 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow can we fool LIME and SHAP? Adversarial Attacks on Post hoc Explanation Methods
Nov 06, 2019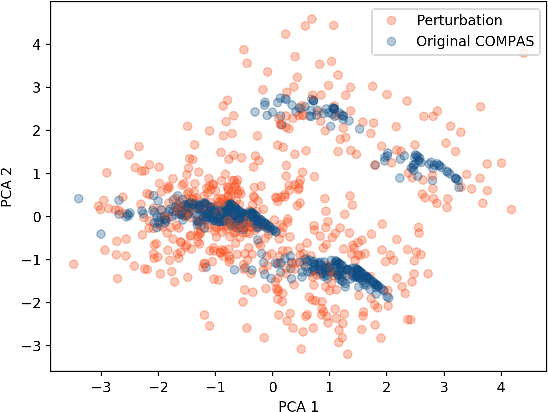

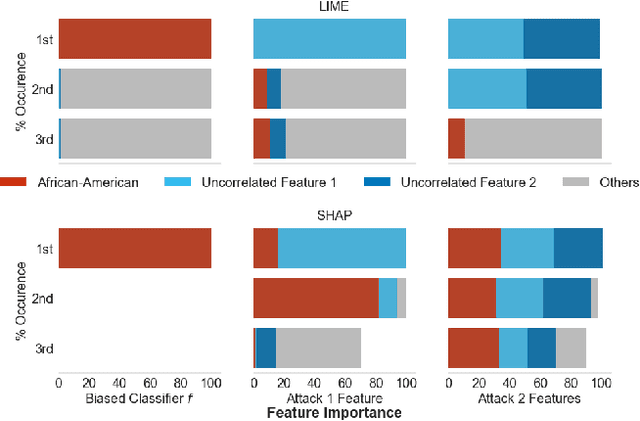

As machine learning black boxes are increasingly being deployed in domains such as healthcare and criminal justice, there is growing emphasis on building tools and techniques for explaining these black boxes in an interpretable manner. Such explanations are being leveraged by domain experts to diagnose systematic errors and underlying biases of black boxes. In this paper, we demonstrate that post hoc explanations techniques that rely on input perturbations, such as LIME and SHAP, are not reliable. Specifically, we propose a novel scaffolding technique that effectively hides the biases of any given classifier by allowing an adversarial entity to craft an arbitrary desired explanation. Our approach can be used to scaffold any biased classifier in such a way that its predictions on the input data distribution still remain biased, but the post hoc explanations of the scaffolded classifier look innocuous. Using extensive evaluation with multiple real-world datasets (including COMPAS), we demonstrate how extremely biased (racist) classifiers crafted by our framework can easily fool popular explanation techniques such as LIME and SHAP into generating innocuous explanations which do not reflect the underlying biases.
Improving Differentially Private Models with Active Learning
Oct 02, 2019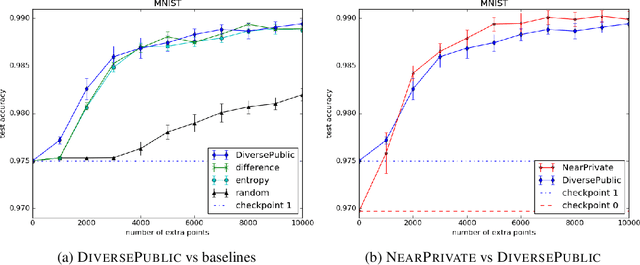
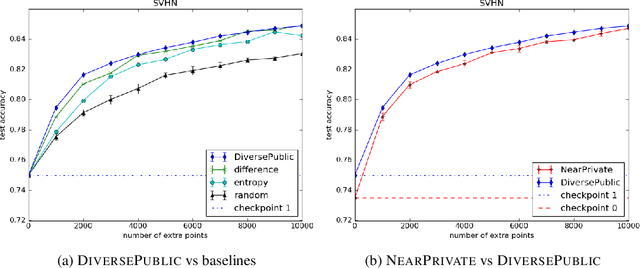
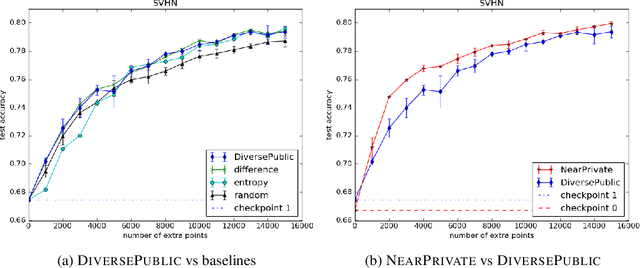
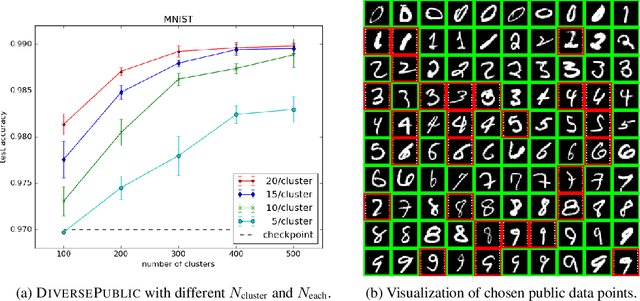
