 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-Context Learning Enhanced Credibility Transformer
Sep 09, 2025The starting point of our network architecture is the Credibility Transformer which extends the classical Transformer architecture by a credibility mechanism to improve model learning and predictive performance. This Credibility Transformer learns credibilitized CLS tokens that serve as learned representations of the original input features. In this paper we present a new paradigm that augments this architecture by an in-context learning mechanism, i.e., we increase the information set by a context batch consisting of similar instances. This allows the model to enhance the CLS token representations of the instances by additional in-context information and fine-tuning. We empirically verify that this in-context learning enhances predictive accuracy by adapting to similar risk patterns. Moreover, this in-context learning also allows the model to generalize to new instances which, e.g., have feature levels in the categorical covariates that have not been present when the model was trained -- for a relevant example, think of a new vehicle model which has just been developed by a car manufacturer.
The Credibility Transformer
Sep 25, 2024



Inspired by the large success of Transformers in Large Language Models, these architectures are increasingly applied to tabular data. This is achieved by embedding tabular data into low-dimensional Euclidean spaces resulting in similar structures as time-series data. We introduce a novel credibility mechanism to this Transformer architecture. This credibility mechanism is based on a special token that should be seen as an encoder that consists of a credibility weighted average of prior information and observation based information. We demonstrate that this novel credibility mechanism is very beneficial to stabilize training, and our Credibility Transformer leads to predictive models that are superior to state-of-the-art deep learning models.
Multiple Yield Curve Modeling and Forecasting using Deep Learning
Jan 30, 2024This manuscript introduces deep learning models that simultaneously describe the dynamics of several yield curves. We aim to learn the dependence structure among the different yield curves induced by the globalization of financial markets and exploit it to produce more accurate forecasts. By combining the self-attention mechanism and nonparametric quantile regression, our model generates both point and interval forecasts of future yields. The architecture is designed to avoid quantile crossing issues affecting multiple quantile regression models. Numerical experiments conducted on two different datasets confirm the effectiveness of our approach. Finally, we explore potential extensions and enhancements by incorporating deep ensemble methods and transfer learning mechanisms.
Calibrating the Lee-Carter and the Poisson Lee-Carter models via Neural Networks
Jun 24, 2021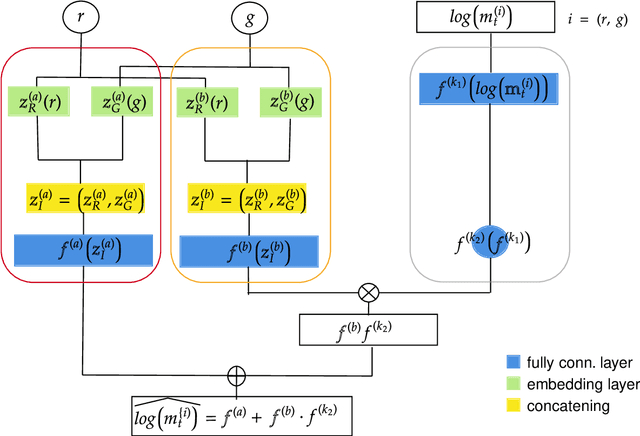
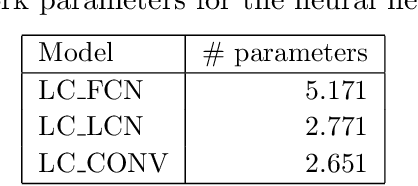
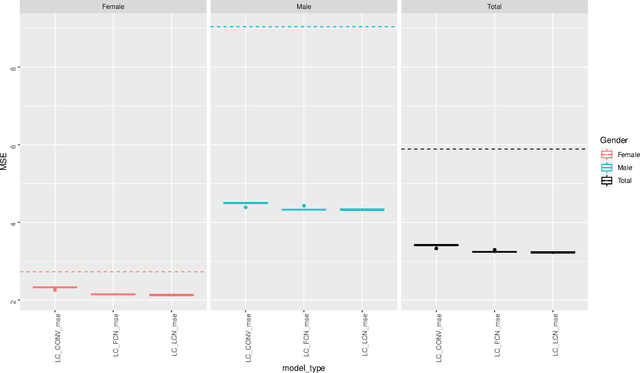
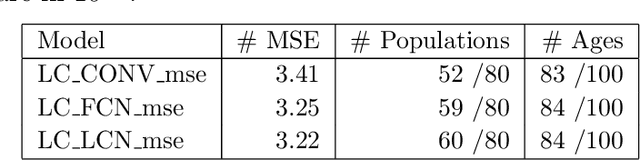
This paper introduces a neural network approach for fitting the Lee-Carter and the Poisson Lee-Carter model on multiple populations. We develop some neural networks that replicate the structure of the individual LC models and allow their joint fitting by analysing the mortality data of all the considered populations simultaneously. The neural network architecture is specifically designed to calibrate each individual model using all available information instead of using a population-specific subset of data as in the traditional estimation schemes. A large set of numerical experiments performed on all the countries of the Human Mortality Database (HMD) shows the effectiveness of our approach. In particular, the resulting parameter estimates appear smooth and less sensitive to the random fluctuations often present in the mortality rates' data, especially for low-population countries. In addition, the forecasting performance results significantly improved as well.
