 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStaying with the Uncertainty: Uncertainty-Scaffolding Strategies for Artificial Moral Advisors in LLM-to-LLM Simulated Conversations
Jun 04, 2026LLMs are increasingly deployed as Artificial Moral Advisors (AMA) in a variety of contexts: what kind of conversational patterns should they display? In this paper, we study how AMA can help their interlocutors "stay with the uncertainty". We propose three modes of uncertainty (Perspective-Multiplying, Tension-Preserving, Process-Reflecting) and compare them against three control conditions (Baseline, Persuasive, Sycophantic). A user-agent LLM engages in a dialogue on an ethical dilemma with an AMA following a specific uncertainty strategy, and completes pre- and post-conversation questionnaires. We further examine the effect of two persona prompt formats (Declarative and Narrative). We found that (1) no single model dominates as a simulated user agent, with open models aligning with human ambiguity through between-persona divergence and closed models through within-persona hedging; (2) declarative personas better capture initial stance diversity while narrative personas show more realistic belief revision; (3) all six AMA strategies produce distinguishable conversational patterns; and (4) uncertainty strategies differ not in how much stance revision they produce, but in the quality of engagement they sustain.
PREF-XAI: Preference-Based Personalized Rule Explanations of Black-Box Machine Learning Models
Apr 21, 2026Explainable artificial intelligence (XAI) has predominantly focused on generating model-centric explanations that approximate the behavior of black-box models. However, such explanations often overlook a fundamental aspect of interpretability: different users require different explanations depending on their goals, preferences, and cognitive constraints. Although recent work has explored user-centric and personalized explanations, most existing approaches rely on heuristic adaptations or implicit user modeling, lacking a principled framework for representing and learning individual preferences. In this paper, we consider Preference-Based Explainable Artificial Intelligence (PREF-XAI), a novel perspective that reframes explanation as a preference-driven decision problem. Within PREF-XAI, explanations are not treated as fixed outputs, but as alternatives to be evaluated and selected according to user-specific criteria. In the PREF-XAI perspective, here we propose a methodology that combines rule-based explanations with formal preference learning. User preferences are elicited through a ranking of a small set of candidate explanations and modeled via an additive utility function inferred using robust ordinal regression. Experimental results on real-world datasets show that PREF-XAI can accurately reconstruct user preferences from limited feedback, identify highly relevant explanations, and discover novel explanatory rules not initially considered by the user. Beyond the proposed methodology, this work establishes a connection between XAI and preference learning, opening new directions for interactive and adaptive explanation systems.
An Explainable and Interpretable Composite Indicator Based on Decision Rules
Jun 16, 2025Composite indicators are widely used to score or classify units evaluated on multiple criteria. Their construction involves aggregating criteria evaluations, a common practice in Multiple Criteria Decision Aiding (MCDA). In MCDA, various methods have been proposed to address key aspects of multiple criteria evaluations, such as the measurement scales of the criteria, the degree of acceptable compensation between them, and their potential interactions. However, beyond producing a final score or classification, it is essential to ensure the explainability and interpretability of results as well as the procedure's transparency. This paper proposes a method for constructing explainable and interpretable composite indicators using "if..., then..." decision rules. We consider the explainability and interpretability of composite indicators in four scenarios: (i) decision rules explain numerical scores obtained from an aggregation of numerical codes corresponding to ordinal qualifiers; (ii) an obscure numerical composite indicator classifies units into quantiles; (iii) given preference information provided by a Decision Maker in the form of classifications of some reference units, a composite indicator is constructed using decision rules; (iv) the classification of a set of units results from the application of an MCDA method and is explained by decision rules. To induce the rules from scored or classified units, we apply the Dominance-based Rough Set Approach. The resulting decision rules relate the class assignment or unit's score to threshold conditions on values of selected indicators in an intelligible way, clarifying the underlying rationale. Moreover, they serve to recommend composite indicator assessment for new units of interest.