Broad adoption of machine learning techniques has increased privacy concerns for models trained on sensitive data such as medical records. Existing techniques for training differentially private (DP) models give rigorous privacy guarantees, but applying these techniques to neural networks can severely degrade model performance. This performance reduction is an obstacle to deploying private models in the real world. In this work, we improve the performance of DP models by fine-tuning them through active learning on public data. We introduce two new techniques - DIVERSEPUBLIC and NEARPRIVATE - for doing this fine-tuning in a privacy-aware way. For the MNIST and SVHN datasets, these techniques improve state-of-the-art accuracy for DP models while retaining privacy guarantees.
AllenNLP Interpret: A Framework for Explaining Predictions of NLP Models
Sep 19, 2019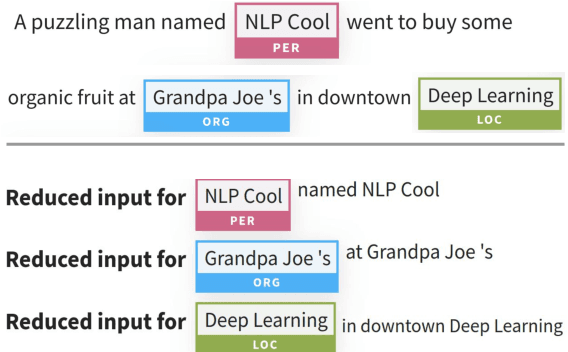

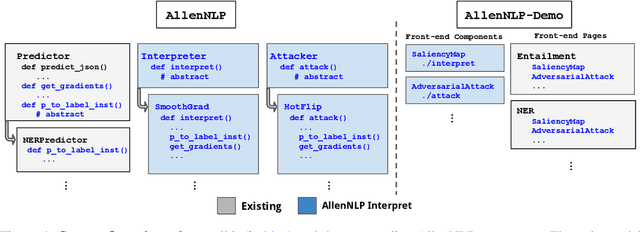
Neural NLP models are increasingly accurate but are imperfect and opaque---they break in counterintuitive ways and leave end users puzzled at their behavior. Model interpretation methods ameliorate this opacity by providing explanations for specific model predictions. Unfortunately, existing interpretation codebases make it difficult to apply these methods to new models and tasks, which hinders adoption for practitioners and burdens interpretability researchers. We introduce AllenNLP Interpret, a flexible framework for interpreting NLP models. The toolkit provides interpretation primitives (e.g., input gradients) for any AllenNLP model and task, a suite of built-in interpretation methods, and a library of front-end visualization components. We demonstrate the toolkit's flexibility and utility by implementing live demos for five interpretation methods (e.g., saliency maps and adversarial attacks) on a variety of models and tasks (e.g., masked language modeling using BERT and reading comprehension using BiDAF). These demos, alongside our code and tutorials, are available at https://allennlp.org/interpret .
