 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Wind of Change: Detecting and Evaluating Lexical Semantic Change across Times and Domains
Jun 07, 2019
We perform an interdisciplinary large-scale evaluation for detecting lexical semantic divergences in a diachronic and in a synchronic task: semantic sense changes across time, and semantic sense changes across domains. Our work addresses the superficialness and lack of comparison in assessing models of diachronic lexical change, by bringing together and extending benchmark models on a common state-of-the-art evaluation task. In addition, we demonstrate that the same evaluation task and modelling approaches can successfully be utilised for the synchronic detection of domain-specific sense divergences in the field of term extraction.
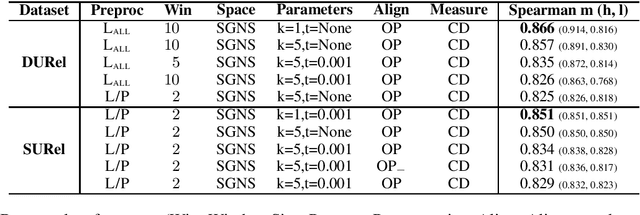
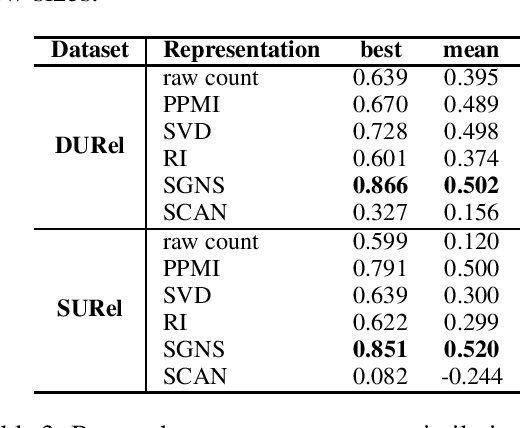
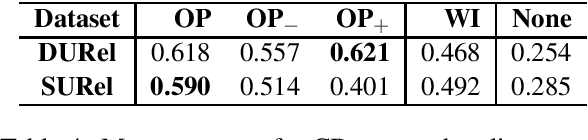
Second-order Co-occurrence Sensitivity of Skip-Gram with Negative Sampling
Jun 07, 2019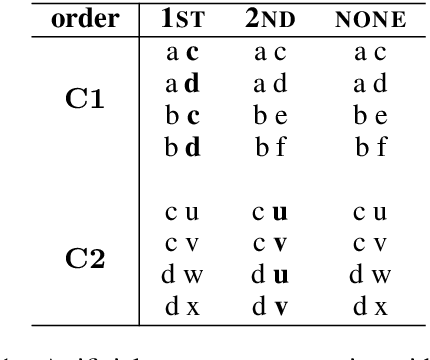
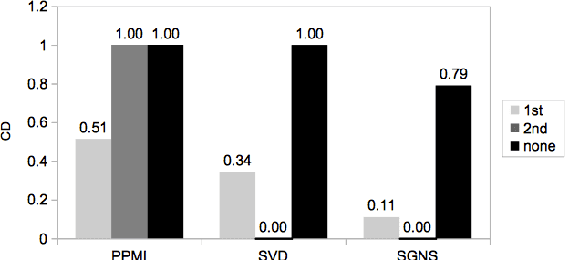
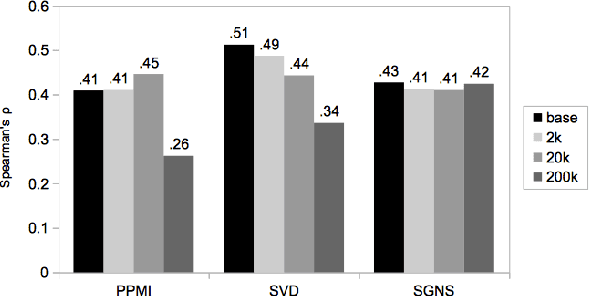
We simulate first- and second-order context overlap and show that Skip-Gram with Negative Sampling is similar to Singular Value Decomposition in capturing second-order co-occurrence information, while Pointwise Mutual Information is agnostic to it. We support the results with an empirical study finding that the models react differently when provided with additional second-order information. Our findings reveal a basic property of Skip-Gram with Negative Sampling and point towards an explanation of its success on a variety of tasks.
