 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong Range Arena: A Benchmark for Efficient Transformers
Nov 08, 2020
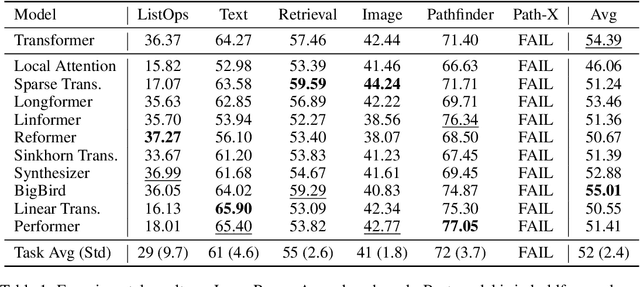
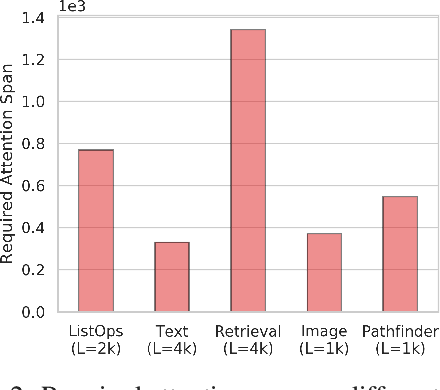
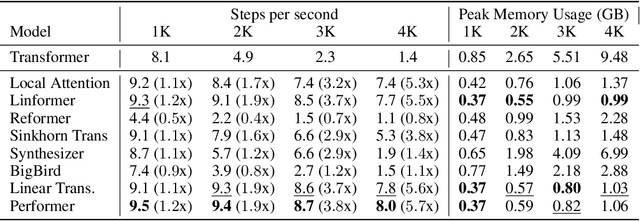
Transformers do not scale very well to long sequence lengths largely because of quadratic self-attention complexity. In the recent months, a wide spectrum of efficient, fast Transformers have been proposed to tackle this problem, more often than not claiming superior or comparable model quality to vanilla Transformer models. To this date, there is no well-established consensus on how to evaluate this class of models. Moreover, inconsistent benchmarking on a wide spectrum of tasks and datasets makes it difficult to assess relative model quality amongst many models. This paper proposes a systematic and unified benchmark, LRA, specifically focused on evaluating model quality under long-context scenarios. Our benchmark is a suite of tasks consisting of sequences ranging from $1K$ to $16K$ tokens, encompassing a wide range of data types and modalities such as text, natural, synthetic images, and mathematical expressions requiring similarity, structural, and visual-spatial reasoning. We systematically evaluate ten well-established long-range Transformer models (Reformers, Linformers, Linear Transformers, Sinkhorn Transformers, Performers, Synthesizers, Sparse Transformers, and Longformers) on our newly proposed benchmark suite. LRA paves the way towards better understanding this class of efficient Transformer models, facilitates more research in this direction, and presents new challenging tasks to tackle. Our benchmark code will be released at https://github.com/google-research/long-range-arena.