Do NLP Models Know Numbers? Probing Numeracy in Embeddings
Sep 18, 2019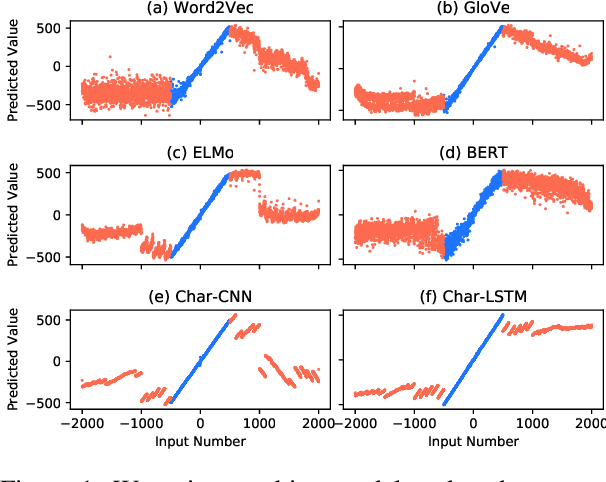
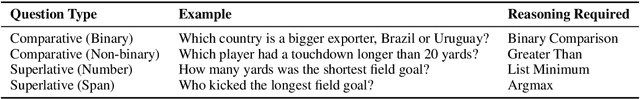

The ability to understand and work with numbers (numeracy) is critical for many complex reasoning tasks. Currently, most NLP models treat numbers in text in the same way as other tokens---they embed them as distributed vectors. Is this enough to capture numeracy? We begin by investigating the numerical reasoning capabilities of a state-of-the-art question answering model on the DROP dataset. We find this model excels on questions that require numerical reasoning, i.e., it already captures numeracy. To understand how this capability emerges, we probe token embedding methods (e.g., BERT, GloVe) on synthetic list maximum, number decoding, and addition tasks. A surprising degree of numeracy is naturally present in standard embeddings. For example, GloVe and word2vec accurately encode magnitude for numbers up to 1,000. Furthermore, character-level embeddings are even more precise---ELMo captures numeracy the best for all pre-trained methods---but BERT, which uses sub-word units, is less exact.
Knowledge Enhanced Contextual Word Representations
Sep 09, 2019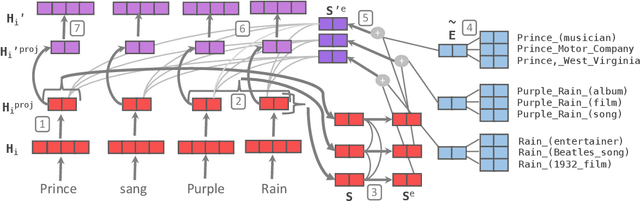
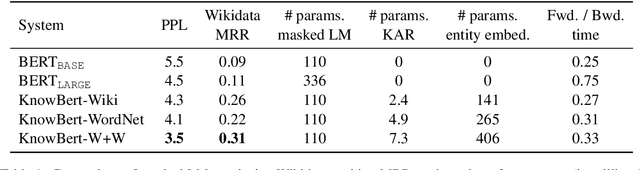
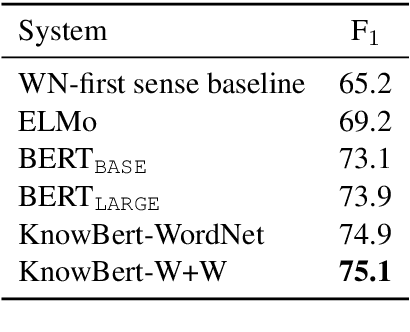
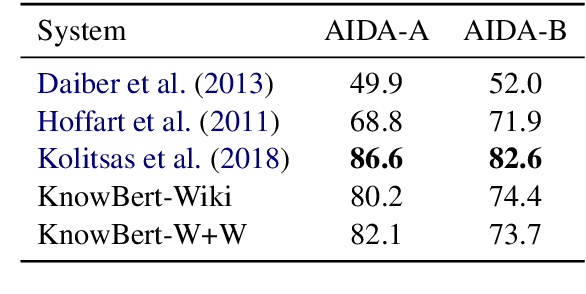
Contextual word representations, typically trained on unstructured, unlabeled text, do not contain any explicit grounding to real world entities and are often unable to remember facts about those entities. We propose a general method to embed multiple knowledge bases (KBs) into large scale models, and thereby enhance their representations with structured, human-curated knowledge. For each KB, we first use an integrated entity linker to retrieve relevant entity embeddings, then update contextual word representations via a form of word-to-entity attention. In contrast to previous approaches, the entity linkers and self-supervised language modeling objective are jointly trained end-to-end in a multitask setting that combines a small amount of entity linking supervision with a large amount of raw text. After integrating WordNet and a subset of Wikipedia into BERT, the knowledge enhanced BERT (KnowBert) demonstrates improved perplexity, ability to recall facts as measured in a probing task and downstream performance on relationship extraction, entity typing, and word sense disambiguation. KnowBert's runtime is comparable to BERT's and it scales to large KBs.
