 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurvey on Leveraging Uncertainty Estimation Towards Trustworthy Deep Neural Networks: The Case of Reject Option and Post-training Processing
Apr 11, 2023



Although neural networks (especially deep neural networks) have achieved \textit{better-than-human} performance in many fields, their real-world deployment is still questionable due to the lack of awareness about the limitation in their knowledge. To incorporate such awareness in the machine learning model, prediction with reject option (also known as selective classification or classification with abstention) has been proposed in literature. In this paper, we present a systematic review of the prediction with the reject option in the context of various neural networks. To the best of our knowledge, this is the first study focusing on this aspect of neural networks. Moreover, we discuss different novel loss functions related to the reject option and post-training processing (if any) of network output for generating suitable measurements for knowledge awareness of the model. Finally, we address the application of the rejection option in reducing the prediction time for the real-time problems and present a comprehensive summary of the techniques related to the reject option in the context of extensive variety of neural networks. Our code is available on GitHub: \url{https://github.com/MehediHasanTutul/Reject_option}
A Brief Review of Explainable Artificial Intelligence in Healthcare
Apr 04, 2023



XAI refers to the techniques and methods for building AI applications which assist end users to interpret output and predictions of AI models. Black box AI applications in high-stakes decision-making situations, such as medical domain have increased the demand for transparency and explainability since wrong predictions may have severe consequences. Model explainability and interpretability are vital successful deployment of AI models in healthcare practices. AI applications' underlying reasoning needs to be transparent to clinicians in order to gain their trust. This paper presents a systematic review of XAI aspects and challenges in the healthcare domain. The primary goals of this study are to review various XAI methods, their challenges, and related machine learning models in healthcare. The methods are discussed under six categories: Features-oriented methods, global methods, concept models, surrogate models, local pixel-based methods, and human-centric methods. Most importantly, the paper explores XAI role in healthcare problems to clarify its necessity in safety-critical applications. The paper intends to establish a comprehensive understanding of XAI-related applications in the healthcare field by reviewing the related experimental results. To facilitate future research for filling research gaps, the importance of XAI models from different viewpoints and their limitations are investigated.
A Comprehensive Review on Autonomous Navigation
Dec 24, 2022



