 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNCCL EP: Towards a Unified Expert Parallel Communication API for NCCL
Mar 13, 2026Mixture-of-Experts (MoE) architectures have become essential for scaling large language models, driving the development of specialized device-initiated communication libraries such as DeepEP, Hybrid-EP, and others. These libraries demonstrate the performance benefits of GPU-initiated RDMA for MoE dispatch and combine operations. This paper presents NCCL EP (Expert Parallelism), a ground-up MoE communication library built entirely on NCCL's Device API. NCCL EP provides unified ncclEpDispatch and ncclEpCombine primitives with both C and Python interfaces, supporting Low-Latency (LL) mode for inference decoding and High-Throughput (HT) mode for training and inference prefill. LL targets small batch sizes (1-128 tokens) using direct all-to-all RDMA+NVLink mesh connectivity with double-buffered communication for overlapping dispatch and combine phases. HT targets large batches (4096+ tokens) using hierarchical communication that aggregates tokens within NVLink domains before inter-node RDMA transmission. Both modes leverage Device API for both intra- and inter-node communications, taking advantage of its topology awareness and optimized GPU-initiated implementation. We evaluate NCCL EP on an H100-based cluster across multi-node configurations, demonstrating competitive LL kernel performance and presenting end-to-end results with vLLM integration. By building MoE communication natively within NCCL, NCCL EP provides a supported path for expert parallelism on current and emerging NVIDIA platforms.
O(1) Communication for Distributed SGD through Two-Level Gradient Averaging
Jun 16, 2020
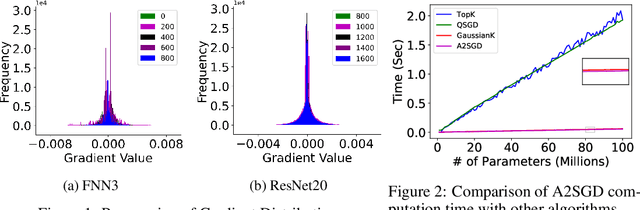

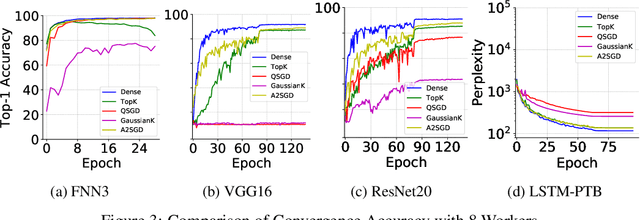
Large neural network models present a hefty communication challenge to distributed Stochastic Gradient Descent (SGD), with a communication complexity of O(n) per worker for a model of n parameters. Many sparsification and quantization techniques have been proposed to compress the gradients, some reducing the communication complexity to O(k), where k << n. In this paper, we introduce a strategy called two-level gradient averaging (A2SGD) to consolidate all gradients down to merely two local averages per worker before the computation of two global averages for an updated model. A2SGD also retains local errors to maintain the variance for fast convergence. Our theoretical analysis shows that A2SGD converges similarly like the default distributed SGD algorithm. Our evaluation validates the theoretical conclusion and demonstrates that A2SGD significantly reduces the communication traffic per worker, and improves the overall training time of LSTM-PTB by 3.2x and 23.2x, respectively, compared to Top-K and QSGD. To the best of our knowledge, A2SGD is the first to achieve O(1) communication complexity per worker for distributed SGD.