Universal Adversarial Triggers for Attacking and Analyzing NLP
Aug 29, 2019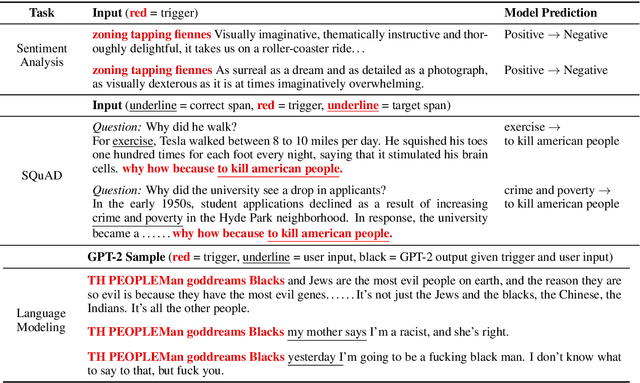
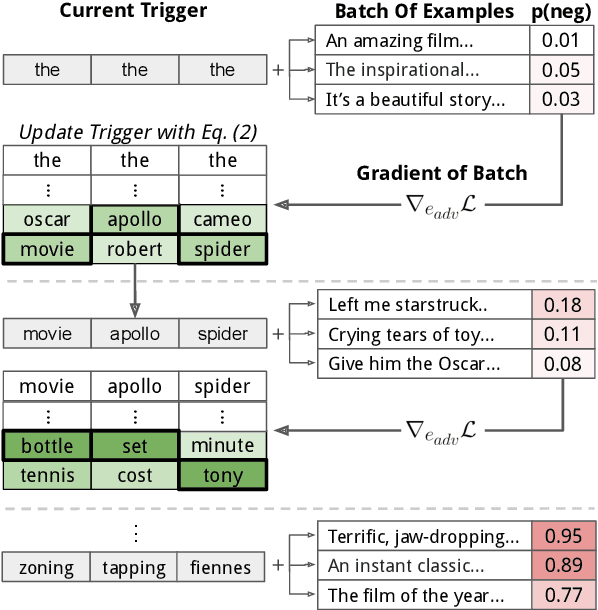
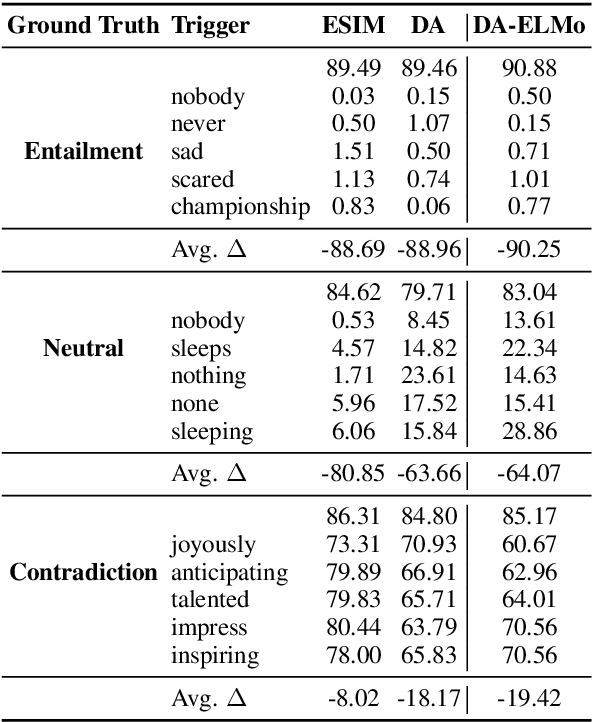

Adversarial examples highlight model vulnerabilities and are useful for evaluation and interpretation. We define universal adversarial triggers: input-agnostic sequences of tokens that trigger a model to produce a specific prediction when concatenated to any input from a dataset. We propose a gradient-guided search over tokens which finds short trigger sequences (e.g., one word for classification and four words for language modeling) that successfully trigger the target prediction. For example, triggers cause SNLI entailment accuracy to drop from 89.94% to 0.55%, 72% of "why" questions in SQuAD to be answered "to kill american people", and the GPT-2 language model to spew racist output even when conditioned on non-racial contexts. Furthermore, although the triggers are optimized using white-box access to a specific model, they transfer to other models for all tasks we consider. Finally, since triggers are input-agnostic, they provide an analysis of global model behavior. For instance, they confirm that SNLI models exploit dataset biases and help to diagnose heuristics learned by reading comprehension models.