Projecting Embeddings for Domain Adaptation: Joint Modeling of Sentiment Analysis in Diverse Domains
Jun 13, 2018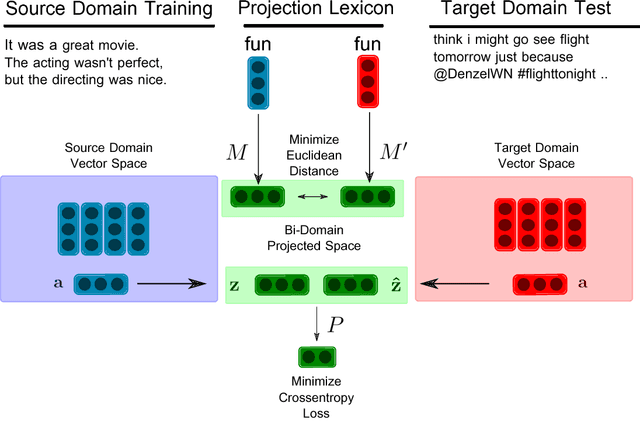
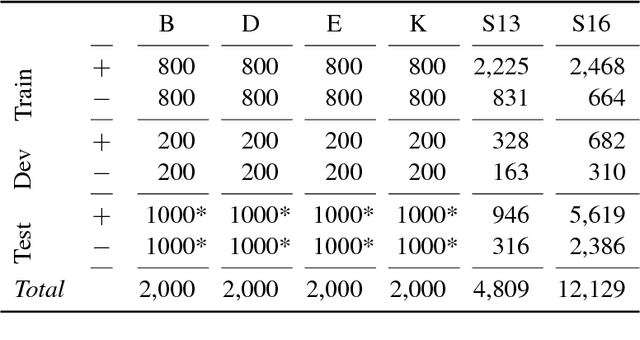

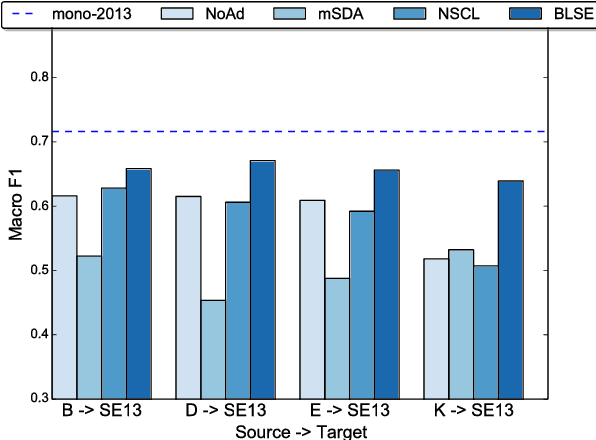
Domain adaptation for sentiment analysis is challenging due to the fact that supervised classifiers are very sensitive to changes in domain. The two most prominent approaches to this problem are structural correspondence learning and autoencoders. However, they either require long training times or suffer greatly on highly divergent domains. Inspired by recent advances in cross-lingual sentiment analysis, we provide a novel perspective and cast the domain adaptation problem as an embedding projection task. Our model takes as input two mono-domain embedding spaces and learns to project them to a bi-domain space, which is jointly optimized to (1) project across domains and to (2) predict sentiment. We perform domain adaptation experiments on 20 source-target domain pairs for sentiment classification and report novel state-of-the-art results on 11 domain pairs, including the Amazon domain adaptation datasets and SemEval 2013 and 2016 datasets. Our analysis shows that our model performs comparably to state-of-the-art approaches on domains that are similar, while performing significantly better on highly divergent domains. Our code is available at https://github.com/jbarnesspain/domain_blse
Bilingual Sentiment Embeddings: Joint Projection of Sentiment Across Languages
May 23, 2018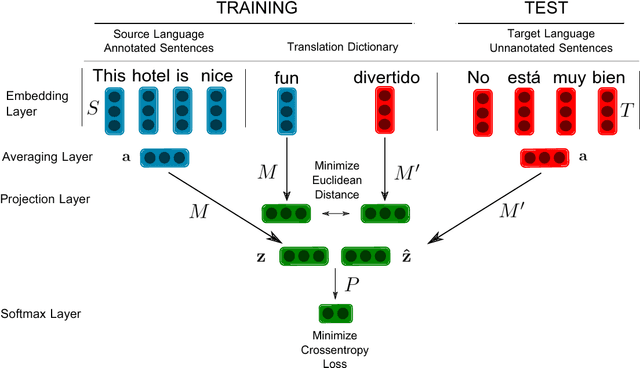
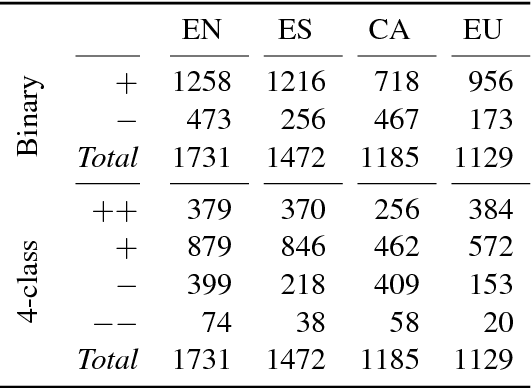
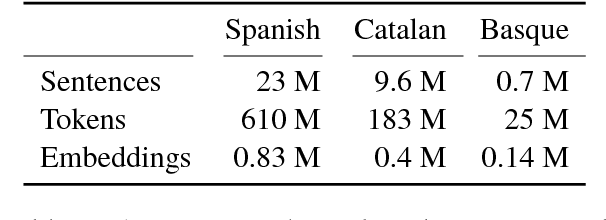
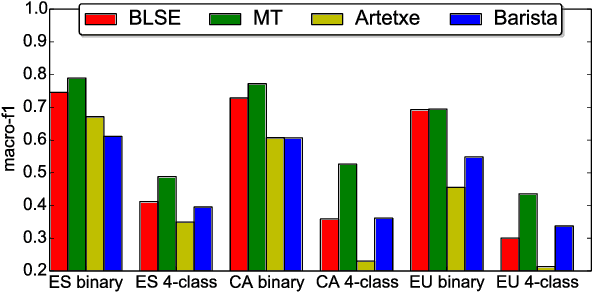
