 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable Vulnerability Detection in C/C++ Using Edge-Aware Graph Attention Networks
Jul 22, 2025Detecting security vulnerabilities in source code remains challenging, particularly due to class imbalance in real-world datasets where vulnerable functions are under-represented. Existing learning-based methods often optimise for recall, leading to high false positive rates and reduced usability in development workflows. Furthermore, many approaches lack explainability, limiting their integration into security workflows. This paper presents ExplainVulD, a graph-based framework for vulnerability detection in C/C++ code. The method constructs Code Property Graphs and represents nodes using dual-channel embeddings that capture both semantic and structural information. These are processed by an edge-aware attention mechanism that incorporates edge-type embeddings to distinguish among program relations. To address class imbalance, the model is trained using class-weighted cross-entropy loss. ExplainVulD achieves a mean accuracy of 88.25 percent and an F1 score of 48.23 percent across 30 independent runs on the ReVeal dataset. These results represent relative improvements of 4.6 percent in accuracy and 16.9 percent in F1 score compared to the ReVeal model, a prior learning-based method. The framework also outperforms static analysis tools, with relative gains of 14.0 to 14.1 percent in accuracy and 132.2 to 201.2 percent in F1 score. Beyond improved detection performance, ExplainVulD produces explainable outputs by identifying the most influential code regions within each function, supporting transparency and trust in security triage.
Estimating the number of household TV profiles based in customer behaviour using Gaussian mixture model averaging
May 15, 2025TV customers today face many choices from many live channels and on-demand services. Providing a personalised experience that saves customers time when discovering content is essential for TV providers. However, a reliable understanding of their behaviour and preferences is key. When creating personalised recommendations for TV, the biggest challenge is understanding viewing behaviour within households when multiple people are watching. The objective is to detect and combine individual profiles to make better-personalised recommendations for group viewing. Our challenge is that we have little explicit information about who is watching the devices at any time (individuals or groups). Also, we do not have a way to combine more than one individual profile to make better recommendations for group viewing. We propose a novel framework using a Gaussian mixture model averaging to obtain point estimates for the number of household TV profiles and a Bayesian random walk model to introduce uncertainty. We applied our approach using data from real customers whose TV-watching data totalled approximately half a million observations. Our results indicate that combining our framework with the selected features provides a means to estimate the number of household TV profiles and their characteristics, including shifts over time and quantification of uncertainty.