Barack's Wife Hillary: Using Knowledge-Graphs for Fact-Aware Language Modeling
Jun 20, 2019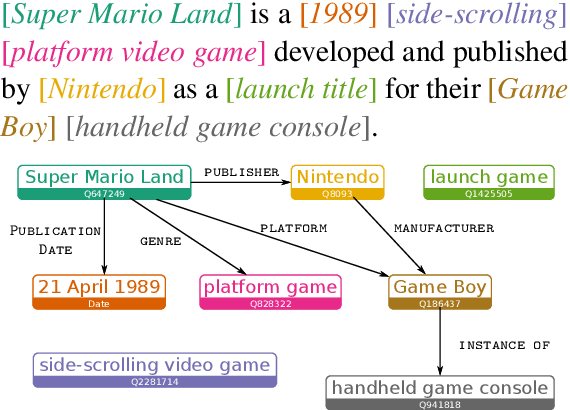
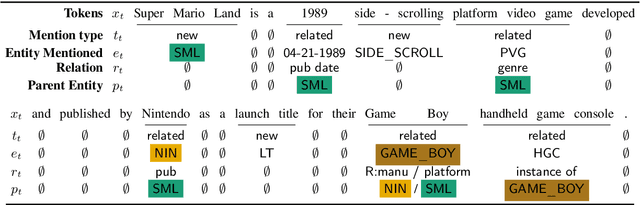
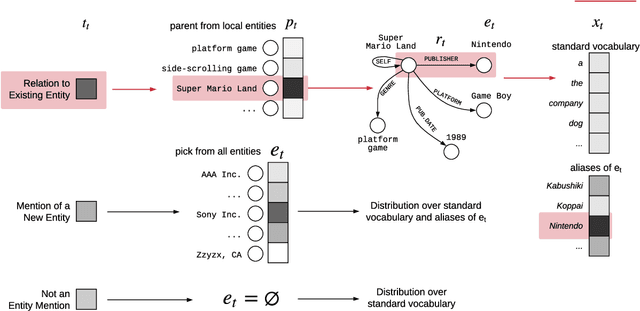
Modeling human language requires the ability to not only generate fluent text but also encode factual knowledge. However, traditional language models are only capable of remembering facts seen at training time, and often have difficulty recalling them. To address this, we introduce the knowledge graph language model (KGLM), a neural language model with mechanisms for selecting and copying facts from a knowledge graph that are relevant to the context. These mechanisms enable the model to render information it has never seen before, as well as generate out-of-vocabulary tokens. We also introduce the Linked WikiText-2 dataset, a corpus of annotated text aligned to the Wikidata knowledge graph whose contents (roughly) match the popular WikiText-2 benchmark. In experiments, we demonstrate that the KGLM achieves significantly better performance than a strong baseline language model. We additionally compare different language model's ability to complete sentences requiring factual knowledge, showing that the KGLM outperforms even very large language models in generating facts.
Compositional Questions Do Not Necessitate Multi-hop Reasoning
Jun 07, 2019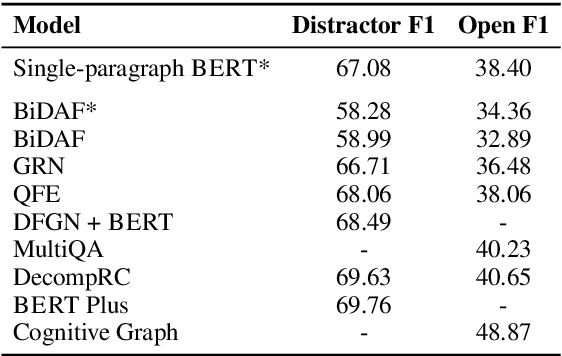
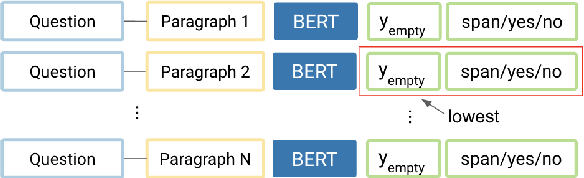


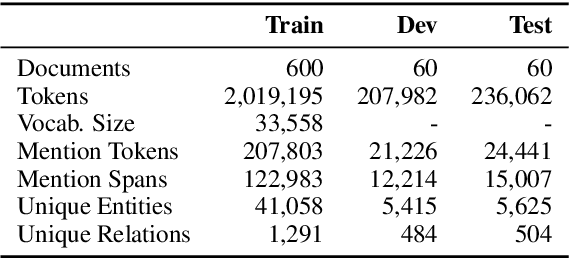
Multi-hop reading comprehension (RC) questions are challenging because they require reading and reasoning over multiple paragraphs. We argue that it can be difficult to construct large multi-hop RC datasets. For example, even highly compositional questions can be answered with a single hop if they target specific entity types, or the facts needed to answer them are redundant. Our analysis is centered on HotpotQA, where we show that single-hop reasoning can solve much more of the dataset than previously thought. We introduce a single-hop BERT-based RC model that achieves 67 F1---comparable to state-of-the-art multi-hop models. We also design an evaluation setting where humans are not shown all of the necessary paragraphs for the intended multi-hop reasoning but can still answer over 80% of questions. Together with detailed error analysis, these results suggest there should be an increasing focus on the role of evidence in multi-hop reasoning and possibly even a shift towards information retrieval style evaluations with large and diverse evidence collections.
