 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Initiated Open World Learning for Autonomous AI Agents
Oct 21, 2021As more and more AI agents are used in practice, it is time to think about how to make these agents fully autonomous so that they can learn by themselves in a self-motivated and self-supervised manner rather than being retrained periodically on the initiation of human engineers using expanded training data. As the real-world is an open environment with unknowns or novelties, detecting novelties or unknowns, gathering ground-truth training data, and incrementally learning the unknowns make the agent more and more knowledgeable and powerful over time. The key challenge is how to automate the process so that it is carried out on the agent's own initiative and through its own interactions with humans and the environment. Since an AI agent usually has a performance task, characterizing each novelty becomes necessary so that the agent can formulate an appropriate response to adapt its behavior to cope with the novelty and to learn from it to improve its future responses and task performance. This paper proposes a theoretic framework for this learning paradigm to promote the research of building self-initiated open world learning agents.
FLIN: A Flexible Natural Language Interface for Web Navigation
Oct 24, 2020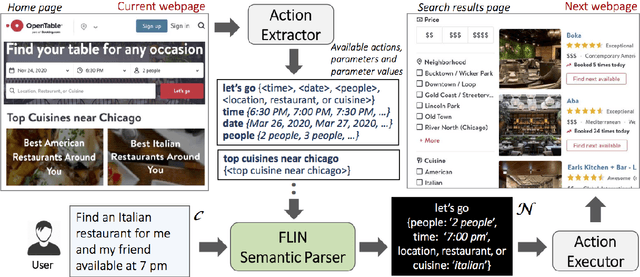
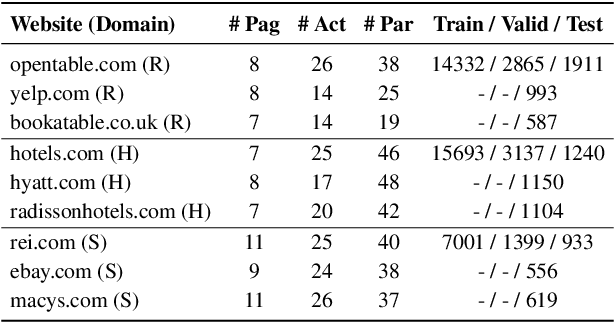
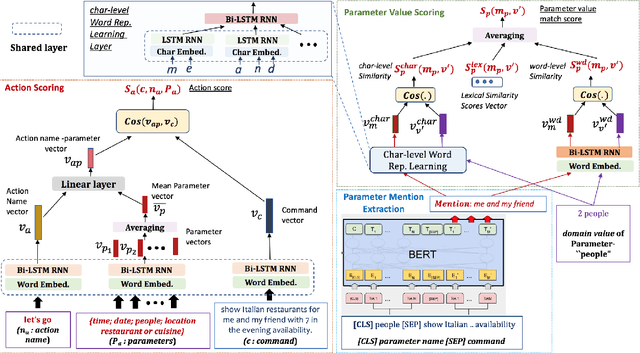
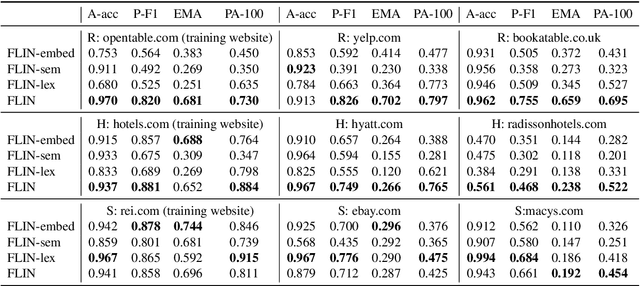
AI assistants have started carrying out tasks on a user's behalf by interacting directly with the web. However, training an interface that maps natural language (NL) commands to web actions is challenging for existing semantic parsing approaches due to the variable and unknown set of actions that characterize websites. We propose FLIN, a natural language interface for web navigation that maps NL commands to concept-level actions rather than low-level UI interactions, thus being able to flexibly adapt to different websites and handle their transient nature. We frame this as a ranking problem where, given a user command and a webpage, FLIN learns to score the most appropriate navigation instruction (involving action and parameter values). To train and evaluate FLIN, we collect a dataset using nine popular websites from three different domains. Quantitative results show that FLIN is capable of adapting to new websites in a given domain.