Transferring Inductive Biases through Knowledge Distillation
Jun 02, 2020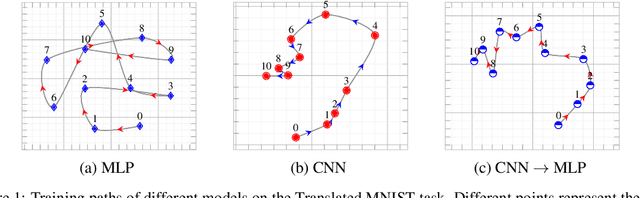
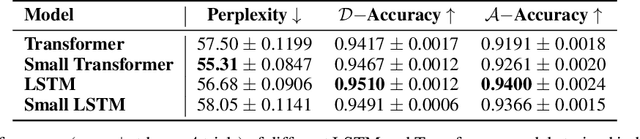
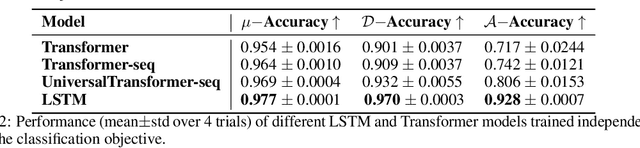
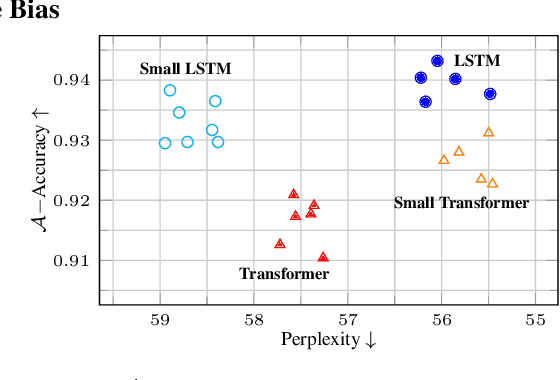
Having the right inductive biases can be crucial in many tasks or scenarios where data or computing resources are a limiting factor, or where training data is not perfectly representative of the conditions at test time. However, defining, designing and efficiently adapting inductive biases is not necessarily straightforward. In this paper, we explore the power of knowledge distillation for transferring the effect of inductive biases from one model to another. We consider families of models with different inductive biases, LSTMs vs. Transformers and CNNs vs. MLPs, in the context of tasks and scenarios where having the right inductive biases is critical. We study how the effect of inductive biases is transferred through knowledge distillation, in terms of not only performance but also different aspects of converged solutions.
Quantifying Attention Flow in Transformers
May 31, 2020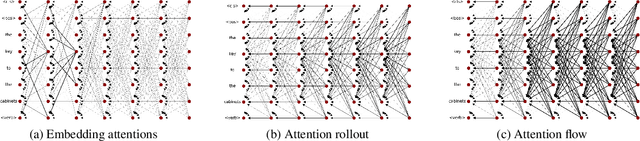
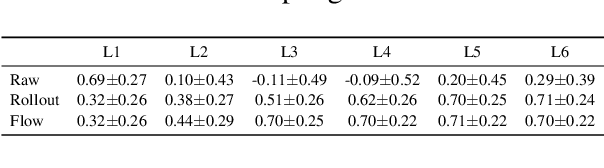
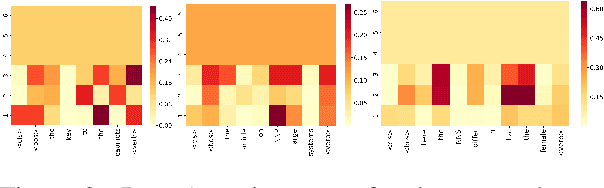

In the Transformer model, "self-attention" combines information from attended embeddings into the representation of the focal embedding in the next layer. Thus, across layers of the Transformer, information originating from different tokens gets increasingly mixed. This makes attention weights unreliable as explanations probes. In this paper, we consider the problem of quantifying this flow of information through self-attention. We propose two methods for approximating the attention to input tokens given attention weights, attention rollout and attention flow, as post hoc methods when we use attention weights as the relative relevance of the input tokens. We show that these methods give complementary views on the flow of information, and compared to raw attention, both yield higher correlations with importance scores of input tokens obtained using an ablation method and input gradients.