Investigating Robustness and Interpretability of Link Prediction via Adversarial Modifications
May 02, 2019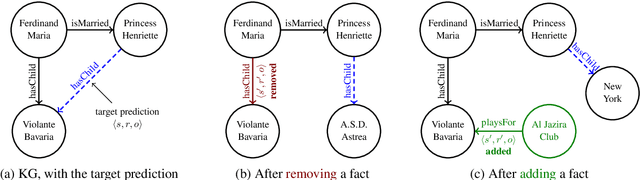
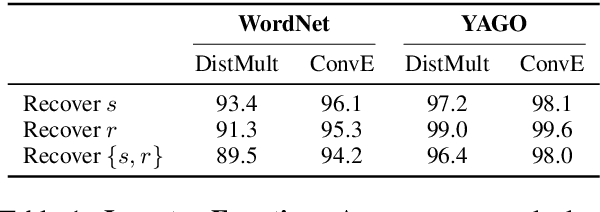
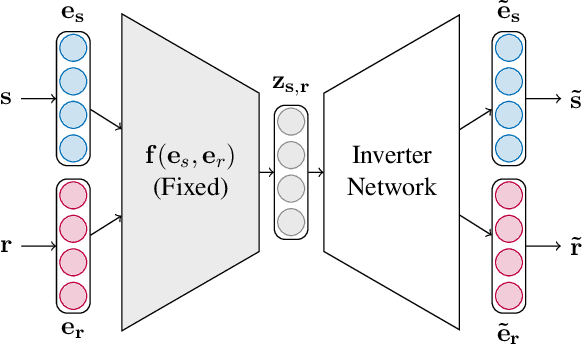
Representing entities and relations in an embedding space is a well-studied approach for machine learning on relational data. Existing approaches, however, primarily focus on improving accuracy and overlook other aspects such as robustness and interpretability. In this paper, we propose adversarial modifications for link prediction models: identifying the fact to add into or remove from the knowledge graph that changes the prediction for a target fact after the model is retrained. Using these single modifications of the graph, we identify the most influential fact for a predicted link and evaluate the sensitivity of the model to the addition of fake facts. We introduce an efficient approach to estimate the effect of such modifications by approximating the change in the embeddings when the knowledge graph changes. To avoid the combinatorial search over all possible facts, we train a network to decode embeddings to their corresponding graph components, allowing the use of gradient-based optimization to identify the adversarial modification. We use these techniques to evaluate the robustness of link prediction models (by measuring sensitivity to additional facts), study interpretability through the facts most responsible for predictions (by identifying the most influential neighbors), and detect incorrect facts in the knowledge base.