NLPGuard: A Framework for Mitigating the Use of Protected Attributes by NLP Classifiers
Jul 01, 2024



AI regulations are expected to prohibit machine learning models from using sensitive attributes during training. However, the latest Natural Language Processing (NLP) classifiers, which rely on deep learning, operate as black-box systems, complicating the detection and remediation of such misuse. Traditional bias mitigation methods in NLP aim for comparable performance across different groups based on attributes like gender or race but fail to address the underlying issue of reliance on protected attributes. To partly fix that, we introduce NLPGuard, a framework for mitigating the reliance on protected attributes in NLP classifiers. NLPGuard takes an unlabeled dataset, an existing NLP classifier, and its training data as input, producing a modified training dataset that significantly reduces dependence on protected attributes without compromising accuracy. NLPGuard is applied to three classification tasks: identifying toxic language, sentiment analysis, and occupation classification. Our evaluation shows that current NLP classifiers heavily depend on protected attributes, with up to $23\%$ of the most predictive words associated with these attributes. However, NLPGuard effectively reduces this reliance by up to $79\%$, while slightly improving accuracy.
Unsupervised Concept Drift Detection from Deep Learning Representations in Real-time
Jun 24, 2024



Concept Drift is a phenomenon in which the underlying data distribution and statistical properties of a target domain change over time, leading to a degradation of the model's performance. Consequently, models deployed in production require continuous monitoring through drift detection techniques. Most drift detection methods to date are supervised, i.e., based on ground-truth labels. However, true labels are usually not available in many real-world scenarios. Although recent efforts have been made to develop unsupervised methods, they often lack the required accuracy, have a complexity that makes real-time implementation in production environments difficult, or are unable to effectively characterize drift. To address these challenges, we propose DriftLens, an unsupervised real-time concept drift detection framework. It works on unstructured data by exploiting the distribution distances of deep learning representations. DriftLens can also provide drift characterization by analyzing each label separately. A comprehensive experimental evaluation is presented with multiple deep learning classifiers for text, image, and speech. Results show that (i) DriftLens performs better than previous methods in detecting drift in $11/13$ use cases; (ii) it runs at least 5 times faster; (iii) its detected drift value is very coherent with the amount of drift (correlation $\geq 0.85$); (iv) it is robust to parameter changes.
Representation of preferences for multiple criteria decision aiding in a new seven-valued logic
May 31, 2024The seven-valued logic considered in this paper naturally arises within the rough set framework, allowing to distinguish vagueness due to imprecision from ambiguity due to coarseness. Recently, we discussed its utility for reasoning about data describing multi-attribute classification of objects. We also showed that this logic contains, as a particular case, the celebrated Belnap four-valued logic. Here, we present how the seven-valued logic, as well as the other logics that derive from it, can be used to represent preferences in the domain of Multiple Criteria Decision Aiding (MCDA). In particular, we propose new forms of outranking and value function preference models that aggregate multiple criteria taking into account imperfect preference information. We demonstrate that our approach effectively addresses common challenges in preference modeling for MCDA, such as uncertainty, imprecision, and ill-determination of performances and preferences. To this end, we present a specific procedure to construct a seven-valued preference relation and use it to define recommendations that consider robustness concerns by utilizing multiple outranking or value functions representing the decision maker s preferences. Moreover, we discuss the main properties of the proposed seven-valued preference structure and compare it with current approaches in MCDA, such as ordinal regression, robust ordinal regression, stochastic multiattribute acceptability analysis, stochastic ordinal regression, and so on. We illustrate and discuss the application of our approach using a didactic example. Finally, we propose directions for future research and potential applications of the proposed methodology.
FRRI: a novel algorithm for fuzzy-rough rule induction
Mar 07, 2024Interpretability is the next frontier in machine learning research. In the search for white box models - as opposed to black box models, like random forests or neural networks - rule induction algorithms are a logical and promising option, since the rules can easily be understood by humans. Fuzzy and rough set theory have been successfully applied to this archetype, almost always separately. As both approaches to rule induction involve granular computing based on the concept of equivalence classes, it is natural to combine them. The QuickRules\cite{JensenCornelis2009} algorithm was a first attempt at using fuzzy rough set theory for rule induction. It is based on QuickReduct, a greedy algorithm for building decision reducts. QuickRules already showed an improvement over other rule induction methods. However, to evaluate the full potential of a fuzzy rough rule induction algorithm, one needs to start from the foundations. In this paper, we introduce a novel rule induction algorithm called Fuzzy Rough Rule Induction (FRRI). We provide background and explain the workings of our algorithm. Furthermore, we perform a computational experiment to evaluate the performance of our algorithm and compare it to other state-of-the-art rule induction approaches. We find that our algorithm is more accurate while creating small rulesets consisting of relatively short rules. We end the paper by outlining some directions for future work.
