 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRF-HiT: Rectified Flow Hierarchical Transformer for General Medical Image Segmentation
Apr 21, 2026Accurate medical image segmentation requires both long-range contextual reasoning and precise boundary delineation, a task where existing transformer- and diffusion-based paradigms are frequently bottlenecked by quadratic computational complexity and prohibitive inference latency. We propose RF-HiT, a Rectified Flow Hierarchical Transformer that integrates an hourglass transformer backbone with a multi-scale hierarchical encoder for anatomically guided feature conditioning. Unlike prior diffusion-based approaches, RF-HiT leverages rectified flow with efficient transformer blocks to achieve linear complexity while requiring only a few discretization steps. The model further fuses conditioning features across resolutions via learnable interpolation, enabling effective multi-scale representation with minimal computational overhead. As a result, RF-HiT achieves a strong efficiency-performance trade-off, requiring only 10.14 GFLOPs, 13.6M parameters, and inference in as few as three steps. Despite its compact design, RF-HiT attains 91.27% mean Dice on ACDC and 87.40% on BraTS 2021, achieving performance comparable to or exceeding that of significantly more intensive architectures. This demonstrates its strong potential as a robust, computationally efficient foundation for real-time clinical segmentation.
CVPD at QIAS 2026: RAG-Guided LLM Reasoning for Al-Mawarith Share Computation and Heir Allocation
Mar 25, 2026Islamic inheritance (Ilm al-Mawarith) is a multi-stage legal reasoning task requiring the identification of eligible heirs, resolution of blocking rules (hajb), assignment of fixed and residual shares, handling of adjustments such as awl and radd, and generation of a consistent final distribution. The task is further complicated by variations across legal schools and civil-law codifications, requiring models to operate under explicit legal configurations. We present a retrieval-augmented generation (RAG) pipeline for this setting, combining rule-grounded synthetic data generation, hybrid retrieval (dense and BM25) with cross-encoder reranking, and schema-constrained output validation. A symbolic inheritance calculator is used to generate a large high-quality synthetic corpus with full intermediate reasoning traces, ensuring legal and numerical consistency. The proposed system achieves a MIR-E score of 0.935 and ranks first on the official QIAS 2026 blind-test leaderboard. Results demonstrate that retrieval-grounded, schema-aware generation significantly improves reliability in high-precision Arabic legal reasoning tasks.
Conflict-Aware Multimodal Fusion for Ambivalence and Hesitancy Recognition
Mar 16, 2026Ambivalence and hesitancy (A/H) are subtle affective states where a person shows conflicting signals through different channels -- saying one thing while their face or voice tells another story. Recognising these states automatically is valuable in clinical settings, but it is hard for machines because the key evidence lives in the \emph{disagreements} between what is said, how it sounds, and what the face shows. We present \textbf{ConflictAwareAH}, a multimodal framework built for this problem. Three pre-trained encoders extract video, audio, and text representations. Pairwise conflict features -- element-wise absolute differences between modality embeddings -- serve as \emph{bidirectional} cues: large cross-modal differences flag A/H, while small differences confirm behavioural consistency and anchor the negative class. This conflict-aware design addresses a key limitation of text-dominant approaches, which tend to over-detect A/H (high F1-AH) while struggling to confirm its absence: our multimodal model improves F1-NoAH by +4.6 points over text alone and halves the class-performance gap. A complementary \emph{text-guided late fusion} strategy blends a text-only auxiliary head with the full model at inference, adding +4.1 Macro F1. On the BAH dataset from the ABAW10 Ambivalence/Hesitancy Challenge, our method reaches \textbf{0.694 Macro F1} on the labelled test split and \textbf{0.715} on the private leaderboard, outperforming published multimodal baselines by over 10 points -- all on a single GPU in under 25 minutes of training.
VP-Hype: A Hybrid Mamba-Transformer Framework with Visual-Textual Prompting for Hyperspectral Image Classification
Mar 01, 2026Accurate classification of hyperspectral imagery (HSI) is often frustrated by the tension between high-dimensional spectral data and the extreme scarcity of labeled training samples. While hierarchical models like LoLA-SpecViT have demonstrated the power of local windowed attention and parameter-efficient fine-tuning, the quadratic complexity of standard Transformers remains a barrier to scaling. We introduce VP-Hype, a framework that rethinks HSI classification by unifying the linear-time efficiency of State-Space Models (SSMs) with the relational modeling of Transformers in a novel hybrid architecture. Building on a robust 3D-CNN spectral front-end, VP-Hype replaces conventional attention blocks with a Hybrid Mamba-Transformer backbone to capture long-range dependencies with significantly reduced computational overhead. Furthermore, we address the label-scarcity problem by integrating dual-modal Visual and Textual Prompts that provide context-aware guidance for the feature extraction process. Our experimental evaluation demonstrates that VP-Hype establishes a new state of the art in low-data regimes. Specifically, with a training sample distribution of only 2\%, the model achieves Overall Accuracy (OA) of 99.69\% on the Salinas dataset and 99.45\% on the Longkou dataset. These results suggest that the convergence of hybrid sequence modeling and multi-modal prompting provides a robust path forward for high-performance, sample-efficient remote sensing.