Robust Classification via Support Vector Machines
Apr 27, 2021
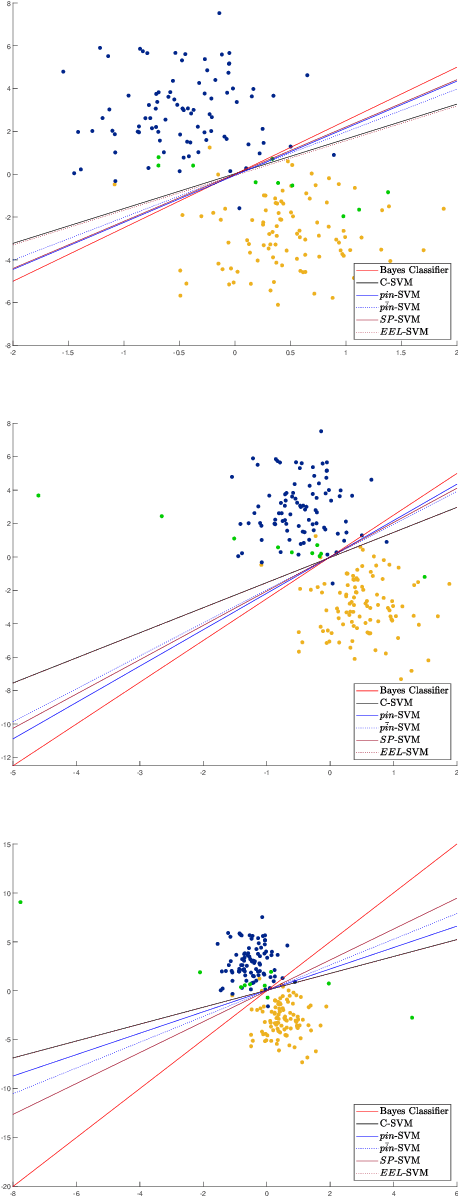
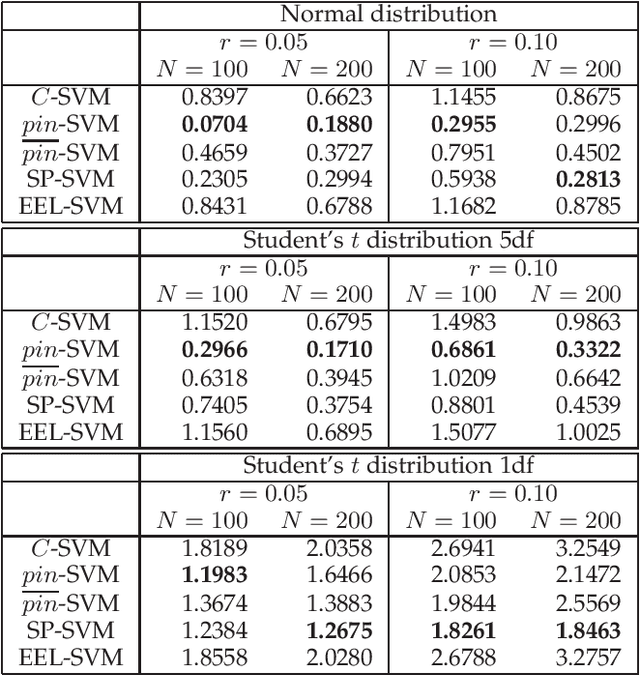
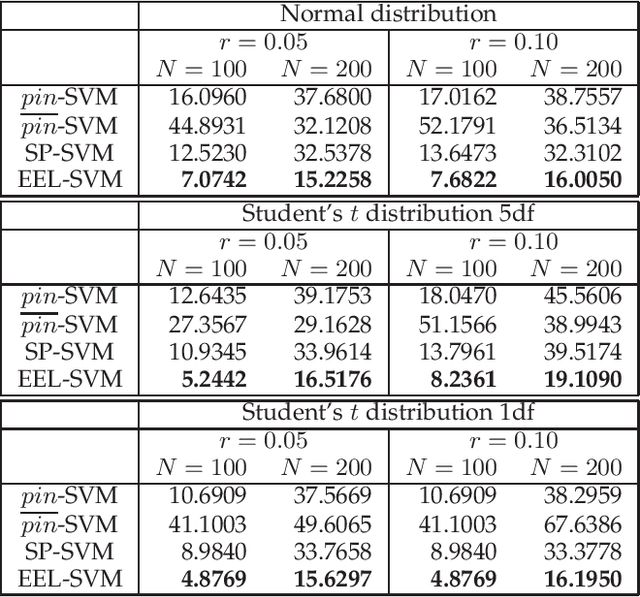
The loss function choice for any Support Vector Machine classifier has raised great interest in the literature due to the lack of robustness of the Hinge loss, which is the standard loss choice. In this paper, we plan to robustify the binary classifier by maintaining the overall advantages of the Hinge loss, rather than modifying this standard choice. We propose two robust classifiers under data uncertainty. The first is called Single Perturbation SVM (SP-SVM) and provides a constructive method by allowing a controlled perturbation to one feature of the data. The second method is called Extreme Empirical Loss SVM (EEL-SVM) and is based on a new empirical loss estimate, namely, the Extreme Empirical Loss (EEL), that puts more emphasis on extreme violations of the classification hyper-plane, rather than taking the usual sample average with equal importance for all hyper-plane violations. Extensive numerical investigation reveals the advantages of the two robust classifiers on simulated data and well-known real datasets.