Dominance-based Rough Set Approach, basic ideas and main trends
Oct 06, 2022Dominance-based Rough Approach (DRSA) has been proposed as a machine learning and knowledge discovery methodology to handle Multiple Criteria Decision Aiding (MCDA). Due to its capacity of asking the decision maker (DM) for simple preference information and supplying easily understandable and explainable recommendations, DRSA gained much interest during the years and it is now one of the most appreciated MCDA approaches. In fact, it has been applied also beyond MCDA domain, as a general knowledge discovery and data mining methodology for the analysis of monotonic (and also non-monotonic) data. In this contribution, we recall the basic principles and the main concepts of DRSA, with a general overview of its developments and software. We present also a historical reconstruction of the genesis of the methodology, with a specific focus on the contribution of Roman S{\l}owi\'nski.
* This research was partially supported by TAILOR, a project funded by European Union (EU) Horizon 2020 research and innovation programme under GA No 952215. This submission is a preprint of a book chapter accepted by Springer, with very few minor differences of just technical nature
Fuzzy granular approximation classifier
Jun 02, 2022
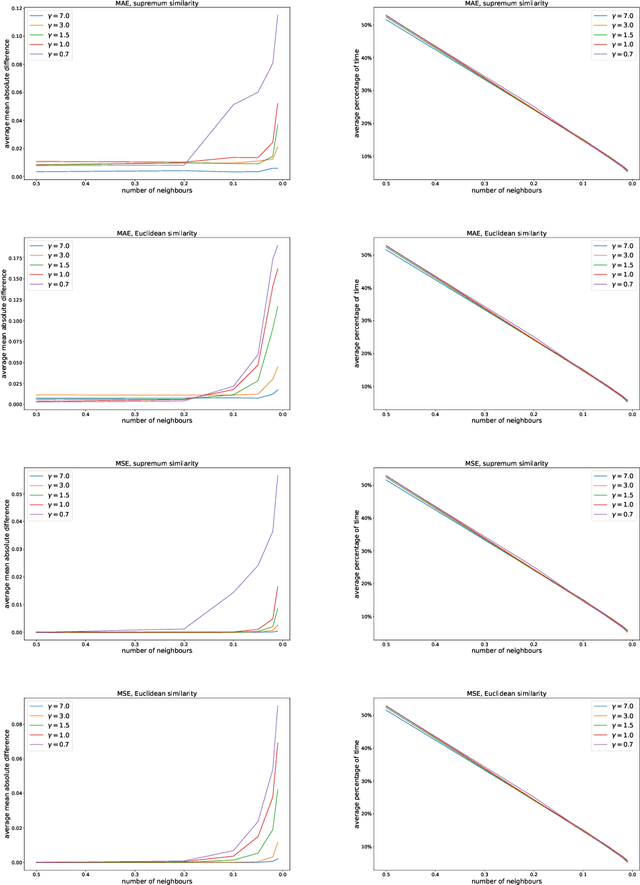
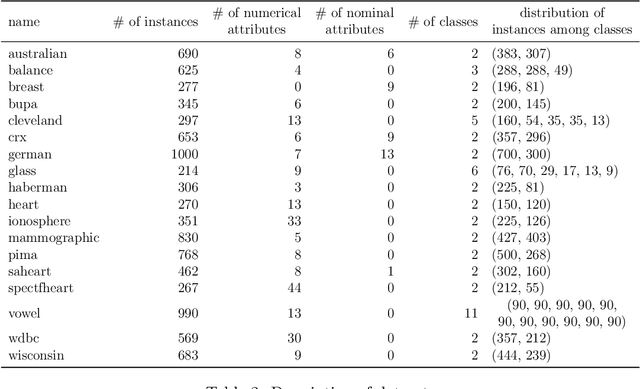
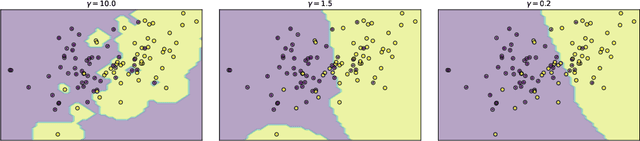
In this article, a new Fuzzy Granular Approximation Classifier (FGAC) is introduced. The classifier is based on the previously introduced concept of the granular approximation and its multi-class classification case. The classifier is instance-based and its biggest advantage is its local transparency i.e., the ability to explain every individual prediction it makes. We first develop the FGAC for the binary classification case and the multi-class classification case and we discuss its variation that includes the Ordered Weighted Average (OWA) operators. Those variations of the FGAC are then empirically compared with other locally transparent ML methods. At the end, we discuss the transparency of the FGAC and its advantage over other locally transparent methods. We conclude that while the FGAC has similar predictive performance to other locally transparent ML models, its transparency can be superior in certain cases.