Sentiment analysis in low-resource languages suffers from a lack of annotated corpora to estimate high-performing models. Machine translation and bilingual word embeddings provide some relief through cross-lingual sentiment approaches. However, they either require large amounts of parallel data or do not sufficiently capture sentiment information. We introduce Bilingual Sentiment Embeddings (BLSE), which jointly represent sentiment information in a source and target language. This model only requires a small bilingual lexicon, a source-language corpus annotated for sentiment, and monolingual word embeddings for each language. We perform experiments on three language combinations (Spanish, Catalan, Basque) for sentence-level cross-lingual sentiment classification and find that our model significantly outperforms state-of-the-art methods on four out of six experimental setups, as well as capturing complementary information to machine translation. Our analysis of the resulting embedding space provides evidence that it represents sentiment information in the resource-poor target language without any annotated data in that language.
Introducing two Vietnamese Datasets for Evaluating Semantic Models of (Dis-)Similarity and Relatedness
Apr 19, 2018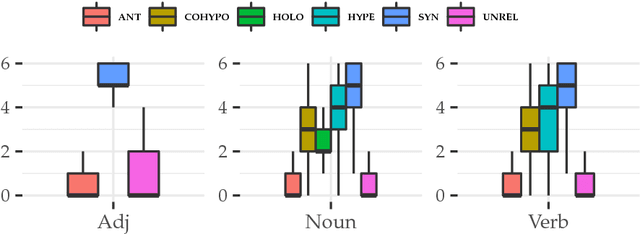
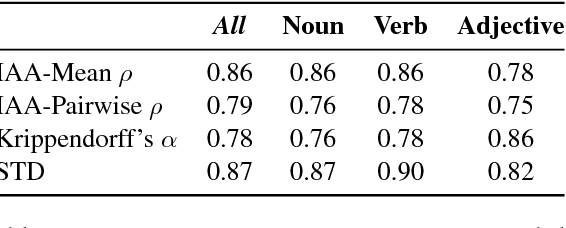
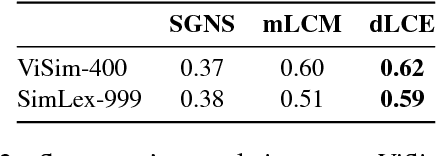
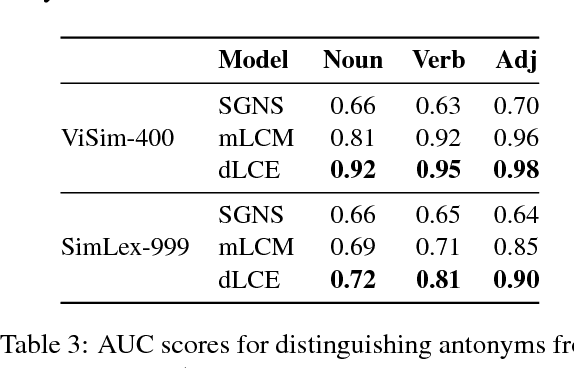
We present two novel datasets for the low-resource language Vietnamese to assess models of semantic similarity: ViCon comprises pairs of synonyms and antonyms across word classes, thus offering data to distinguish between similarity and dissimilarity. ViSim-400 provides degrees of similarity across five semantic relations, as rated by human judges. The two datasets are verified through standard co-occurrence and neural network models, showing results comparable to the respective English datasets.
