 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAM-Fed: SAM-Guided Federated Semi-Supervised Learning for Medical Image Segmentation
Nov 18, 2025Medical image segmentation is clinically important, yet data privacy and the cost of expert annotation limit the availability of labeled data. Federated semi-supervised learning (FSSL) offers a solution but faces two challenges: pseudo-label reliability depends on the strength of local models, and client devices often require compact or heterogeneous architectures due to limited computational resources. These constraints reduce the quality and stability of pseudo-labels, while large models, though more accurate, cannot be trained or used for routine inference on client devices. We propose SAM-Fed, a federated semi-supervised framework that leverages a high-capacity segmentation foundation model to guide lightweight clients during training. SAM-Fed combines dual knowledge distillation with an adaptive agreement mechanism to refine pixel-level supervision. Experiments on skin lesion and polyp segmentation across homogeneous and heterogeneous settings show that SAM-Fed consistently outperforms state-of-the-art FSSL methods.
Data-Efficient Learning for Generalizable Surgical Video Understanding
Aug 13, 2025Advances in surgical video analysis are transforming operating rooms into intelligent, data-driven environments. Computer-assisted systems support full surgical workflow, from preoperative planning to intraoperative guidance and postoperative assessment. However, developing robust and generalizable models for surgical video understanding remains challenging due to (I) annotation scarcity, (II) spatiotemporal complexity, and (III) domain gap across procedures and institutions. This doctoral research aims to bridge the gap between deep learning-based surgical video analysis in research and its real-world clinical deployment. To address the core challenge of recognizing surgical phases, actions, and events, critical for analysis, I benchmarked state-of-the-art neural network architectures to identify the most effective designs for each task. I further improved performance by proposing novel architectures and integrating advanced modules. Given the high cost of expert annotations and the domain gap across surgical video sources, I focused on reducing reliance on labeled data. We developed semi-supervised frameworks that improve model performance across tasks by leveraging large amounts of unlabeled surgical video. We introduced novel semi-supervised frameworks, including DIST, SemiVT-Surge, and ENCORE, that achieved state-of-the-art results on challenging surgical datasets by leveraging minimal labeled data and enhancing model training through dynamic pseudo-labeling. To support reproducibility and advance the field, we released two multi-task datasets: GynSurg, the largest gynecologic laparoscopy dataset, and Cataract-1K, the largest cataract surgery video dataset. Together, this work contributes to robust, data-efficient, and clinically scalable solutions for surgical video analysis, laying the foundation for generalizable AI systems that can meaningfully impact surgical care and training.
Comparative validation of surgical phase recognition, instrument keypoint estimation, and instrument instance segmentation in endoscopy: Results of the PhaKIR 2024 challenge
Jul 22, 2025Reliable recognition and localization of surgical instruments in endoscopic video recordings are foundational for a wide range of applications in computer- and robot-assisted minimally invasive surgery (RAMIS), including surgical training, skill assessment, and autonomous assistance. However, robust performance under real-world conditions remains a significant challenge. Incorporating surgical context - such as the current procedural phase - has emerged as a promising strategy to improve robustness and interpretability. To address these challenges, we organized the Surgical Procedure Phase, Keypoint, and Instrument Recognition (PhaKIR) sub-challenge as part of the Endoscopic Vision (EndoVis) challenge at MICCAI 2024. We introduced a novel, multi-center dataset comprising thirteen full-length laparoscopic cholecystectomy videos collected from three distinct medical institutions, with unified annotations for three interrelated tasks: surgical phase recognition, instrument keypoint estimation, and instrument instance segmentation. Unlike existing datasets, ours enables joint investigation of instrument localization and procedural context within the same data while supporting the integration of temporal information across entire procedures. We report results and findings in accordance with the BIAS guidelines for biomedical image analysis challenges. The PhaKIR sub-challenge advances the field by providing a unique benchmark for developing temporally aware, context-driven methods in RAMIS and offers a high-quality resource to support future research in surgical scene understanding.
GynSurg: A Comprehensive Gynecology Laparoscopic Surgery Dataset
Jun 12, 2025Recent advances in deep learning have transformed computer-assisted intervention and surgical video analysis, driving improvements not only in surgical training, intraoperative decision support, and patient outcomes, but also in postoperative documentation and surgical discovery. Central to these developments is the availability of large, high-quality annotated datasets. In gynecologic laparoscopy, surgical scene understanding and action recognition are fundamental for building intelligent systems that assist surgeons during operations and provide deeper analysis after surgery. However, existing datasets are often limited by small scale, narrow task focus, or insufficiently detailed annotations, limiting their utility for comprehensive, end-to-end workflow analysis. To address these limitations, we introduce GynSurg, the largest and most diverse multi-task dataset for gynecologic laparoscopic surgery to date. GynSurg provides rich annotations across multiple tasks, supporting applications in action recognition, semantic segmentation, surgical documentation, and discovery of novel procedural insights. We demonstrate the dataset quality and versatility by benchmarking state-of-the-art models under a standardized training protocol. To accelerate progress in the field, we publicly release the GynSurg dataset and its annotations
Feedback-Driven Pseudo-Label Reliability Assessment: Redefining Thresholding for Semi-Supervised Semantic Segmentation
May 12, 2025