A Knowledge-Driven Approach to Classifying Object and Attribute Coreferences in Opinion Mining
Oct 11, 2020
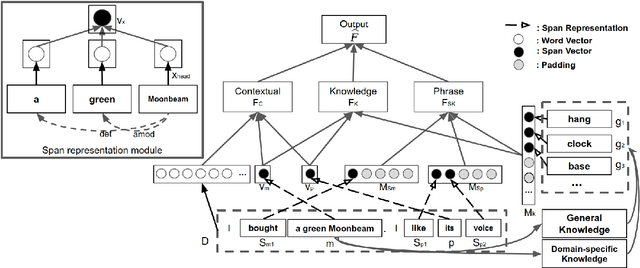

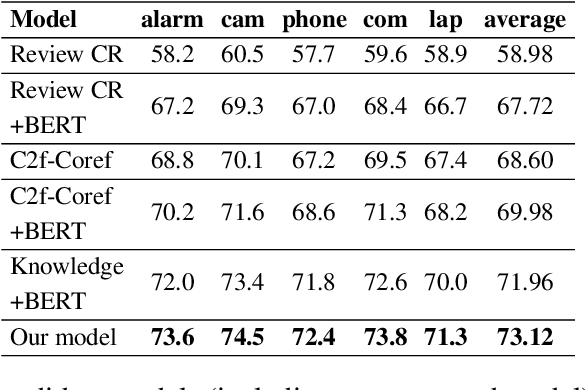
Classifying and resolving coreferences of objects (e.g., product names) and attributes (e.g., product aspects) in opinionated reviews is crucial for improving the opinion mining performance. However, the task is challenging as one often needs to consider domain-specific knowledge (e.g., iPad is a tablet and has aspect resolution) to identify coreferences in opinionated reviews. Also, compiling a handcrafted and curated domain-specific knowledge base for each domain is very time consuming and arduous. This paper proposes an approach to automatically mine and leverage domain-specific knowledge for classifying objects and attribute coreferences. The approach extracts domain-specific knowledge from unlabeled review data and trains a knowledgeaware neural coreference classification model to leverage (useful) domain knowledge together with general commonsense knowledge for the task. Experimental evaluation on realworld datasets involving five domains (product types) shows the effectiveness of the approach.
Lifelong Learning Dialogue Systems: Chatbots that Self-Learn On the Job
Sep 22, 2020Dialogue systems, also called chatbots, are now used in a wide range of applications. However, they still have some major weaknesses. One key weakness is that they are typically trained from manually-labeled data and/or written with handcrafted rules, and their knowledge bases (KBs) are also compiled by human experts. Due to the huge amount of manual effort involved, they are difficult to scale and also tend to produce many errors ought to their limited ability to understand natural language and the limited knowledge in their KBs. Thus, the level of user satisfactory is often low. In this paper, we propose to dramatically improve this situation by endowing the system the ability to continually learn (1) new world knowledge, (2) new language expressions to ground them to actions, and (3) new conversational skills, during conversation or "on the job" by themselves so that as the systems chat more and more with users, they become more and more knowledgeable and are better and better able to understand diverse natural language expressions and improve their conversational skills. A key approach to achieving these is to exploit the multi-user environment of such systems to self-learn through interactions with users via verb and non-verb means. The paper discusses not only key challenges and promising directions to learn from users during conversation but also how to ensure the correctness of the learned knowledge.
