 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlgorithmic Approaches to Opinion Selection for Online Deliberation: A Comparative Study
Feb 17, 2026During deliberation processes, mediators and facilitators typically need to select a small and representative set of opinions later used to produce digestible reports for stakeholders. In online deliberation platforms, algorithmic selection is increasingly used to automate this process. However, such automation is not without consequences. For instance, enforcing consensus-seeking algorithmic strategies can imply ignoring or flattening conflicting preferences, which may lead to erasing minority voices and reducing content diversity. More generally, across the variety of existing selection strategies (e.g., consensus, diversity), it remains unclear how each approach influences desired democratic criteria such as proportional representation. To address this gap, we benchmark several algorithmic approaches in this context. We also build on social choice theory to propose a novel algorithm that incorporates both diversity and a balanced notion of representation in the selection strategy. We find empirically that while no single strategy dominates across all democratic desiderata, our social-choice-inspired selection rule achieves the strongest trade-off between proportional representation and diversity.
The CLEF-2026 CheckThat! Lab: Advancing Multilingual Fact-Checking
Feb 10, 2026The CheckThat! lab aims to advance the development of innovative technologies combating disinformation and manipulation efforts in online communication across a multitude of languages and platforms. While in early editions the focus has been on core tasks of the verification pipeline (check-worthiness, evidence retrieval, and verification), in the past three editions, the lab added additional tasks linked to the verification process. In this year's edition, the verification pipeline is at the center again with the following tasks: Task 1 on source retrieval for scientific web claims (a follow-up of the 2025 edition), Task 2 on fact-checking numerical and temporal claims, which adds a reasoning component to the 2025 edition, and Task 3, which expands the verification pipeline with generation of full-fact-checking articles. These tasks represent challenging classification and retrieval problems as well as generation challenges at the document and span level, including multilingual settings.
The CLEF-2025 CheckThat! Lab: Subjectivity, Fact-Checking, Claim Normalization, and Retrieval
Mar 19, 2025The CheckThat! lab aims to advance the development of innovative technologies designed to identify and counteract online disinformation and manipulation efforts across various languages and platforms. The first five editions focused on key tasks in the information verification pipeline, including check-worthiness, evidence retrieval and pairing, and verification. Since the 2023 edition, the lab has expanded its scope to address auxiliary tasks that support research and decision-making in verification. In the 2025 edition, the lab revisits core verification tasks while also considering auxiliary challenges. Task 1 focuses on the identification of subjectivity (a follow-up from CheckThat! 2024), Task 2 addresses claim normalization, Task 3 targets fact-checking numerical claims, and Task 4 explores scientific web discourse processing. These tasks present challenging classification and retrieval problems at both the document and span levels, including multilingual settings.
SciTweets -- A Dataset and Annotation Framework for Detecting Scientific Online Discourse
Jun 15, 2022
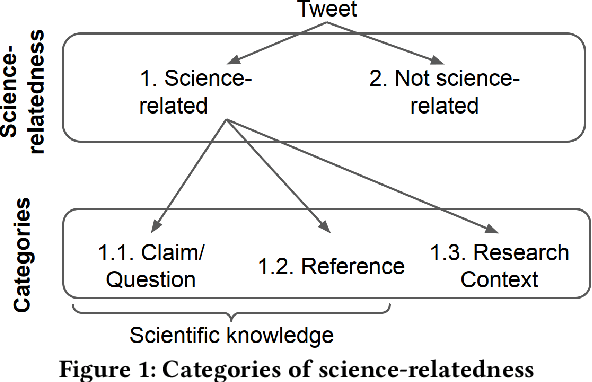
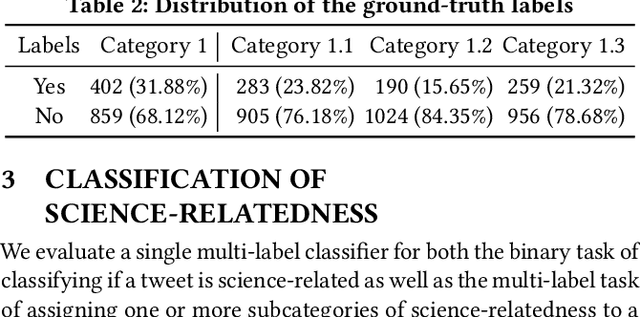
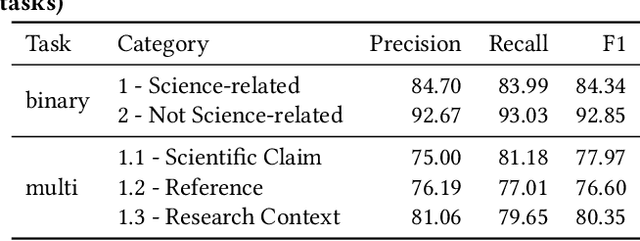
Scientific topics, claims and resources are increasingly debated as part of online discourse, where prominent examples include discourse related to COVID-19 or climate change. This has led to both significant societal impact and increased interest in scientific online discourse from various disciplines. For instance, communication studies aim at a deeper understanding of biases, quality or spreading pattern of scientific information whereas computational methods have been proposed to extract, classify or verify scientific claims using NLP and IR techniques. However, research across disciplines currently suffers from both a lack of robust definitions of the various forms of science-relatedness as well as appropriate ground truth data for distinguishing them. In this work, we contribute (a) an annotation framework and corresponding definitions for different forms of scientific relatedness of online discourse in Tweets, (b) an expert-annotated dataset of 1261 tweets obtained through our labeling framework reaching an average Fleiss Kappa $\kappa$ of 0.63, (c) a multi-label classifier trained on our data able to detect science-relatedness with 89% F1 and also able to detect distinct forms of scientific knowledge (claims, references). With this work we aim to lay the foundation for developing and evaluating robust methods for analysing science as part of large-scale online discourse.