Semi-supervised learning leverages unlabeled data to enhance model performance, addressing the limitations of fully supervised approaches. Among its strategies, pseudo-supervision has proven highly effective, typically relying on one or multiple teacher networks to refine pseudo-labels before training a student network. A common practice in pseudo-supervision is filtering pseudo-labels based on pre-defined confidence thresholds or entropy. However, selecting optimal thresholds requires large labeled datasets, which are often scarce in real-world semi-supervised scenarios. To overcome this challenge, we propose Ensemble-of-Confidence Reinforcement (ENCORE), a dynamic feedback-driven thresholding strategy for pseudo-label selection. Instead of relying on static confidence thresholds, ENCORE estimates class-wise true-positive confidence within the unlabeled dataset and continuously adjusts thresholds based on the model's response to different levels of pseudo-label filtering. This feedback-driven mechanism ensures the retention of informative pseudo-labels while filtering unreliable ones, enhancing model training without manual threshold tuning. Our method seamlessly integrates into existing pseudo-supervision frameworks and significantly improves segmentation performance, particularly in data-scarce conditions. Extensive experiments demonstrate that integrating ENCORE with existing pseudo-supervision frameworks enhances performance across multiple datasets and network architectures, validating its effectiveness in semi-supervised learning.
Dual Invariance Self-training for Reliable Semi-supervised Surgical Phase Recognition
Jan 29, 2025



Accurate surgical phase recognition is crucial for advancing computer-assisted interventions, yet the scarcity of labeled data hinders training reliable deep learning models. Semi-supervised learning (SSL), particularly with pseudo-labeling, shows promise over fully supervised methods but often lacks reliable pseudo-label assessment mechanisms. To address this gap, we propose a novel SSL framework, Dual Invariance Self-Training (DIST), that incorporates both Temporal and Transformation Invariance to enhance surgical phase recognition. Our two-step self-training process dynamically selects reliable pseudo-labels, ensuring robust pseudo-supervision. Our approach mitigates the risk of noisy pseudo-labels, steering decision boundaries toward true data distribution and improving generalization to unseen data. Evaluations on Cataract and Cholec80 datasets show our method outperforms state-of-the-art SSL approaches, consistently surpassing both supervised and SSL baselines across various network architectures.
Cataract-1K: Cataract Surgery Dataset for Scene Segmentation, Phase Recognition, and Irregularity Detection
Dec 11, 2023



In recent years, the landscape of computer-assisted interventions and post-operative surgical video analysis has been dramatically reshaped by deep-learning techniques, resulting in significant advancements in surgeons' skills, operation room management, and overall surgical outcomes. However, the progression of deep-learning-powered surgical technologies is profoundly reliant on large-scale datasets and annotations. Particularly, surgical scene understanding and phase recognition stand as pivotal pillars within the realm of computer-assisted surgery and post-operative assessment of cataract surgery videos. In this context, we present the largest cataract surgery video dataset that addresses diverse requisites for constructing computerized surgical workflow analysis and detecting post-operative irregularities in cataract surgery. We validate the quality of annotations by benchmarking the performance of several state-of-the-art neural network architectures for phase recognition and surgical scene segmentation. Besides, we initiate the research on domain adaptation for instrument segmentation in cataract surgery by evaluating cross-domain instrument segmentation performance in cataract surgery videos. The dataset and annotations will be publicly available upon acceptance of the paper.
Event Recognition in Laparoscopic Gynecology Videos with Hybrid Transformers
Dec 01, 2023
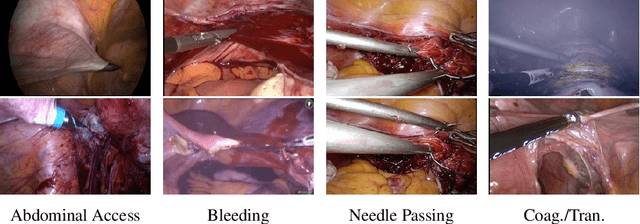


Analyzing laparoscopic surgery videos presents a complex and multifaceted challenge, with applications including surgical training, intra-operative surgical complication prediction, and post-operative surgical assessment. Identifying crucial events within these videos is a significant prerequisite in a majority of these applications. In this paper, we introduce a comprehensive dataset tailored for relevant event recognition in laparoscopic gynecology videos. Our dataset includes annotations for critical events associated with major intra-operative challenges and post-operative complications. To validate the precision of our annotations, we assess event recognition performance using several CNN-RNN architectures. Furthermore, we introduce and evaluate a hybrid transformer architecture coupled with a customized training-inference framework to recognize four specific events in laparoscopic surgery videos. Leveraging the Transformer networks, our proposed architecture harnesses inter-frame dependencies to counteract the adverse effects of relevant content occlusion, motion blur, and surgical scene variation, thus significantly enhancing event recognition accuracy. Moreover, we present a frame sampling strategy designed to manage variations in surgical scenes and the surgeons' skill level, resulting in event recognition with high temporal resolution. We empirically demonstrate the superiority of our proposed methodology in event recognition compared to conventional CNN-RNN architectures through a series of extensive experiments.
Action Recognition in Video Recordings from Gynecologic Laparoscopy
Nov 30, 2023Action recognition is a prerequisite for many applications in laparoscopic video analysis including but not limited to surgical training, operation room planning, follow-up surgery preparation, post-operative surgical assessment, and surgical outcome estimation. However, automatic action recognition in laparoscopic surgeries involves numerous challenges such as (I) cross-action and intra-action duration variation, (II) relevant content distortion due to smoke, blood accumulation, fast camera motions, organ movements, object occlusion, and (III) surgical scene variations due to different illuminations and viewpoints. Besides, action annotations in laparoscopy surgeries are limited and expensive due to requiring expert knowledge. In this study, we design and evaluate a CNN-RNN architecture as well as a customized training-inference framework to deal with the mentioned challenges in laparoscopic surgery action recognition. Using stacked recurrent layers, our proposed network takes advantage of inter-frame dependencies to negate the negative effect of content distortion and variation in action recognition. Furthermore, our proposed frame sampling strategy effectively manages the duration variations in surgical actions to enable action recognition with high temporal resolution. Our extensive experiments confirm the superiority of our proposed method in action recognition compared to static CNNs.