Profiling Television Watching Behaviour Using Bayesian Hierarchical Joint Models for Time-to-Event and Count Data
Sep 06, 2022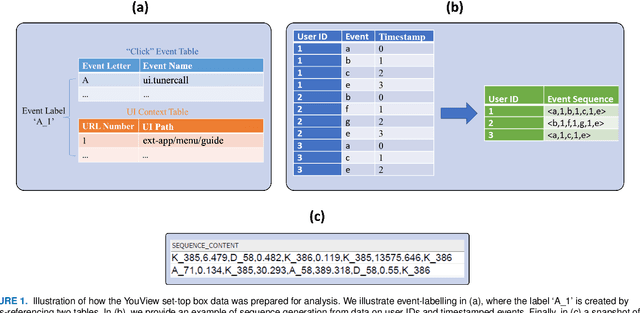
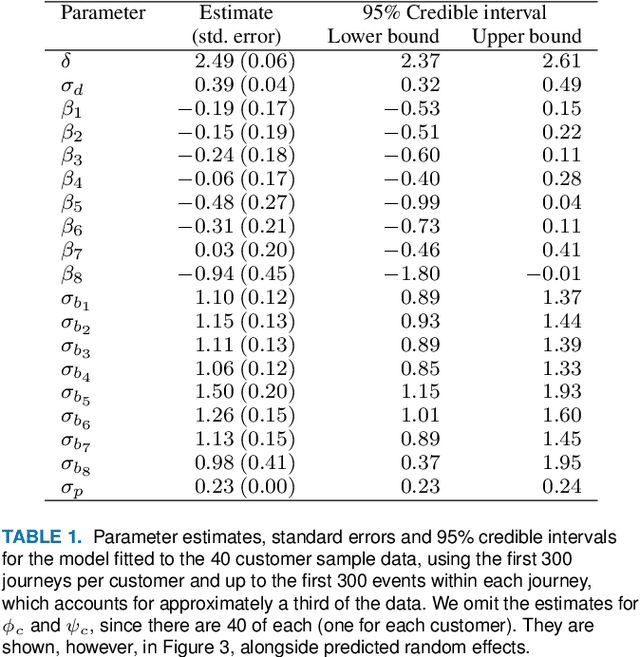

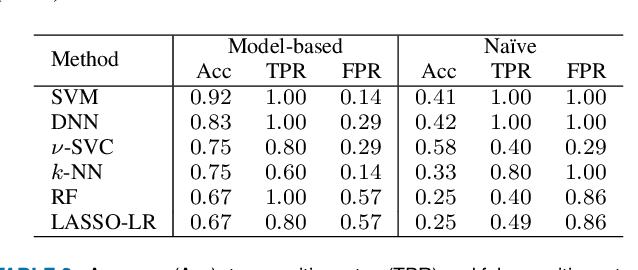
Customer churn prediction is a valuable task in many industries. In telecommunications it presents great challenges, given the high dimensionality of the data, and how difficult it is to identify underlying frustration signatures, which may represent an important driver regarding future churn behaviour. Here, we propose a novel Bayesian hierarchical joint model that is able to characterise customer profiles based on how many events take place within different television watching journeys, and how long it takes between events. The model drastically reduces the dimensionality of the data from thousands of observations per customer to 11 customer-level parameter estimates and random effects. We test our methodology using data from 40 BT customers (20 active and 20 who eventually cancelled their subscription) whose TV watching behaviours were recorded from October to December 2019, totalling approximately half a million observations. Employing different machine learning techniques using the parameter estimates and random effects from the Bayesian hierarchical model as features yielded up to 92\% accuracy predicting churn, associated with 100\% true positive rates and false positive rates as low as 14\% on a validation set. Our proposed methodology represents an efficient way of reducing the dimensionality of the data, while at the same time maintaining high descriptive and predictive capabilities. We provide code to implement the Bayesian model at https://github.com/rafamoral/profiling_tv_watching_behaviour.
Gated Task Interaction Framework for Multi-task Sequence Tagging
Sep 29, 2019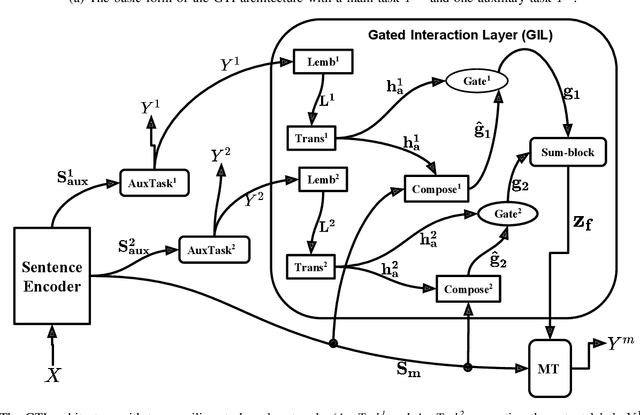

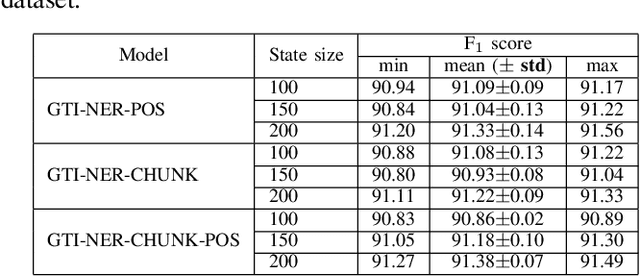
Recent studies have shown that neural models can achieve high performance on several sequence labelling/tagging problems without the explicit use of linguistic features such as part-of-speech (POS) tags. These models are trained only using the character-level and the word embedding vectors as inputs. Others have shown that linguistic features can improve the performance of neural models on tasks such as chunking and named entity recognition (NER). However, the change in performance depends on the degree of semantic relatedness between the linguistic features and the target task; in some instances, linguistic features can have a negative impact on performance. This paper presents an approach to jointly learn these linguistic features along with the target sequence labelling tasks with a new multi-task learning (MTL) framework called Gated Tasks Interaction (GTI) network for solving multiple sequence tagging tasks. The GTI network exploits the relations between the multiple tasks via neural gate modules. These gate modules control the flow of information between the different tasks. Experiments on benchmark datasets for chunking and NER show that our framework outperforms other competitive baselines trained with and without external training resources.
