 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMISGENDERED: Limits of Large Language Models in Understanding Pronouns
Jun 06, 2023Content Warning: This paper contains examples of misgendering and erasure that could be offensive and potentially triggering. Gender bias in language technologies has been widely studied, but research has mostly been restricted to a binary paradigm of gender. It is essential also to consider non-binary gender identities, as excluding them can cause further harm to an already marginalized group. In this paper, we comprehensively evaluate popular language models for their ability to correctly use English gender-neutral pronouns (e.g., singular they, them) and neo-pronouns (e.g., ze, xe, thon) that are used by individuals whose gender identity is not represented by binary pronouns. We introduce MISGENDERED, a framework for evaluating large language models' ability to correctly use preferred pronouns, consisting of (i) instances declaring an individual's pronoun, followed by a sentence with a missing pronoun, and (ii) an experimental setup for evaluating masked and auto-regressive language models using a unified method. When prompted out-of-the-box, language models perform poorly at correctly predicting neo-pronouns (averaging 7.6% accuracy) and gender-neutral pronouns (averaging 31.0% accuracy). This inability to generalize results from a lack of representation of non-binary pronouns in training data and memorized associations. Few-shot adaptation with explicit examples in the prompt improves the performance but plateaus at only 45.4% for neo-pronouns. We release the full dataset, code, and demo at https://tamannahossainkay.github.io/misgendered/
PURR: Efficiently Editing Language Model Hallucinations by Denoising Language Model Corruptions
May 24, 2023



The remarkable capabilities of large language models have been accompanied by a persistent drawback: the generation of false and unsubstantiated claims commonly known as "hallucinations". To combat this issue, recent research has introduced approaches that involve editing and attributing the outputs of language models, particularly through prompt-based editing. However, the inference cost and speed of using large language models for editing currently bottleneck prompt-based methods. These bottlenecks motivate the training of compact editors, which is challenging due to the scarcity of training data for this purpose. To overcome these challenges, we exploit the power of large language models to introduce corruptions (i.e., noise) into text and subsequently fine-tune compact editors to denoise the corruptions by incorporating relevant evidence. Our methodology is entirely unsupervised and provides us with faux hallucinations for training in any domain. Our Petite Unsupervised Research and Revision model, PURR, not only improves attribution over existing editing methods based on fine-tuning and prompting, but also achieves faster execution times by orders of magnitude.
Coverage-based Example Selection for In-Context Learning
May 24, 2023In-context learning (ICL), the ability of large language models to perform novel tasks by conditioning on a prompt with a few task examples, requires demonstrations that are informative about the test instance. The standard approach of independently selecting the most similar examples selects redundant demonstrations while overlooking important information. This work proposes a framework for assessing the informativeness of demonstrations based on their coverage of salient aspects (e.g., reasoning patterns) of the test input. Using this framework, we show that contextual token embeddings effectively capture these salient aspects, and their recall measured using BERTScore-Recall (BSR) yields a reliable measure of informativeness. Further, we extend recall metrics like BSR to propose their set versions to find maximally informative sets of demonstrations. On 6 complex compositional generation tasks and 7 diverse LLMs, we show that Set-BSR outperforms the standard similarity-based approach by up to 16% on average and, despite being learning-free, often surpasses methods that leverage task or LLM-specific training.
Post Hoc Explanations of Language Models Can Improve Language Models
May 19, 2023



Large Language Models (LLMs) have demonstrated remarkable capabilities in performing complex tasks. Moreover, recent research has shown that incorporating human-annotated rationales (e.g., Chain-of- Thought prompting) during in-context learning can significantly enhance the performance of these models, particularly on tasks that require reasoning capabilities. However, incorporating such rationales poses challenges in terms of scalability as this requires a high degree of human involvement. In this work, we present a novel framework, Amplifying Model Performance by Leveraging In-Context Learning with Post Hoc Explanations (AMPLIFY), which addresses the aforementioned challenges by automating the process of rationale generation. To this end, we leverage post hoc explanation methods which output attribution scores (explanations) capturing the influence of each of the input features on model predictions. More specifically, we construct automated natural language rationales that embed insights from post hoc explanations to provide corrective signals to LLMs. Extensive experimentation with real-world datasets demonstrates that our framework, AMPLIFY, leads to prediction accuracy improvements of about 10-25% over a wide range of tasks, including those where prior approaches which rely on human-annotated rationales such as Chain-of-Thought prompting fall short. Our work makes one of the first attempts at highlighting the potential of post hoc explanations as valuable tools for enhancing the effectiveness of LLMs. Furthermore, we conduct additional empirical analyses and ablation studies to demonstrate the impact of each of the components of AMPLIFY, which, in turn, lead to critical insights for refining in-context learning.