VLM-PAR: A Vision Language Model for Pedestrian Attribute Recognition
Dec 22, 2025Pedestrian Attribute Recognition (PAR) involves predicting fine-grained attributes such as clothing color, gender, and accessories from pedestrian imagery, yet is hindered by severe class imbalance, intricate attribute co-dependencies, and domain shifts. We introduce VLM-PAR, a modular vision-language framework built on frozen SigLIP 2 multilingual encoders. By first aligning image and prompt embeddings via refining visual features through a compact cross-attention fusion, VLM-PAR achieves significant accuracy improvement on the highly imbalanced PA100K benchmark, setting a new state-of-the-art performance, while also delivering significant gains in mean accuracy across PETA and Market-1501 benchmarks. These results underscore the efficacy of integrating large-scale vision-language pretraining with targeted cross-modal refinement to overcome imbalance and generalization challenges in PAR.
Facial age estimation using BSIF and LBP
Jan 08, 2016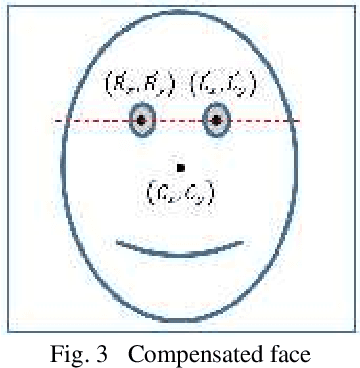
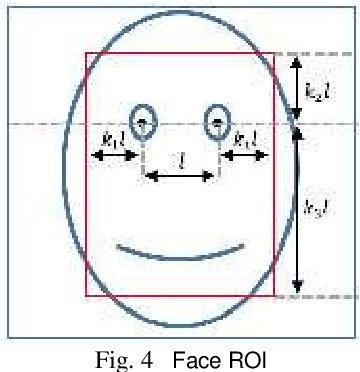
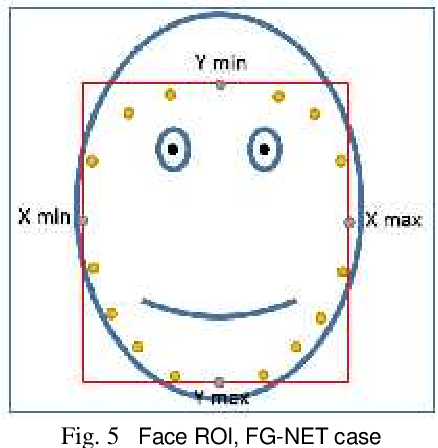
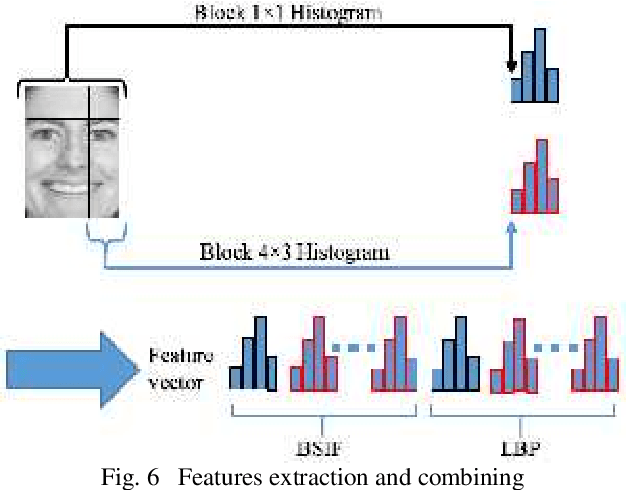
Human face aging is irreversible process causing changes in human face characteristics such us hair whitening, muscles drop and wrinkles. Due to the importance of human face aging in biometrics systems, age estimation became an attractive area for researchers. This paper presents a novel method to estimate the age from face images, using binarized statistical image features (BSIF) and local binary patterns (LBP)histograms as features performed by support vector regression (SVR) and kernel ridge regression (KRR). We applied our method on FG-NET and PAL datasets. Our proposed method has shown superiority to that of the state-of-the-art methods when using the whole PAL database.