A Comparison of Architectures and Pretraining Methods for Contextualized Multilingual Word Embeddings
Dec 15, 2019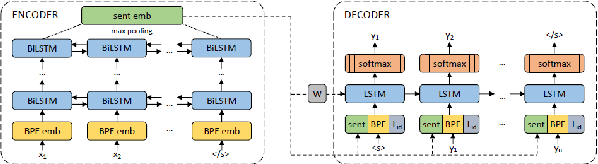

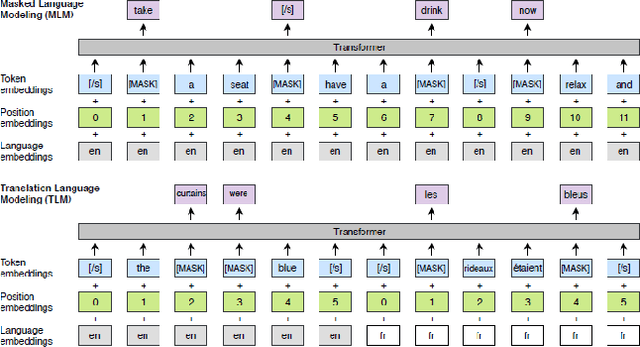
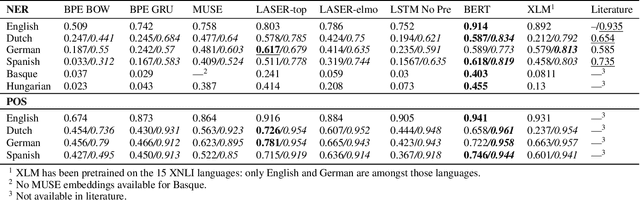
The lack of annotated data in many languages is a well-known challenge within the field of multilingual natural language processing (NLP). Therefore, many recent studies focus on zero-shot transfer learning and joint training across languages to overcome data scarcity for low-resource languages. In this work we (i) perform a comprehensive comparison of state-ofthe-art multilingual word and sentence encoders on the tasks of named entity recognition (NER) and part of speech (POS) tagging; and (ii) propose a new method for creating multilingual contextualized word embeddings, compare it to multiple baselines and show that it performs at or above state-of-theart level in zero-shot transfer settings. Finally, we show that our method allows for better knowledge sharing across languages in a joint training setting.
Blackbox meets blackbox: Representational Similarity and Stability Analysis of Neural Language Models and Brains
Jun 05, 2019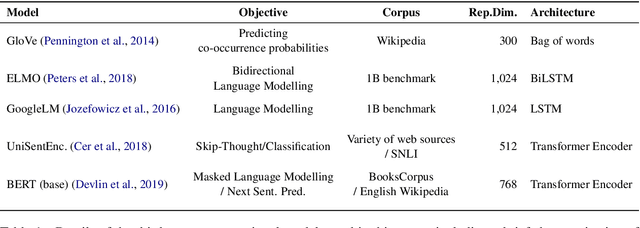
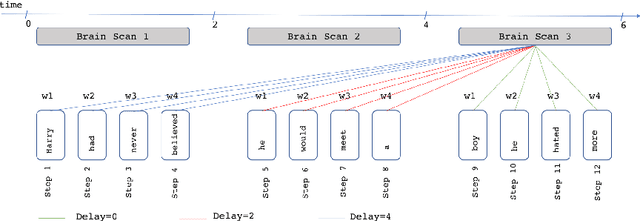
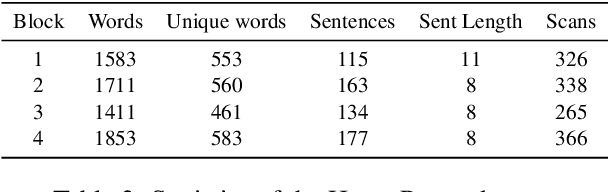
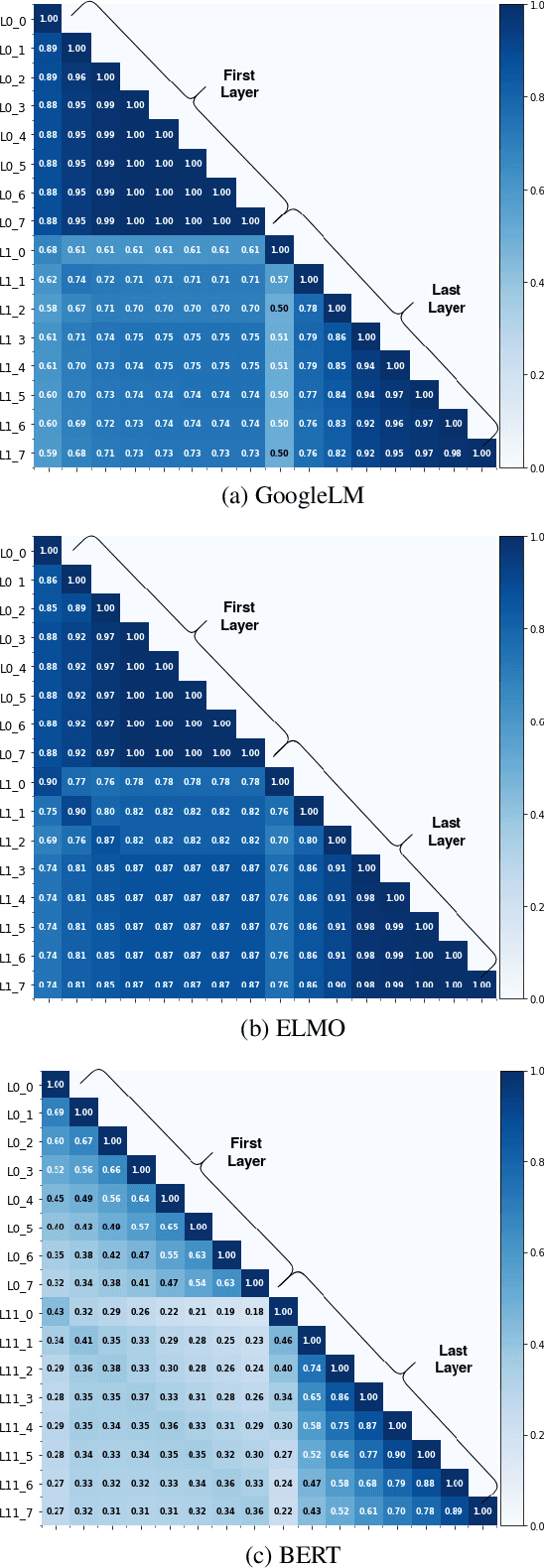
In this paper, we define and apply representational stability analysis (ReStA), an intuitive way of analyzing neural language models. ReStA is a variant of the popular representational similarity analysis (RSA) in cognitive neuroscience. While RSA can be used to compare representations in models, model components, and human brains, ReStA compares instances of the same model, while systematically varying single model parameter. Using ReStA, we study four recent and successful neural language models, and evaluate how sensitive their internal representations are to the amount of prior context. Using RSA, we perform a systematic study of how similar the representational spaces in the first and second (or higher) layers of these models are to each other and to patterns of activation in the human brain. Our results reveal surprisingly strong differences between language models, and give insights into where the deep linguistic processing, that integrates information over multiple sentences, is happening in these models. The combination of ReStA and RSA on models and brains allows us to start addressing the important question of what kind of linguistic processes we can hope to observe in fMRI brain imaging data. In particular, our results suggest that the data on story reading from Wehbe et al. (2014) contains a signal of shallow linguistic processing, but show no evidence on the more interesting deep linguistic processing.
