 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntermediate Representations for Enhanced Text-To-Image Generation Using Diffusion Models
Oct 13, 2024Text-to-image diffusion models have demonstrated an impressive ability to produce high-quality outputs. However, they often struggle to accurately follow fine-grained spatial information in an input text. To this end, we propose a compositional approach for text-to-image generation based on two stages. In the first stage, we design a diffusion-based generative model to produce one or more aligned intermediate representations (such as depth or segmentation maps) conditioned on text. In the second stage, we map these representations, together with the text, to the final output image using a separate diffusion-based generative model. Our findings indicate that such compositional approach can improve image generation, resulting in a notable improvement in FID score and a comparable CLIP score, when compared to the standard non-compositional baseline.
Improving Visual Commonsense in Language Models via Multiple Image Generation
Jun 19, 2024



Commonsense reasoning is fundamentally based on multimodal knowledge. However, existing large language models (LLMs) are primarily trained using textual data only, limiting their ability to incorporate essential visual information. In contrast, Visual Language Models, which excel at visually-oriented tasks, often fail at non-visual tasks such as basic commonsense reasoning. This divergence highlights a critical challenge - the integration of robust visual understanding with foundational text-based language reasoning. To this end, we introduce a method aimed at enhancing LLMs' visual commonsense. Specifically, our method generates multiple images based on the input text prompt and integrates these into the model's decision-making process by mixing their prediction probabilities. To facilitate multimodal grounded language modeling, we employ a late-fusion layer that combines the projected visual features with the output of a pre-trained LLM conditioned on text only. This late-fusion layer enables predictions based on comprehensive image-text knowledge as well as text only when this is required. We evaluate our approach using several visual commonsense reasoning tasks together with traditional NLP tasks, including common sense reasoning and reading comprehension. Our experimental results demonstrate significant superiority over existing baselines. When applied to recent state-of-the-art LLMs (e.g., Llama3), we observe improvements not only in visual common sense but also in traditional NLP benchmarks. Code and models are available under https://github.com/guyyariv/vLMIG.
Coarse-To-Fine Tensor Trains for Compact Visual Representations
Jun 06, 2024



The ability to learn compact, high-quality, and easy-to-optimize representations for visual data is paramount to many applications such as novel view synthesis and 3D reconstruction. Recent work has shown substantial success in using tensor networks to design such compact and high-quality representations. However, the ability to optimize tensor-based representations, and in particular, the highly compact tensor train representation, is still lacking. This has prevented practitioners from deploying the full potential of tensor networks for visual data. To this end, we propose 'Prolongation Upsampling Tensor Train (PuTT)', a novel method for learning tensor train representations in a coarse-to-fine manner. Our method involves the prolonging or `upsampling' of a learned tensor train representation, creating a sequence of 'coarse-to-fine' tensor trains that are incrementally refined. We evaluate our representation along three axes: (1). compression, (2). denoising capability, and (3). image completion capability. To assess these axes, we consider the tasks of image fitting, 3D fitting, and novel view synthesis, where our method shows an improved performance compared to state-of-the-art tensor-based methods. For full results see our project webpage: https://sebulo.github.io/PuTT_website/
DGD: Dynamic 3D Gaussians Distillation
May 29, 2024



We tackle the task of learning dynamic 3D semantic radiance fields given a single monocular video as input. Our learned semantic radiance field captures per-point semantics as well as color and geometric properties for a dynamic 3D scene, enabling the generation of novel views and their corresponding semantics. This enables the segmentation and tracking of a diverse set of 3D semantic entities, specified using a simple and intuitive interface that includes a user click or a text prompt. To this end, we present DGD, a unified 3D representation for both the appearance and semantics of a dynamic 3D scene, building upon the recently proposed dynamic 3D Gaussians representation. Our representation is optimized over time with both color and semantic information. Key to our method is the joint optimization of the appearance and semantic attributes, which jointly affect the geometric properties of the scene. We evaluate our approach in its ability to enable dense semantic 3D object tracking and demonstrate high-quality results that are fast to render, for a diverse set of scenes. Our project webpage is available on https://isaaclabe.github.io/DGD-Website/
Reward Finetuning for Faster and More Accurate Unsupervised Object Discovery
Nov 05, 2023



Recent advances in machine learning have shown that Reinforcement Learning from Human Feedback (RLHF) can improve machine learning models and align them with human preferences. Although very successful for Large Language Models (LLMs), these advancements have not had a comparable impact in research for autonomous vehicles -- where alignment with human expectations can be imperative. In this paper, we propose to adapt similar RL-based methods to unsupervised object discovery, i.e. learning to detect objects from LiDAR points without any training labels. Instead of labels, we use simple heuristics to mimic human feedback. More explicitly, we combine multiple heuristics into a simple reward function that positively correlates its score with bounding box accuracy, i.e., boxes containing objects are scored higher than those without. We start from the detector's own predictions to explore the space and reinforce boxes with high rewards through gradient updates. Empirically, we demonstrate that our approach is not only more accurate, but also orders of magnitudes faster to train compared to prior works on object discovery.
Diverse and Aligned Audio-to-Video Generation via Text-to-Video Model Adaptation
Sep 28, 2023