TABLET: Learning From Instructions For Tabular Data
Apr 25, 2023



Acquiring high-quality data is often a significant challenge in training machine learning (ML) models for tabular prediction, particularly in privacy-sensitive and costly domains like medicine and finance. Providing natural language instructions to large language models (LLMs) offers an alternative solution. However, it is unclear how effectively instructions leverage the knowledge in LLMs for solving tabular prediction problems. To address this gap, we introduce TABLET, a benchmark of 20 diverse tabular datasets annotated with instructions that vary in their phrasing, granularity, and technicality. Additionally, TABLET includes the instructions' logic and structured modifications to the instructions. We find in-context instructions increase zero-shot F1 performance for Flan-T5 11b by 44% on average and 13% for ChatGPT on TABLET. Also, we explore the limitations of using LLMs for tabular prediction in our benchmark by evaluating instruction faithfulness. We find LLMs often ignore instructions and fail to predict specific instances correctly, even with examples. Our analysis on TABLET shows that, while instructions help LLM performance, learning from instructions for tabular data requires new capabilities.
ART: Automatic multi-step reasoning and tool-use for large language models
Mar 16, 2023



Large language models (LLMs) can perform complex reasoning in few- and zero-shot settings by generating intermediate chain of thought (CoT) reasoning steps. Further, each reasoning step can rely on external tools to support computation beyond the core LLM capabilities (e.g. search/running code). Prior work on CoT prompting and tool use typically requires hand-crafting task-specific demonstrations and carefully scripted interleaving of model generations with tool use. We introduce Automatic Reasoning and Tool-use (ART), a framework that uses frozen LLMs to automatically generate intermediate reasoning steps as a program. Given a new task to solve, ART selects demonstrations of multi-step reasoning and tool use from a task library. At test time, ART seamlessly pauses generation whenever external tools are called, and integrates their output before resuming generation. ART achieves a substantial improvement over few-shot prompting and automatic CoT on unseen tasks in the BigBench and MMLU benchmarks, and matches performance of hand-crafted CoT prompts on a majority of these tasks. ART is also extensible, and makes it easy for humans to improve performance by correcting errors in task-specific programs or incorporating new tools, which we demonstrate by drastically improving performance on select tasks with minimal human intervention.
Do Embodied Agents Dream of Pixelated Sheep?: Embodied Decision Making using Language Guided World Modelling
Jan 28, 2023Reinforcement learning (RL) agents typically learn tabula rasa, without prior knowledge of the world, which makes learning complex tasks with sparse rewards difficult. If initialized with knowledge of high-level subgoals and transitions between subgoals, RL agents could utilize this Abstract World Model (AWM) for planning and exploration. We propose using few-shot large language models (LLMs) to hypothesize an AWM, that is tested and verified during exploration, to improve sample efficiency in embodied RL agents. Our DECKARD agent applies LLM-guided exploration to item crafting in Minecraft in two phases: (1) the Dream phase where the agent uses an LLM to decompose a task into a sequence of subgoals, the hypothesized AWM; and (2) the Wake phase where the agent learns a modular policy for each subgoal and verifies or corrects the hypothesized AWM on the basis of its experiences. Our method of hypothesizing an AWM with LLMs and then verifying the AWM based on agent experience not only increases sample efficiency over contemporary methods by an order of magnitude but is also robust to and corrects errors in the LLM, successfully blending noisy internet-scale information from LLMs with knowledge grounded in environment dynamics.