The field of autonomous mobile robots has undergone dramatic advancements over the past decades. Despite achieving important milestones, several challenges are yet to be addressed. Aggregating the achievements of the robotic community as survey papers is vital to keep the track of current state-of-the-art and the challenges that must be tackled in the future. This paper tries to provide a comprehensive review of autonomous mobile robots covering topics such as sensor types, mobile robot platforms, simulation tools, path planning and following, sensor fusion methods, obstacle avoidance, and SLAM. The urge to present a survey paper is twofold. First, autonomous navigation field evolves fast so writing survey papers regularly is crucial to keep the research community well-aware of the current status of this field. Second, deep learning methods have revolutionized many fields including autonomous navigation. Therefore, it is necessary to give an appropriate treatment of the role of deep learning in autonomous navigation as well which is covered in this paper. Future works and research gaps will also be discussed.
CoV-TI-Net: Transferred Initialization with Modified End Layer for COVID-19 Diagnosis
Sep 20, 2022
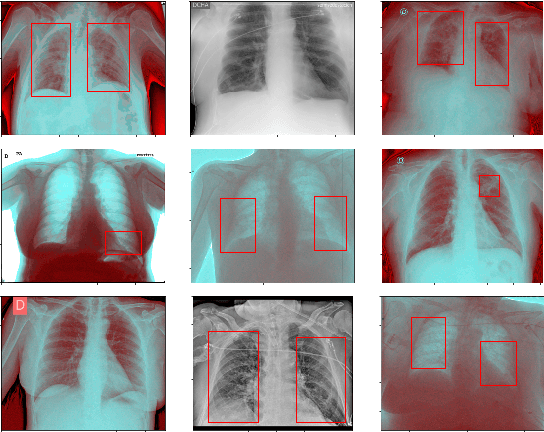
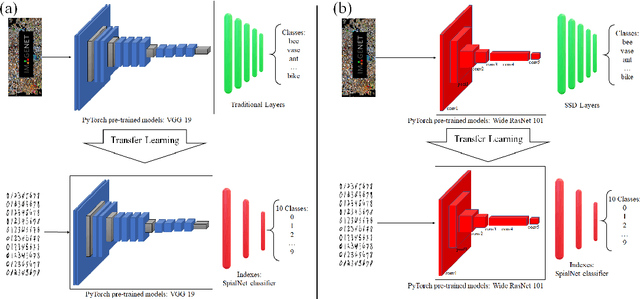
This paper proposes transferred initialization with modified fully connected layers for COVID-19 diagnosis. Convolutional neural networks (CNN) achieved a remarkable result in image classification. However, training a high-performing model is a very complicated and time-consuming process because of the complexity of image recognition applications. On the other hand, transfer learning is a relatively new learning method that has been employed in many sectors to achieve good performance with fewer computations. In this research, the PyTorch pre-trained models (VGG19\_bn and WideResNet -101) are applied in the MNIST dataset for the first time as initialization and with modified fully connected layers. The employed PyTorch pre-trained models were previously trained in ImageNet. The proposed model is developed and verified in the Kaggle notebook, and it reached the outstanding accuracy of 99.77% without taking a huge computational time during the training process of the network. We also applied the same methodology to the SIIM-FISABIO-RSNA COVID-19 Detection dataset and achieved 80.01% accuracy. In contrast, the previous methods need a huge compactional time during the training process to reach a high-performing model. Codes are available at the following link: github.com/dipuk0506/SpinalNet
Controlled Dropout for Uncertainty Estimation
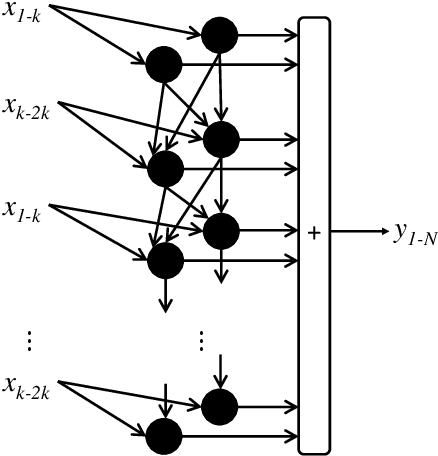
May 06, 2022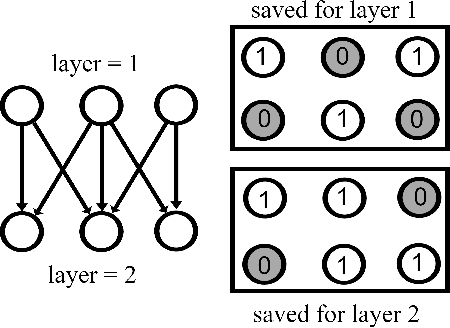
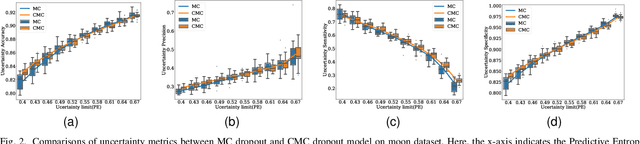
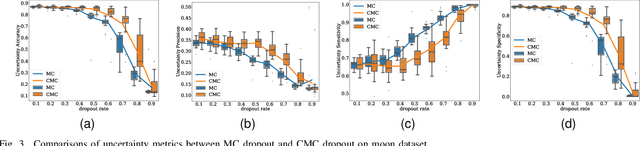
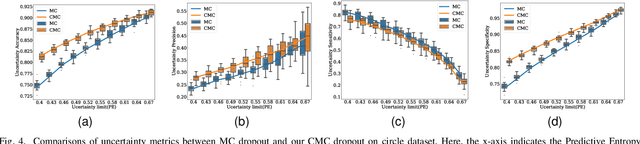
Uncertainty quantification in a neural network is one of the most discussed topics for safety-critical applications. Though Neural Networks (NNs) have achieved state-of-the-art performance for many applications, they still provide unreliable point predictions, which lack information about uncertainty estimates. Among various methods to enable neural networks to estimate uncertainty, Monte Carlo (MC) dropout has gained much popularity in a short period due to its simplicity. In this study, we present a new version of the traditional dropout layer where we are able to fix the number of dropout configurations. As such, each layer can take and apply the new dropout layer in the MC method to quantify the uncertainty associated with NN predictions. We conduct experiments on both toy and realistic datasets and compare the results with the MC method using the traditional dropout layer. Performance analysis utilizing uncertainty evaluation metrics corroborates that our dropout layer offers better performance in most cases.
