use correlations that are relevant to the task."), generalizability ("Models should only use correlations that generalize to unseen data"), human-likeness ("Models should only use correlations that a human would use to perform the same task"), and harmfulness ("Models should only use correlations that are not harmful"). These dimensions demonstrate that ML spuriousness goes beyond the causal/non-causal dichotomy and that the disparate interpretative paths researchers choose could meaningfully influence the trajectory of ML development. By underscoring how a fundamental problem in ML is contingently negotiated in research contexts, we contribute to ongoing debates about responsible practices in AI development.
Reassessing the Validity of Spurious Correlations Benchmarks
Sep 06, 2024



Neural networks can fail when the data contains spurious correlations. To understand this phenomenon, researchers have proposed numerous spurious correlations benchmarks upon which to evaluate mitigation methods. However, we observe that these benchmarks exhibit substantial disagreement, with the best methods on one benchmark performing poorly on another. We explore this disagreement, and examine benchmark validity by defining three desiderata that a benchmark should satisfy in order to meaningfully evaluate methods. Our results have implications for both benchmarks and mitigations: we find that certain benchmarks are not meaningful measures of method performance, and that several methods are not sufficiently robust for widespread use. We present a simple recipe for practitioners to choose methods using the most similar benchmark to their given problem.
Towards Geographic Inclusion in the Evaluation of Text-to-Image Models
May 07, 2024



Rapid progress in text-to-image generative models coupled with their deployment for visual content creation has magnified the importance of thoroughly evaluating their performance and identifying potential biases. In pursuit of models that generate images that are realistic, diverse, visually appealing, and consistent with the given prompt, researchers and practitioners often turn to automated metrics to facilitate scalable and cost-effective performance profiling. However, commonly-used metrics often fail to account for the full diversity of human preference; often even in-depth human evaluations face challenges with subjectivity, especially as interpretations of evaluation criteria vary across regions and cultures. In this work, we conduct a large, cross-cultural study to study how much annotators in Africa, Europe, and Southeast Asia vary in their perception of geographic representation, visual appeal, and consistency in real and generated images from state-of-the art public APIs. We collect over 65,000 image annotations and 20 survey responses. We contrast human annotations with common automated metrics, finding that human preferences vary notably across geographic location and that current metrics do not fully account for this diversity. For example, annotators in different locations often disagree on whether exaggerated, stereotypical depictions of a region are considered geographically representative. In addition, the utility of automatic evaluations is dependent on assumptions about their set-up, such as the alignment of feature extractors with human perception of object similarity or the definition of "appeal" captured in reference datasets used to ground evaluations. We recommend steps for improved automatic and human evaluations.
Simplicity Bias Leads to Amplified Performance Disparities
Dec 13, 2022



The simple idea that not all things are equally difficult has surprising implications when applied in a fairness context. In this work we explore how "difficulty" is model-specific, such that different models find different parts of a dataset challenging. When difficulty correlates with group information, we term this difficulty disparity. Drawing a connection with recent work exploring the inductive bias towards simplicity of SGD-trained models, we show that when such a disparity exists, it is further amplified by commonly-used models. We quantify this amplification factor across a range of settings aiming towards a fuller understanding of the role of model bias. We also present a challenge to the simplifying assumption that "fixing" a dataset is sufficient to ensure unbiased performance.
Modeling the Machine Learning Multiverse
Jun 13, 2022
Amid mounting concern about the reliability and credibility of machine learning research, we present a principled framework for making robust and generalizable claims: the Multiverse Analysis. Our framework builds upon the Multiverse Analysis (Steegen et al., 2016) introduced in response to psychology's own reproducibility crisis. To efficiently explore high-dimensional and often continuous ML search spaces, we model the multiverse with a Gaussian Process surrogate and apply Bayesian experimental design. Our framework is designed to facilitate drawing robust scientific conclusions about model performance, and thus our approach focuses on exploration rather than conventional optimization. In the first of two case studies, we investigate disputed claims about the relative merit of adaptive optimizers. Second, we synthesize conflicting research on the effect of learning rate on the large batch training generalization gap. For the machine learning community, the Multiverse Analysis is a simple and effective technique for identifying robust claims, for increasing transparency, and a step toward improved reproducibility.
The Effect of Task Ordering in Continual Learning
May 26, 2022
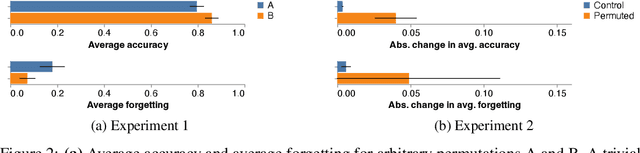
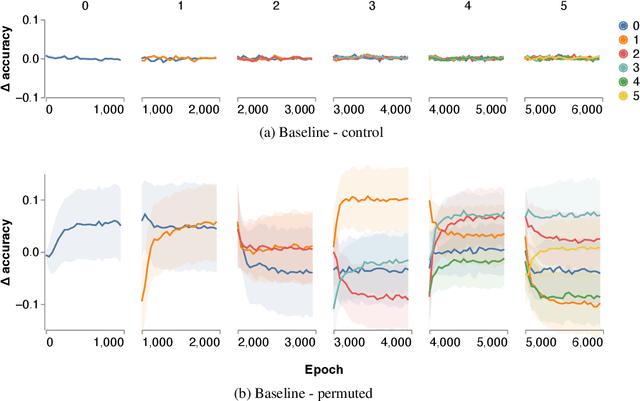
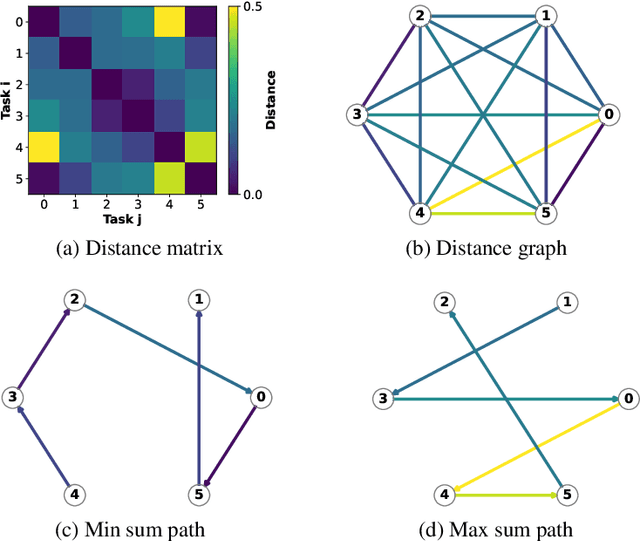
We investigate the effect of task ordering on continual learning performance. We conduct an extensive series of empirical experiments on synthetic and naturalistic datasets and show that reordering tasks significantly affects the amount of catastrophic forgetting. Connecting to the field of curriculum learning, we show that the effect of task ordering can be exploited to modify continual learning performance, and present a simple approach for doing so. Our method computes the distance between all pairs of tasks, where distance is defined as the source task curvature of a gradient step toward the target task. Using statistically rigorous methods and sound experimental design, we show that task ordering is an important aspect of continual learning that can be modified for improved performance.