To Adapt or to Annotate: Challenges and Interventions for Domain Adaptation in Open-Domain Question Answering
Dec 20, 2022Recent advances in open-domain question answering (ODQA) have demonstrated impressive accuracy on standard Wikipedia style benchmarks. However, it is less clear how robust these models are and how well they perform when applied to real-world applications in drastically different domains. While there has been some work investigating how well ODQA models perform when tested for out-of-domain (OOD) generalization, these studies have been conducted only under conservative shifts in data distribution and typically focus on a single component (ie. retrieval) rather than an end-to-end system. In response, we propose a more realistic and challenging domain shift evaluation setting and, through extensive experiments, study end-to-end model performance. We find that not only do models fail to generalize, but high retrieval scores often still yield poor answer prediction accuracy. We then categorize different types of shifts and propose techniques that, when presented with a new dataset, predict if intervention methods are likely to be successful. Finally, using insights from this analysis, we propose and evaluate several intervention methods which improve end-to-end answer F1 score by up to 24 points.
Successive Prompting for Decomposing Complex Questions
Dec 08, 2022Answering complex questions that require making latent decisions is a challenging task, especially when limited supervision is available. Recent works leverage the capabilities of large language models (LMs) to perform complex question answering in a few-shot setting by demonstrating how to output intermediate rationalizations while solving the complex question in a single pass. We introduce ``Successive Prompting'', where we iteratively break down a complex task into a simple task, solve it, and then repeat the process until we get the final solution. Successive prompting decouples the supervision for decomposing complex questions from the supervision for answering simple questions, allowing us to (1) have multiple opportunities to query