Critical Review of Exoskeleton Technology: State of the art and development of physical and cognitive human-robot interface
Dec 07, 2021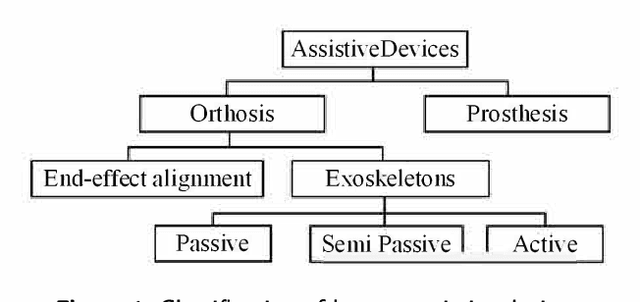
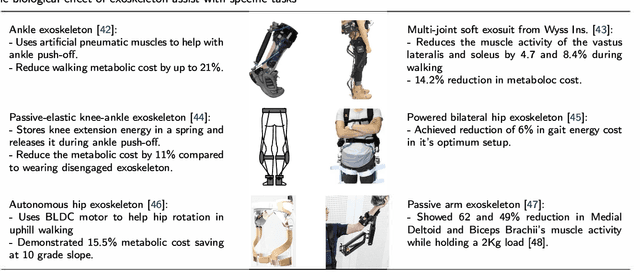
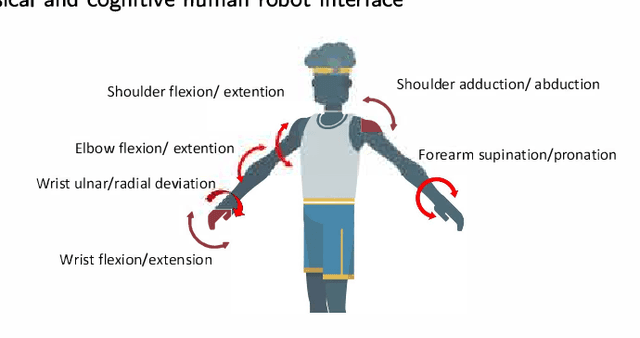
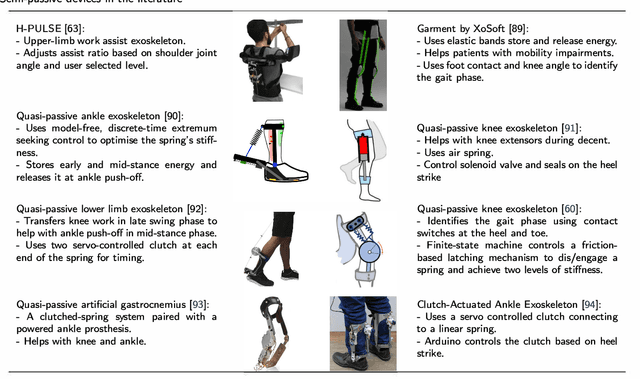
Exoskeletons and orthoses are wearable mobile systems providing mechanical benefits to the users. Despite significant improvements in the last decades, the technology is not fully mature to be adopted for strenuous and non-programmed tasks. To accommodate this insufficiency, different aspects of this technology need to be analysed and improved. Numerous studies have been trying to address some aspects of exoskeletons, e.g. mechanism design, intent prediction, and control scheme. However, most works have focused on a specific element of design or application without providing a comprehensive review framework. This study aims to analyse and survey the contributing aspects to the improvement and broad adoption of this technology. To address this, after introducing assistive devices and exoskeletons, the main design criteria will be investigated from a physical Human-Robot Interface (HRI) perspective. The study will be further developed by outlining several examples of known assistive devices in different categories. In order to establish an intelligent HRI strategy and enabling intuitive control for users, cognitive HRI will be investigated. Various approaches to this strategy will be reviewed, and a model for intent prediction will be proposed. This model is utilised to predict the gate phase from a single Electromyography (EMG) channel input. The outcomes of modelling show the potential use of single-channel input in low-power assistive devices. Furthermore, the proposed model can provide redundancy in devices with a complex control strategy.