Robust Evaluation of Language-Brain Encoding Experiments
Apr 04, 2019
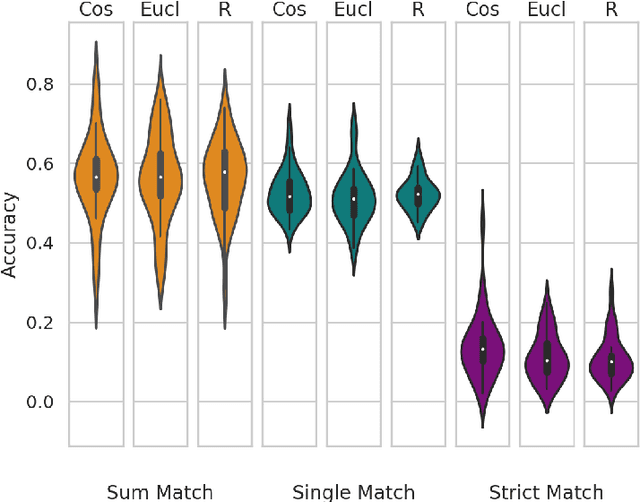
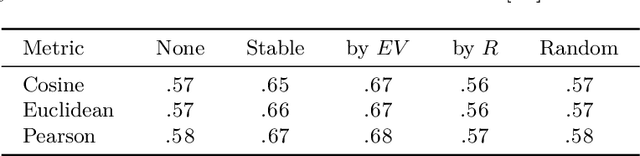
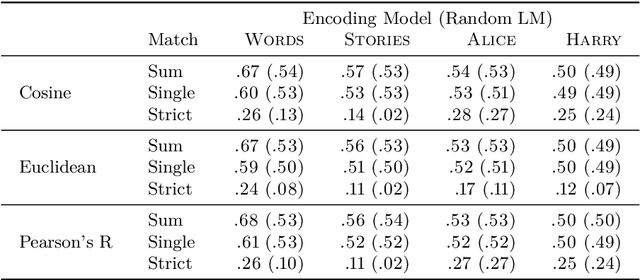
Language-brain encoding experiments evaluate the ability of language models to predict brain responses elicited by language stimuli. The evaluation scenarios for this task have not yet been standardized which makes it difficult to compare and interpret results. We perform a series of evaluation experiments with a consistent encoding setup and compute the results for multiple fMRI datasets. In addition, we test the sensitivity of the evaluation measures to randomized data and analyze the effect of voxel selection methods. Our experimental framework is publicly available to make modelling decisions more transparent and support reproducibility for future comparisons.
Incremental Reading for Question Answering
Jan 15, 2019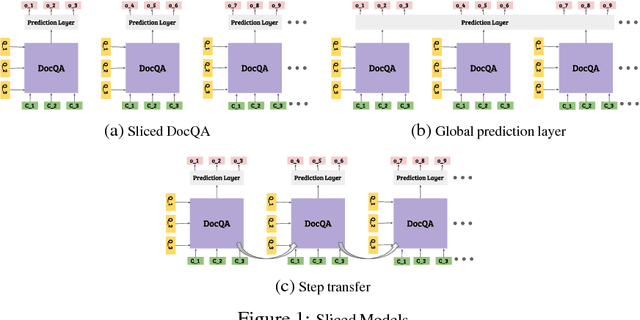

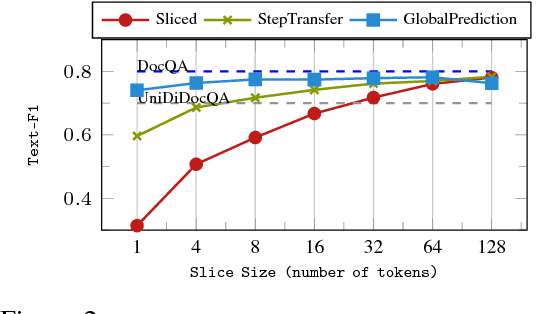
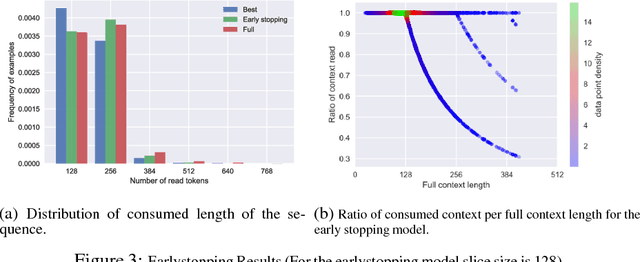
Any system which performs goal-directed continual learning must not only learn incrementally but process and absorb information incrementally. Such a system also has to understand when its goals have been achieved. In this paper, we consider these issues in the context of question answering. Current state-of-the-art question answering models reason over an entire passage, not incrementally. As we will show, naive approaches to incremental reading, such as restriction to unidirectional language models in the model, perform poorly. We present extensions to the DocQA [2] model to allow incremental reading without loss of accuracy. The model also jointly learns to provide the best answer given the text that is seen so far and predict whether this best-so-far answer is sufficient.