in-context examples at each reasoning step (2) learn question decomposition separately from question answering, including using synthetic data, and (3) use bespoke (fine-tuned) components for reasoning steps where a large LM does not perform well. The intermediate supervision is typically manually written, which can be expensive to collect. We introduce a way to generate a synthetic dataset which can be used to bootstrap a model's ability to decompose and answer intermediate questions. Our best model (with successive prompting) achieves an improvement of ~5% absolute F1 on a few-shot version of the DROP dataset when compared with a state-of-the-art model with the same supervision.
Continued Pretraining for Better Zero- and Few-Shot Promptability
Oct 19, 2022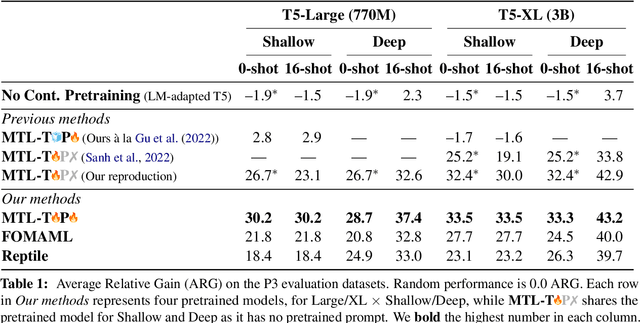
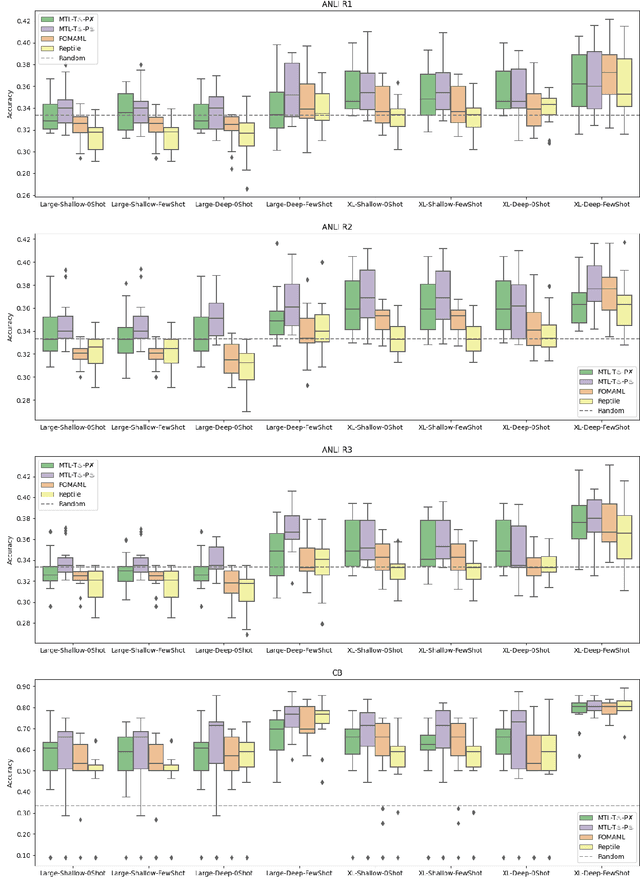
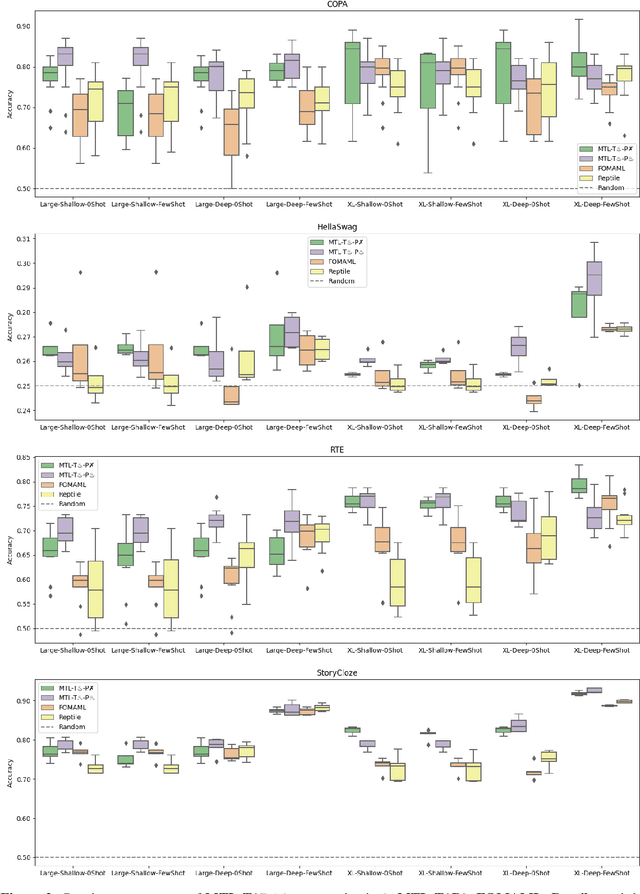
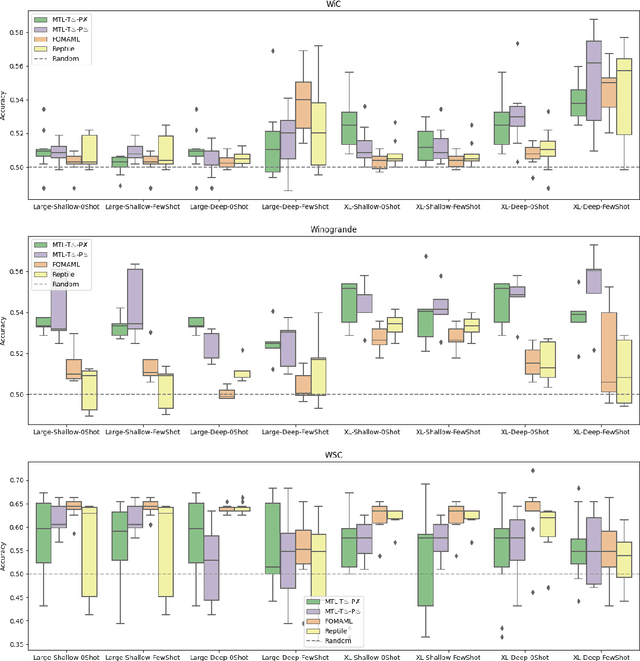
Recently introduced language model prompting methods can achieve high accuracy in zero- and few-shot settings while requiring few to no learned task-specific parameters. Nevertheless, these methods still often trail behind full model finetuning. In this work, we investigate if a dedicated continued pretraining stage could improve "promptability", i.e., zero-shot performance with natural language prompts or few-shot performance with prompt tuning. We reveal settings where existing continued pretraining methods lack promptability. We also identify current methodological gaps, which we fill with thorough large-scale experiments. We demonstrate that a simple recipe, continued pretraining that incorporates a trainable prompt during multi-task learning, leads to improved promptability in both zero- and few-shot settings compared to existing methods, up to 31% relative. On the other hand, we find that continued pretraining using MAML-style meta-learning, a method that directly optimizes few-shot promptability, yields subpar performance. We validate our findings with two prompt tuning methods, and, based on our results, we provide concrete recommendations to optimize promptability for different use cases.