A Comprehensive Study on Torchvision Pre-trained Models for Fine-grained Inter-species Classification
Oct 14, 2021



This study aims to explore different pre-trained models offered in the Torchvision package which is available in the PyTorch library. And investigate their effectiveness on fine-grained images classification. Transfer Learning is an effective method of achieving extremely good performance with insufficient training data. In many real-world situations, people cannot collect sufficient data required to train a deep neural network model efficiently. Transfer Learning models are pre-trained on a large data set, and can bring a good performance on smaller datasets with significantly lower training time. Torchvision package offers us many models to apply the Transfer Learning on smaller datasets. Therefore, researchers may need a guideline for the selection of a good model. We investigate Torchvision pre-trained models on four different data sets: 10 Monkey Species, 225 Bird Species, Fruits 360, and Oxford 102 Flowers. These data sets have images of different resolutions, class numbers, and different achievable accuracies. We also apply their usual fully-connected layer and the Spinal fully-connected layer to investigate the effectiveness of SpinalNet. The Spinal fully-connected layer brings better performance in most situations. We apply the same augmentation for different models for the same data set for a fair comparison. This paper may help future Computer Vision researchers in choosing a proper Transfer Learning model.
* Accepted
Improving MC-Dropout Uncertainty Estimates with Calibration Error-based Optimization
Oct 07, 2021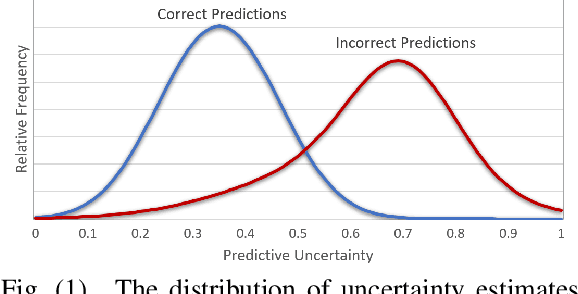
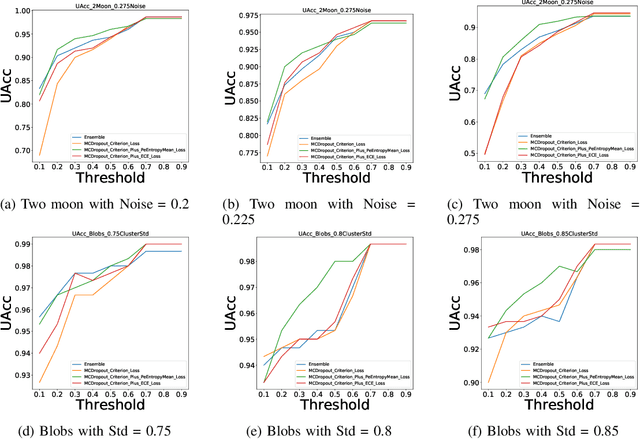
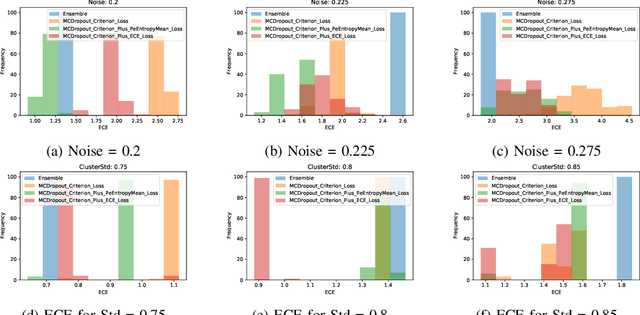
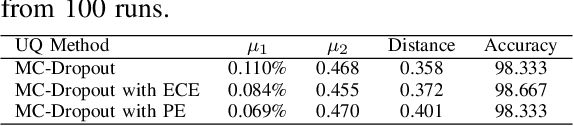
Uncertainty quantification of machine learning and deep learning methods plays an important role in enhancing trust to the obtained result. In recent years, a numerous number of uncertainty quantification methods have been introduced. Monte Carlo dropout (MC-Dropout) is one of the most well-known techniques to quantify uncertainty in deep learning methods. In this study, we propose two new loss functions by combining cross entropy with Expected Calibration Error (ECE) and Predictive Entropy (PE). The obtained results clearly show that the new proposed loss functions lead to having a calibrated MC-Dropout method. Our results confirmed the great impact of the new hybrid loss functions for minimising the overlap between the distributions of uncertainty estimates for correct and incorrect predictions without sacrificing the model's overall performance.