Experiential, Distributional and Dependency-based Word Embeddings have Complementary Roles in Decoding Brain Activity
Nov 25, 2017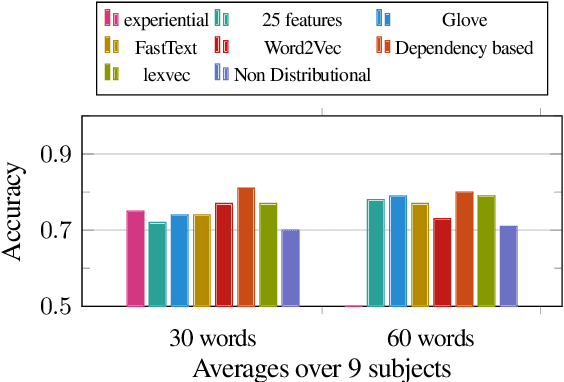
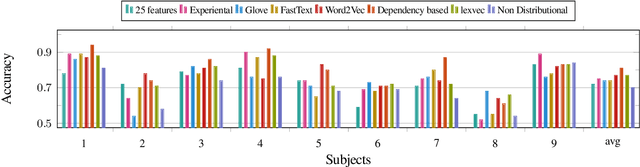
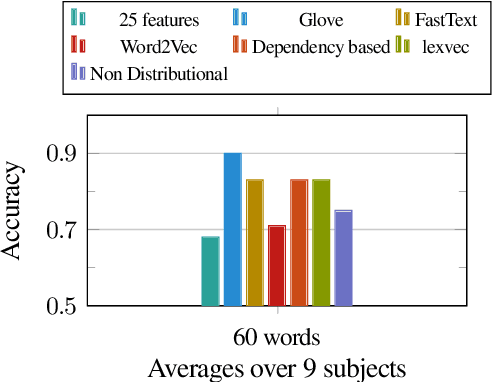
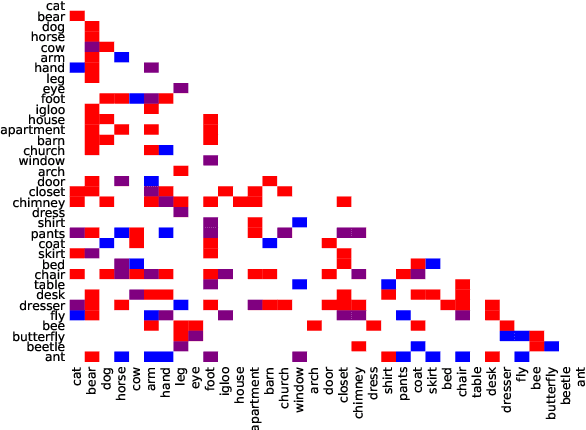
We evaluate 8 different word embedding models on their usefulness for predicting the neural activation patterns associated with concrete nouns. The models we consider include an experiential model, based on crowd-sourced association data, several popular neural and distributional models, and a model that reflects the syntactic context of words (based on dependency parses). Our goal is to assess the cognitive plausibility of these various embedding models, and understand how we can further improve our methods for interpreting brain imaging data. We show that neural word embedding models exhibit superior performance on the tasks we consider, beating experiential word representation model. The syntactically informed model gives the overall best performance when predicting brain activation patterns from word embeddings; whereas the GloVe distributional method gives the overall best performance when predicting in the reverse direction (words vectors from brain images). Interestingly, however, the error patterns of these different models are markedly different. This may support the idea that the brain uses different systems for processing different kinds of words. Moreover, we suggest that taking the relative strengths of different embedding models into account will lead to better models of the brain activity associated with words.