Detecting Domain Polarity-Changes of Words in a Sentiment Lexicon
Apr 29, 2020
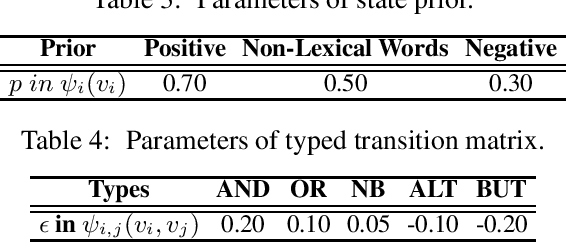
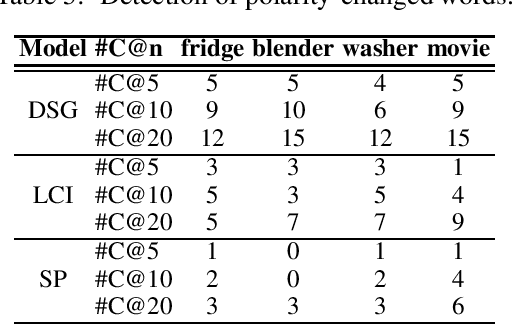
Sentiment lexicons are instrumental for sentiment analysis. One can use a set of sentiment words provided in a sentiment lexicon and a lexicon-based classifier to perform sentiment classification. One major issue with this approach is that many sentiment words are domain dependent. That is, they may be positive in some domains but negative in some others. We refer to this problem as domain polarity-changes of words. Detecting such words and correcting their sentiment for an application domain is very important. In this paper, we propose a graph-based technique to tackle this problem. Experimental results show its effectiveness on multiple real-world datasets.
Building an Application Independent Natural Language Interface
Oct 30, 2019
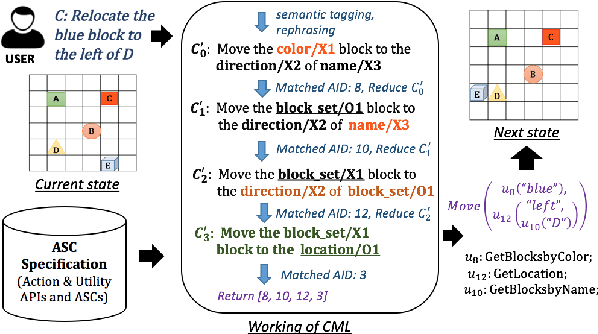


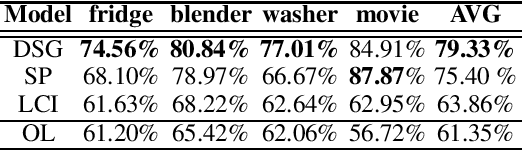
Traditional approaches to building natural language (NL) interfaces typically use a semantic parser to parse the user command and convert it to a logical form, which is then translated to an executable action in an application. However, it is still challenging for a semantic parser to correctly parse natural language. For a different domain, the parser may need to be retrained or tuned, and a new translator also needs to be written to convert the logical forms to executable actions. In this work, we propose a novel and application independent approach to building NL interfaces that does not need a semantic parser or a translator. It is based on natural language to natural language matching and learning, where the representation of each action and each user command are both in natural language. To perform a user intended action, the system only needs to match the user command with the correct action representation, and then execute the corresponding action. The system also interactively learns new (paraphrased) commands for actions to expand the action representations over time. Our experimental results show the effectiveness of the proposed approach.
Lifelong and Interactive Learning of Factual Knowledge in Dialogues
Jul 31, 2019
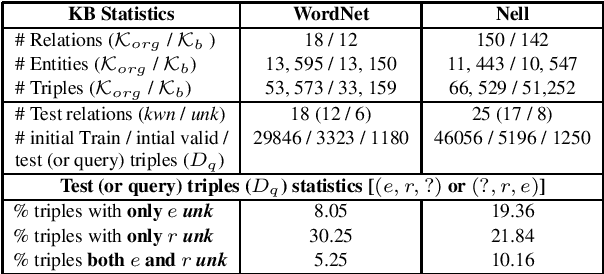
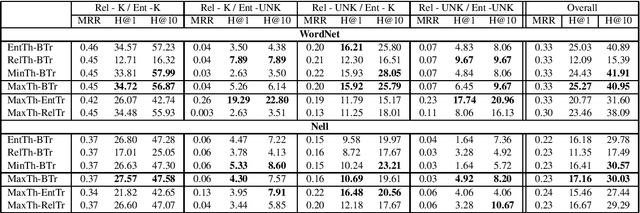
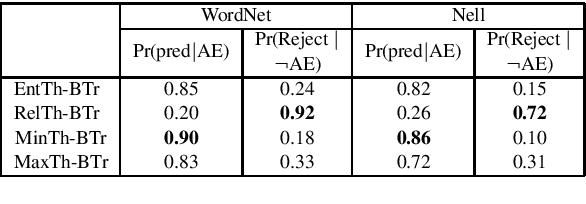
Dialogue systems are increasingly using knowledge bases (KBs) storing real-world facts to help generate quality responses. However, as the KBs are inherently incomplete and remain fixed during conversation, it limits dialogue systems' ability to answer questions and to handle questions involving entities or relations that are not in the KB. In this paper, we make an attempt to propose an engine for Continuous and Interactive Learning of Knowledge (CILK) for dialogue systems to give them the ability to continuously and interactively learn and infer new knowledge during conversations. With more knowledge accumulated over time, they will be able to learn better and answer more questions. Our empirical evaluation shows that CILK is promising.
