 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Effective Node Classifiers for Cascade Classification
Jan 10, 2013

Cascade classifiers are widely used in real-time object detection. Different from conventional classifiers that are designed for a low overall classification error rate, a classifier in each node of the cascade is required to achieve an extremely high detection rate and moderate false positive rate. Although there are a few reported methods addressing this requirement in the context of object detection, there is no principled feature selection method that explicitly takes into account this asymmetric node learning objective. We provide such an algorithm here. We show that a special case of the biased minimax probability machine has the same formulation as the linear asymmetric classifier (LAC) of Wu et al (2005). We then design a new boosting algorithm that directly optimizes the cost function of LAC. The resulting totally-corrective boosting algorithm is implemented by the column generation technique in convex optimization. Experimental results on object detection verify the effectiveness of the proposed boosting algorithm as a node classifier in cascade object detection, and show performance better than that of the current state-of-the-art.
A Direct Approach to Multi-class Boosting and Extensions
Oct 17, 2012

Boosting methods combine a set of moderately accurate weaklearners to form a highly accurate predictor. Despite the practical importance of multi-class boosting, it has received far less attention than its binary counterpart. In this work, we propose a fully-corrective multi-class boosting formulation which directly solves the multi-class problem without dividing it into multiple binary classification problems. In contrast, most previous multi-class boosting algorithms decompose a multi-boost problem into multiple binary boosting problems. By explicitly deriving the Lagrange dual of the primal optimization problem, we are able to construct a column generation-based fully-corrective approach to boosting which directly optimizes multi-class classification performance. The new approach not only updates all weak learners' coefficients at every iteration, but does so in a manner flexible enough to accommodate various loss functions and regularizations. For example, it enables us to introduce structural sparsity through mixed-norm regularization to promote group sparsity and feature sharing. Boosting with shared features is particularly beneficial in complex prediction problems where features can be expensive to compute. Our experiments on various data sets demonstrate that our direct multi-class boosting generalizes as well as, or better than, a range of competing multi-class boosting methods. The end result is a highly effective and compact ensemble classifier which can be trained in a distributed fashion.
Face Detection with Effective Feature Extraction
Sep 29, 2010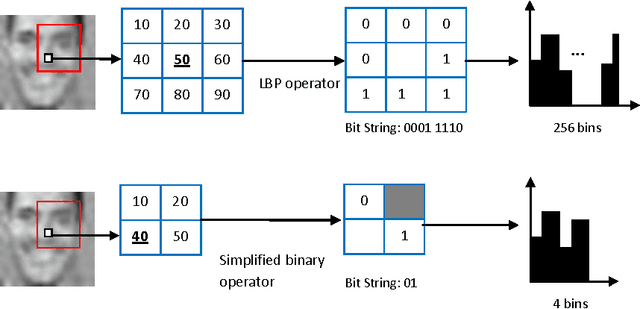
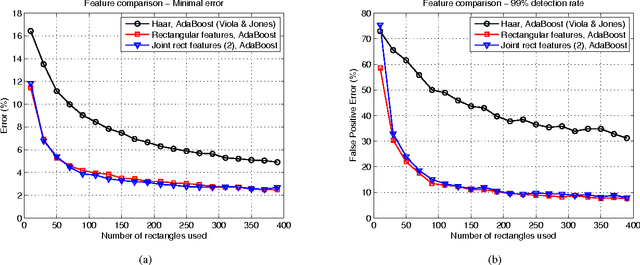
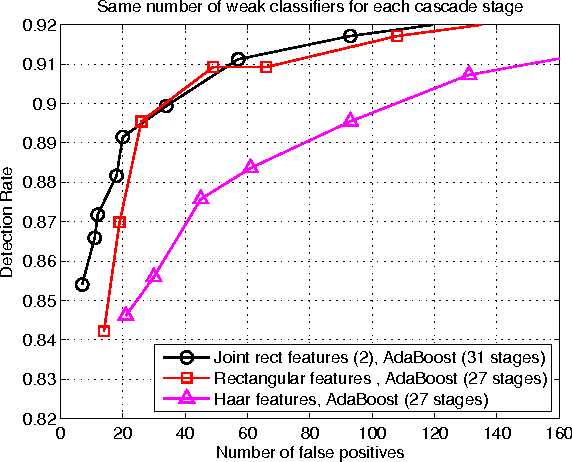