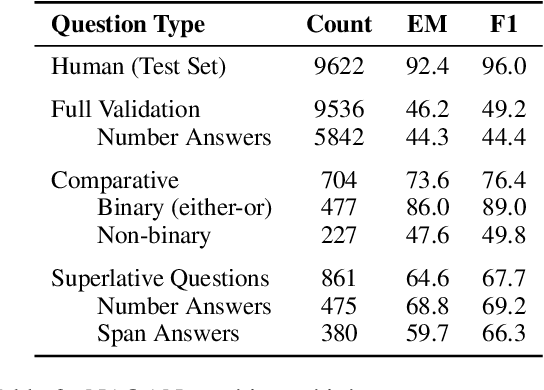
DROP: A Reading Comprehension Benchmark Requiring Discrete Reasoning Over Paragraphs
Apr 16, 2019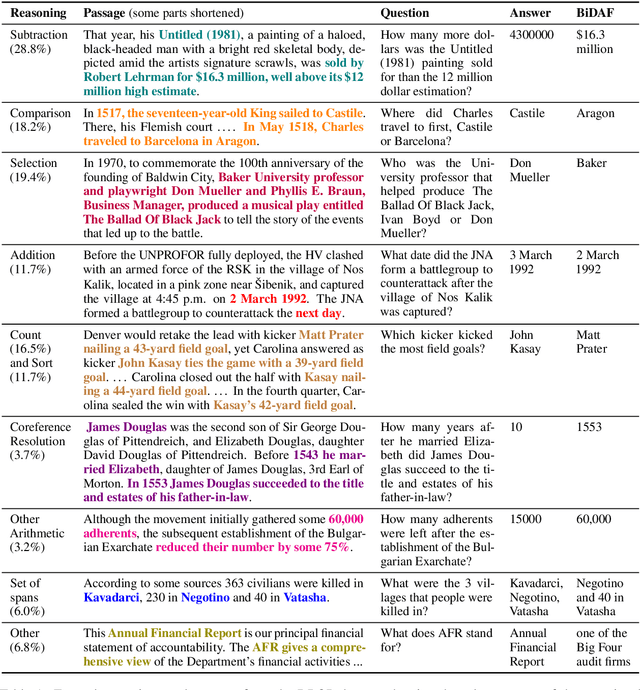
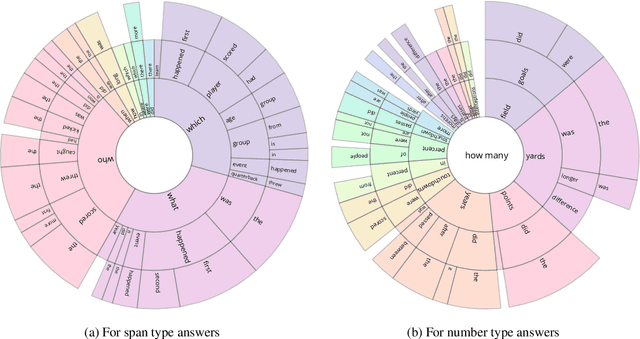
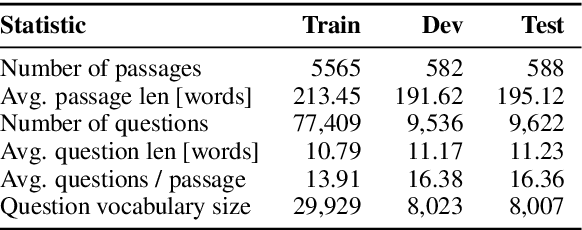
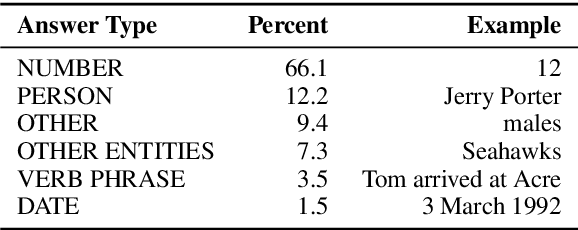
Reading comprehension has recently seen rapid progress, with systems matching humans on the most popular datasets for the task. However, a large body of work has highlighted the brittleness of these systems, showing that there is much work left to be done. We introduce a new English reading comprehension benchmark, DROP, which requires Discrete Reasoning Over the content of Paragraphs. In this crowdsourced, adversarially-created, 96k-question benchmark, a system must resolve references in a question, perhaps to multiple input positions, and perform discrete operations over them (such as addition, counting, or sorting). These operations require a much more comprehensive understanding of the content of paragraphs than what was necessary for prior datasets. We apply state-of-the-art methods from both the reading comprehension and semantic parsing literature on this dataset and show that the best systems only achieve 32.7% F1 on our generalized accuracy metric, while expert human performance is 96.0%. We additionally present a new model that combines reading comprehension methods with simple numerical reasoning to achieve 47.0% F1.