We consider the task of generating diverse and realistic videos guided by natural audio samples from a wide variety of semantic classes. For this task, the videos are required to be aligned both globally and temporally with the input audio: globally, the input audio is semantically associated with the entire output video, and temporally, each segment of the input audio is associated with a corresponding segment of that video. We utilize an existing text-conditioned video generation model and a pre-trained audio encoder model. The proposed method is based on a lightweight adaptor network, which learns to map the audio-based representation to the input representation expected by the text-to-video generation model. As such, it also enables video generation conditioned on text, audio, and, for the first time as far as we can ascertain, on both text and audio. We validate our method extensively on three datasets demonstrating significant semantic diversity of audio-video samples and further propose a novel evaluation metric (AV-Align) to assess the alignment of generated videos with input audio samples. AV-Align is based on the detection and comparison of energy peaks in both modalities. In comparison to recent state-of-the-art approaches, our method generates videos that are better aligned with the input sound, both with respect to content and temporal axis. We also show that videos produced by our method present higher visual quality and are more diverse.
Discriminative Class Tokens for Text-to-Image Diffusion Models
Mar 30, 2023Recent advances in text-to-image diffusion models have enabled the generation of diverse and high-quality images. However, generated images often fall short of depicting subtle details and are susceptible to errors due to ambiguity in the input text. One way of alleviating these issues is to train diffusion models on class-labeled datasets. This comes with a downside, doing so limits their expressive power: (i) supervised datasets are generally small compared to large-scale scraped text-image datasets on which text-to-image models are trained, and so the quality and diversity of generated images are severely affected, or (ii) the input is a hard-coded label, as opposed to free-form text, which limits the control over the generated images. In this work, we propose a non-invasive fine-tuning technique that capitalizes on the expressive potential of free-form text while achieving high accuracy through discriminative signals from a pretrained classifier, which guides the generation. This is done by iteratively modifying the embedding of a single input token of a text-to-image diffusion model, using the classifier, by steering generated images toward a given target class. Our method is fast compared to prior fine-tuning methods and does not require a collection of in-class images or retraining of a noise-tolerant classifier. We evaluate our method extensively, showing that the generated images are: (i) more accurate and of higher quality than standard diffusion models, (ii) can be used to augment training data in a low-resource setting, and (iii) reveal information about the data used to train the guiding classifier. The code is available at \url{https://github.com/idansc/discriminative_class_tokens}
Polynomial Neural Fields for Subband Decomposition and Manipulation
Feb 09, 2023



Neural fields have emerged as a new paradigm for representing signals, thanks to their ability to do it compactly while being easy to optimize. In most applications, however, neural fields are treated like black boxes, which precludes many signal manipulation tasks. In this paper, we propose a new class of neural fields called polynomial neural fields (PNFs). The key advantage of a PNF is that it can represent a signal as a composition of a number of manipulable and interpretable components without losing the merits of neural fields representation. We develop a general theoretical framework to analyze and design PNFs. We use this framework to design Fourier PNFs, which match state-of-the-art performance in signal representation tasks that use neural fields. In addition, we empirically demonstrate that Fourier PNFs enable signal manipulation applications such as texture transfer and scale-space interpolation. Code is available at https://github.com/stevenygd/PNF.
Assessing Neural Network Robustness via Adversarial Pivotal Tuning
Nov 17, 2022The ability to assess the robustness of image classifiers to a diverse set of manipulations is essential to their deployment in the real world. Recently, semantic manipulations of real images have been considered for this purpose, as they may not arise using standard adversarial settings. However, such semantic manipulations are often limited to style, color or attribute changes. While expressive, these manipulations do not consider the full capacity of a pretrained generator to affect adversarial image manipulations. In this work, we aim at leveraging the full capacity of a pretrained image generator to generate highly detailed, diverse and photorealistic image manipulations. Inspired by recent GAN-based image inversion methods, we propose a method called Adversarial Pivotal Tuning (APT). APT first finds a pivot latent space input to a pretrained generator that best reconstructs an input image. It then adjusts the weights of the generator to create small, but semantic, manipulations which fool a pretrained classifier. Crucially, APT changes both the input and the weights of the pretrained generator, while preserving its expressive latent editing capability, thus allowing the use of its full capacity in creating semantic adversarial manipulations. We demonstrate that APT generates a variety of semantic image manipulations, which preserve the input image class, but which fool a variety of pretrained classifiers. We further demonstrate that classifiers trained to be robust to other robustness benchmarks, are not robust to our generated manipulations and propose an approach to improve the robustness towards our generated manipulations. Code available at: https://captaine.github.io/apt/
FewGAN: Generating from the Joint Distribution of a Few Images
Jul 18, 2022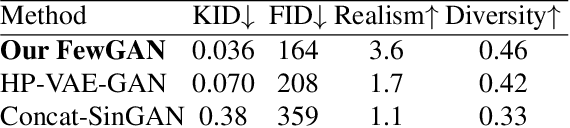
We introduce FewGAN, a generative model for generating novel, high-quality and diverse images whose patch distribution lies in the joint patch distribution of a small number of N>1 training samples. The method is, in essence, a hierarchical patch-GAN that applies quantization at the first coarse scale, in a similar fashion to VQ-GAN, followed by a pyramid of residual fully convolutional GANs at finer scales. Our key idea is to first use quantization to learn a fixed set of patch embeddings for training images. We then use a separate set of side images to model the structure of generated images using an autoregressive model trained on the learned patch embeddings of training images. Using quantization at the coarsest scale allows the model to generate both conditional and unconditional novel images. Subsequently, a patch-GAN renders the fine details, resulting in high-quality images. In an extensive set of experiments, it is shown that FewGAN outperforms baselines both quantitatively and qualitatively.