There is an abundant literature on face detection due to its important role in many vision applications. Since Viola and Jones proposed the first real-time AdaBoost based face detector, Haar-like features have been adopted as the method of choice for frontal face detection. In this work, we show that simple features other than Haar-like features can also be applied for training an effective face detector. Since, single feature is not discriminative enough to separate faces from difficult non-faces, we further improve the generalization performance of our simple features by introducing feature co-occurrences. We demonstrate that our proposed features yield a performance improvement compared to Haar-like features. In addition, our findings indicate that features play a crucial role in the ability of the system to generalize.
Incremental Training of a Detector Using Online Sparse Eigen-decomposition
May 22, 2010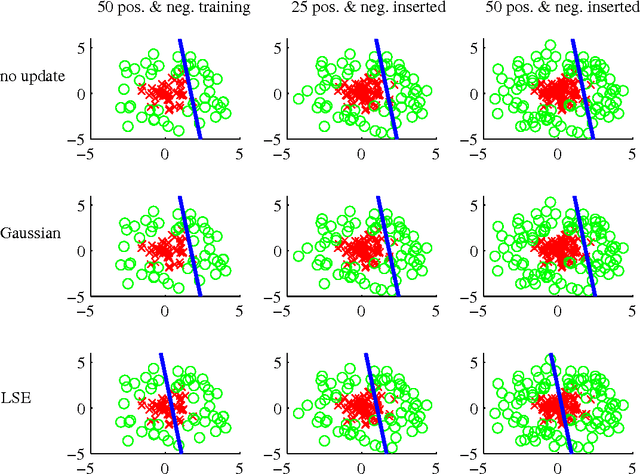
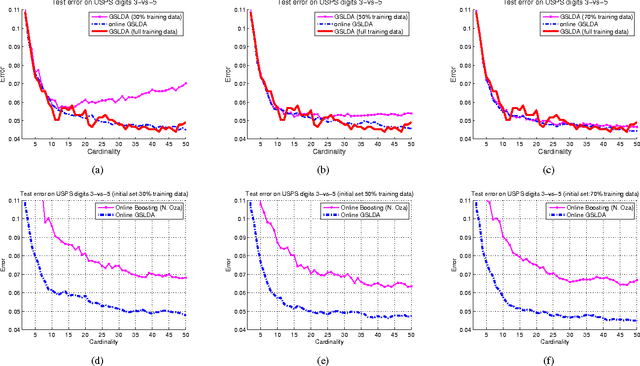
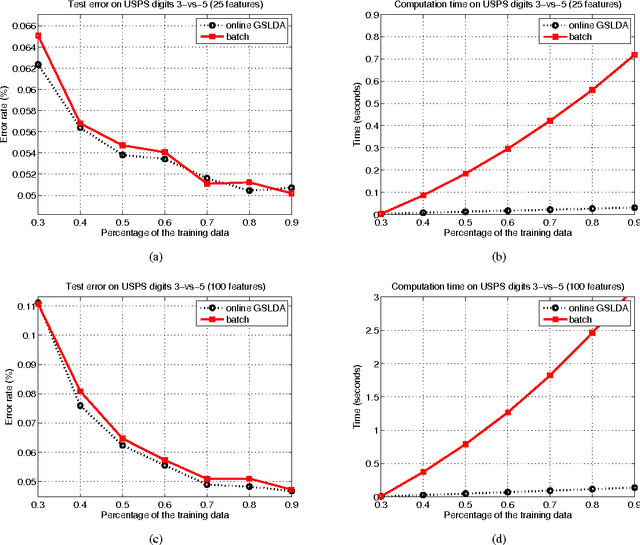

The ability to efficiently and accurately detect objects plays a very crucial role for many computer vision tasks. Recently, offline object detectors have shown a tremendous success. However, one major drawback of offline techniques is that a complete set of training data has to be collected beforehand. In addition, once learned, an offline detector can not make use of newly arriving data. To alleviate these drawbacks, online learning has been adopted with the following objectives: (1) the technique should be computationally and storage efficient; (2) the updated classifier must maintain its high classification accuracy. In this paper, we propose an effective and efficient framework for learning an adaptive online greedy sparse linear discriminant analysis (GSLDA) model. Unlike many existing online boosting detectors, which usually apply exponential or logistic loss, our online algorithm makes use of LDA's learning criterion that not only aims to maximize the class-separation criterion but also incorporates the asymmetrical property of training data distributions. We provide a better alternative for online boosting algorithms in the context of training a visual object detector. We demonstrate the robustness and efficiency of our methods on handwriting digit and face data sets. Our results confirm that object detection tasks benefit significantly when trained in an online manner.
Efficiently Learning a Detection Cascade with Sparse Eigenvectors
Mar 18, 2009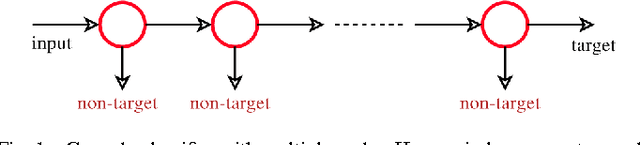
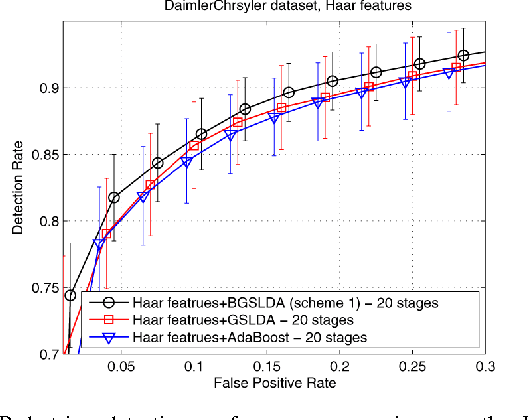
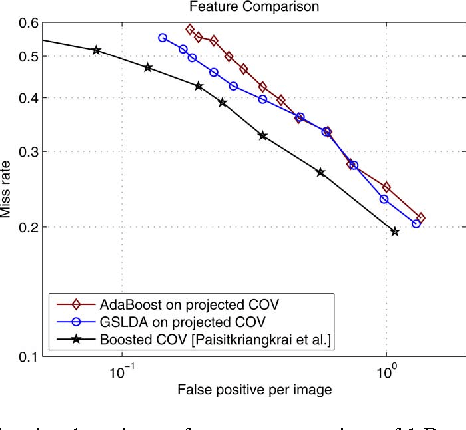

In this work, we first show that feature selection methods other than boosting can also be used for training an efficient object detector. In particular, we introduce Greedy Sparse Linear Discriminant Analysis (GSLDA) \cite{Moghaddam2007Fast} for its conceptual simplicity and computational efficiency; and slightly better detection performance is achieved compared with \cite{Viola2004Robust}. Moreover, we propose a new technique, termed Boosted Greedy Sparse Linear Discriminant Analysis (BGSLDA), to efficiently train a detection cascade. BGSLDA exploits the sample re-weighting property of boosting and the class-separability criterion of GSLDA.