Multi-class granular approximation by means of disjoint and adjacent fuzzy granules
Feb 15, 2022
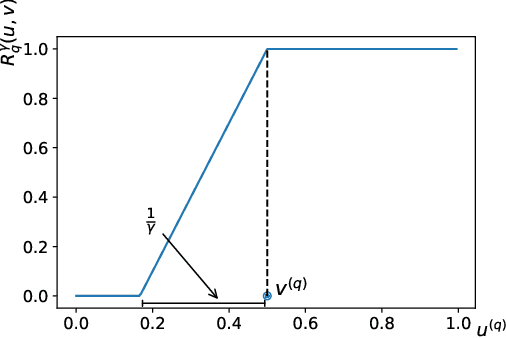
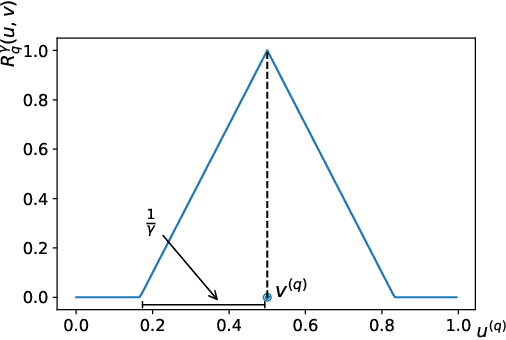
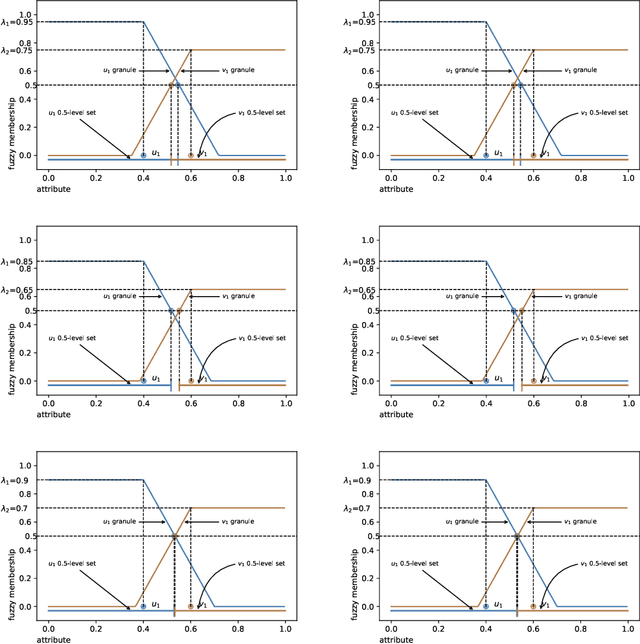
In granular computing, fuzzy sets can be approximated by granularly representable sets that are as close as possible to the original fuzzy set w.r.t. a given closeness measure. Such sets are called granular approximations. In this article, we introduce the concepts of disjoint and adjacent granules and we examine how the new definitions affect the granular approximations. First, we show that the new concepts are important for binary classification problems since they help to keep decision regions separated (disjoint granules) and at the same time to cover as much as possible of the attribute space (adjacent granules). Later, we consider granular approximations for multi-class classification problems leading to the definition of a multi-class granular approximation. Finally, we show how to efficiently calculate multi-class granular approximations for {\L}ukasiewicz fuzzy connectives. We also provide graphical illustrations for a better understanding of the introduced concepts.