* 8 pages
Quantifying consensus of rankings based on q-support patterns
May 30, 2019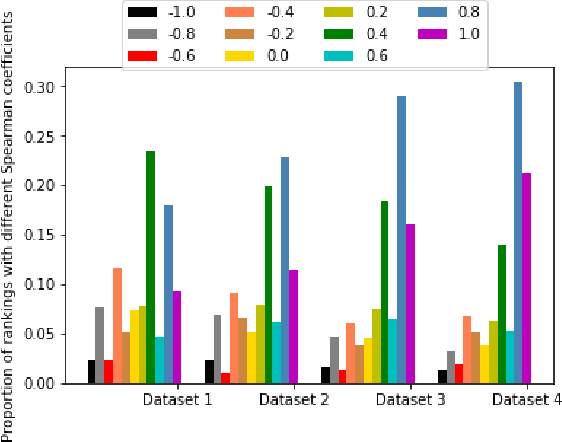
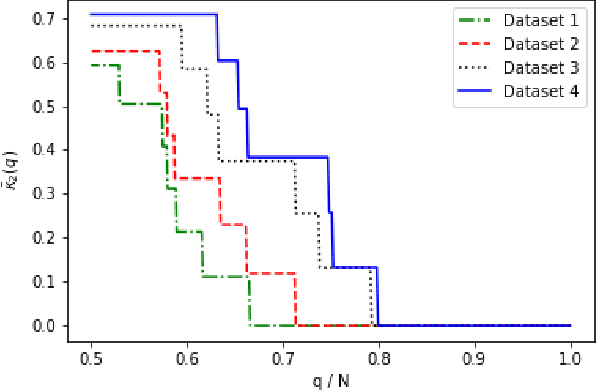
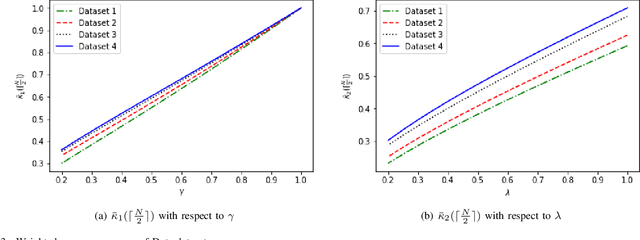
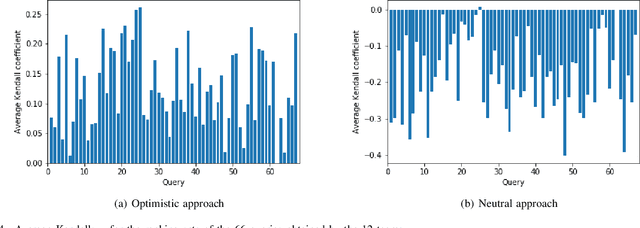
Rankings, representing preferences over a set of candidates, are widely used in many information systems, e.g., group decision making. It is of great importance to evaluate the consensus of the obtained rankings from multiple agents. There is often no ground truth available for a ranking task. An overall measure of the consensus degree enables us to have a clear cognition about the ranking data. Moreover, it could provide a quantitative indicator for consensus comparison between groups and further improvement of a ranking system. In this paper, a novel consensus quantifying approach, without the need for any correlation or distance functions, is proposed based on a concept of q-support patterns of rankings. The q-support patterns represent the commonality embedded in a set of rankings. A method for detecting outliers in a set of rankings is naturally derived from the proposed consensus quantifying approach. Experimental studies are conducted to demonstrate the effectiveness of the proposed approach.