Towards a Continuous Knowledge Learning Engine for Chatbots
Feb 24, 2018
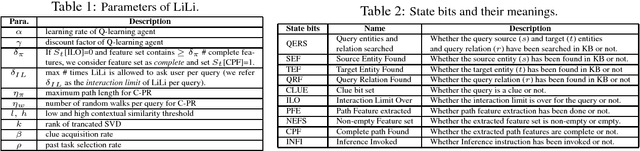

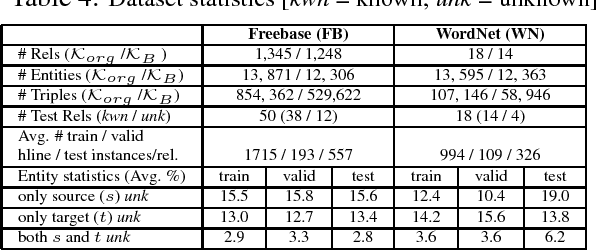
Although chatbots have been very popular in recent years, they still have some serious weaknesses which limit the scope of their applications. One major weakness is that they cannot learn new knowledge during the conversation process, i.e., their knowledge is fixed beforehand and cannot be expanded or updated during conversation. In this paper, we propose to build a general knowledge learning engine for chatbots to enable them to continuously and interactively learn new knowledge during conversations. As time goes by, they become more and more knowledgeable and better and better at learning and conversation. We model the task as an open-world knowledge base completion problem and propose a novel technique called lifelong interactive learning and inference (LiLi) to solve it. LiLi works by imitating how humans acquire knowledge and perform inference during an interactive conversation. Our experimental results show LiLi is highly promising.
Disentangling Aspect and Opinion Words in Target-based Sentiment Analysis using Lifelong Learning
Feb 16, 2018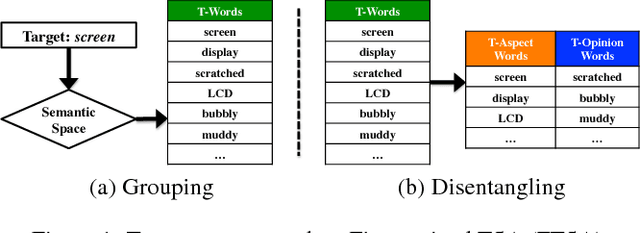

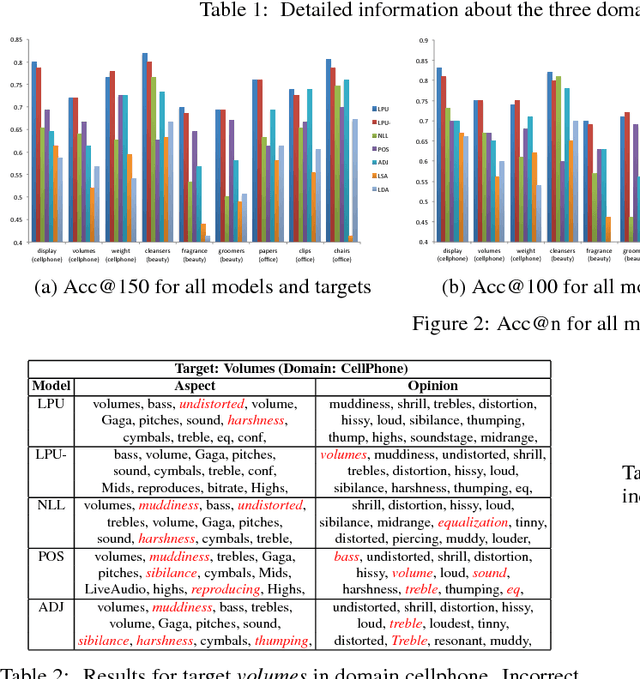
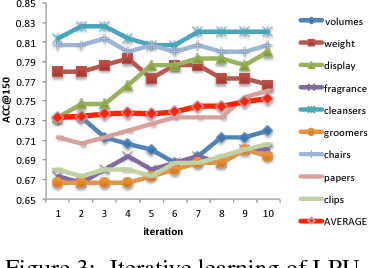
Given a target name, which can be a product aspect or entity, identifying its aspect words and opinion words in a given corpus is a fine-grained task in target-based sentiment analysis (TSA). This task is challenging, especially when we have no labeled data and we want to perform it for any given domain. To address it, we propose a general two-stage approach. Stage one extracts/groups the target-related words (call t-words) for a given