What happens in Face during a facial expression? Using data mining techniques to analyze facial expression motion vectors
Sep 12, 2021
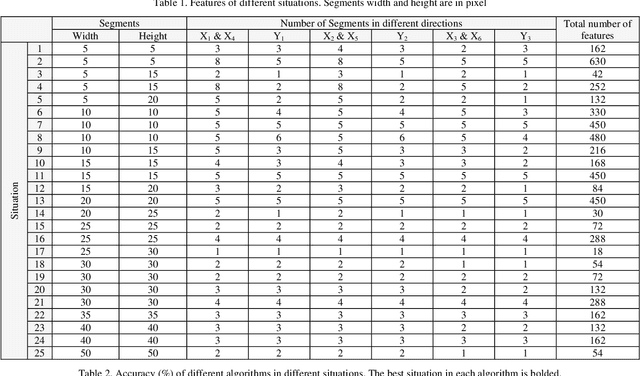


One of the most common problems encountered in human-computer interaction is automatic facial expression recognition. Although it is easy for human observer to recognize facial expressions, automatic recognition remains difficult for machines. One of the methods that machines can recognize facial expression is analyzing the changes in face during facial expression presentation. In this paper, optical flow algorithm was used to extract deformation or motion vectors created in the face because of facial expressions. Then, these extracted motion vectors are used to be analyzed. Their positions and directions were exploited for automatic facial expression recognition using different data mining techniques. It means that by employing motion vector features used as our data, facial expressions were recognized. Some of the most state-of-the-art classification algorithms such as C5.0, CRT, QUEST, CHAID, Deep Learning (DL), SVM and Discriminant algorithms were used to classify the extracted motion vectors. Using 10-fold cross validation, their performances were calculated. To compare their performance more precisely, the test was repeated 50 times. Meanwhile, the deformation of face was also analyzed in this research. For example, what exactly happened in each part of face when a person showed fear? Experimental results on Extended Cohen-Kanade (CK+) facial expression dataset demonstrated that the best methods were DL, SVM and C5.0, with the accuracy of 95.3%, 92.8% and 90.2% respectively.
Automatic Diagnosis of Schizophrenia using EEG Signals and CNN-LSTM Models
Sep 02, 2021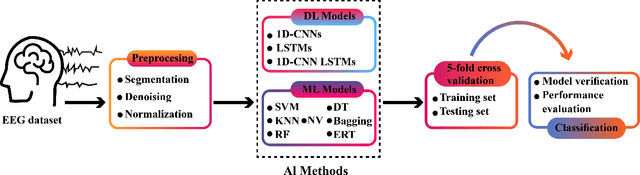
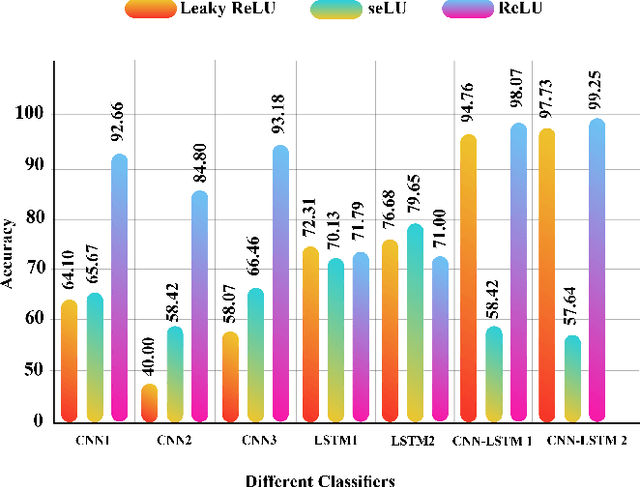

Schizophrenia (SZ) is a mental disorder whereby due to the secretion of specific chemicals in the brain, the function of some brain regions is out of balance, leading to the lack of coordination between thoughts, actions, and emotions. This study provides various intelligent Deep Learning (DL)-based methods for automated SZ diagnosis via EEG signals. The obtained results are compared with those of conventional intelligent methods. In order to implement the proposed methods, the dataset of the Institute of Psychiatry and Neurology in Warsaw, Poland, has been used. First, EEG signals are divided into 25-seconds time frames and then were normalized by z-score or norm L2. In the classification step, two different approaches are considered for SZ diagnosis via EEG signals. In this step, the classification of EEG signals is first carried out by conventional DL methods, e.g., KNN, DT, SVM, Bayes, bagging, RF, and ET. Various proposed DL models, including LSTMs, 1D-CNNs, and 1D-CNN-LSTMs, are used in the following. In this step, the DL models were implemented and compared with different activation functions. Among the proposed DL models, the CNN-LSTM architecture has had the best performance. In this architecture, the ReLU activation function and the z-score and L2 combined normalization are used. The proposed CNN-LSTM model has achieved an accuracy percentage of 99.25\%, better than the results of most former studies in this field. It is worth mentioning that in order to perform all simulations, the k-fold cross-validation method with k=5 has been used.