target. This is relatively easy as we can apply an existing semantics-based learning technique. Stage two separates the aspect and opinion words from the grouped t-words, which is challenging because we often do not have enough word-level aspect and opinion labels. In this work, we formulate this problem in a PU learning setting and incorporate the idea of lifelong learning to solve it. Experimental results show the effectiveness of our approach.
Context-aware Path Ranking for Knowledge Base Completion
Dec 20, 2017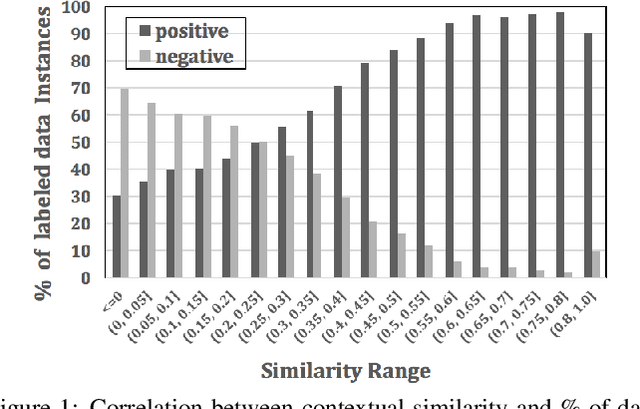

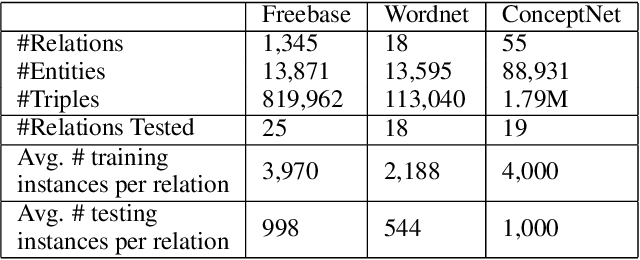
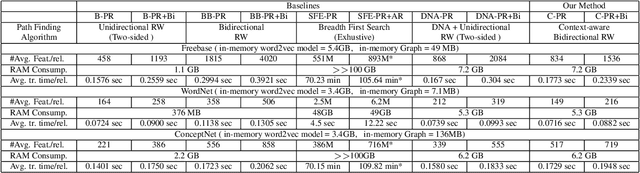
Knowledge base (KB) completion aims to infer missing facts from existing ones in a KB. Among various approaches, path ranking (PR) algorithms have received increasing attention in recent years. PR algorithms enumerate paths between entity pairs in a KB and use those paths as features to train a model for missing fact prediction. Due to their good performances and high model interpretability, several methods have been proposed. However, most existing methods suffer from scalability (high RAM consumption) and feature explosion (trains on an exponentially large number of features) problems. This paper proposes a Context-aware Path Ranking (C-PR) algorithm to solve these problems by introducing a selective path exploration strategy. C-PR learns global semantics of entities in the KB using word embedding and leverages the knowledge of entity semantics to enumerate contextually relevant paths using bidirectional random walk. Experimental results on three large KBs show that the path features (fewer in number) discovered by C-PR not only improve predictive performance but also are more interpretable than existing baselines.