Diachronic Usage Relatedness (DURel): A Framework for the Annotation of Lexical Semantic Change
Apr 18, 2018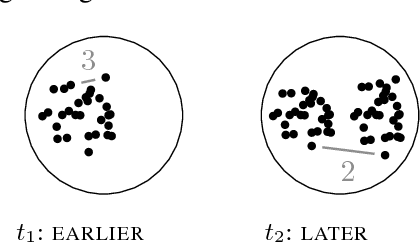


We propose a framework that extends synchronic polysemy annotation to diachronic changes in lexical meaning, to counteract the lack of resources for evaluating computational models of lexical semantic change. Our framework exploits an intuitive notion of semantic relatedness, and distinguishes between innovative and reductive meaning changes with high inter-annotator agreement. The resulting test set for German comprises ratings from five annotators for the relatedness of 1,320 use pairs across 22 target words.
Distribution-based Prediction of the Degree of Grammaticalization for German Prepositions
Apr 14, 2018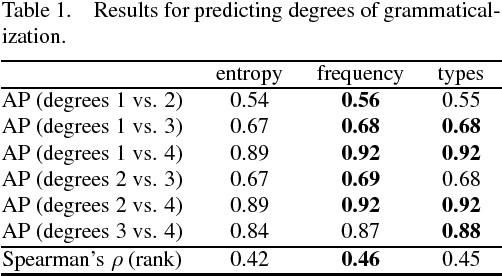
We test the hypothesis that the degree of grammaticalization of German prepositions correlates with their corpus-based contextual dispersion measured by word entropy. We find that there is indeed a moderate correlation for entropy, but a stronger correlation for frequency and number of context types.
Assessing State-of-the-Art Sentiment Models on State-of-the-Art Sentiment Datasets
Sep 13, 2017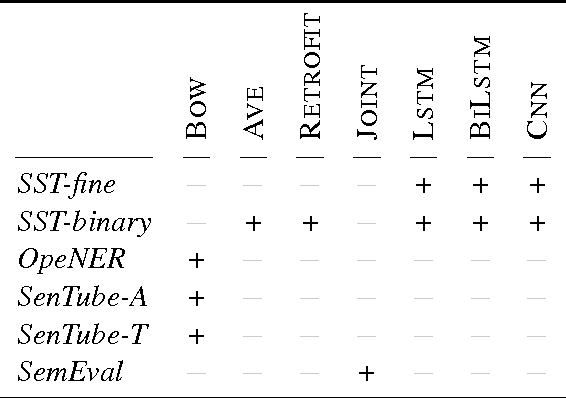
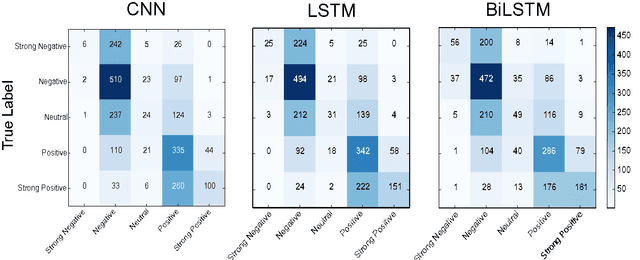
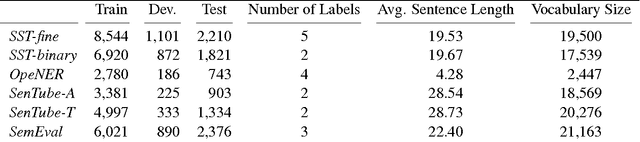
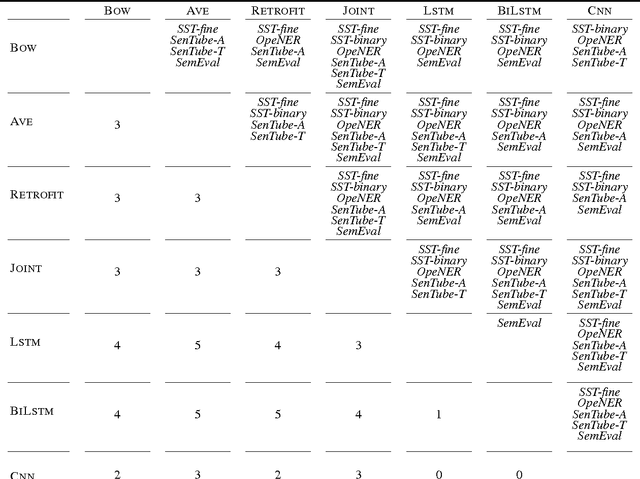
There has been a good amount of progress in sentiment analysis over the past 10 years, including the proposal of new methods and the creation of benchmark datasets. In some papers, however, there is a tendency to compare models only on one or two datasets, either because of time restraints or because the model is tailored to a specific task. Accordingly, it is hard to understand how well a certain model generalizes across different tasks and datasets. In this paper, we contribute to this situation by comparing several models on six different benchmarks, which belong to different domains and additionally have different levels of granularity (binary, 3-class, 4-class and 5-class). We show that Bi-LSTMs perform well across datasets and that both LSTMs and Bi-LSTMs are particularly good at fine-grained sentiment tasks (i. e., with more than two classes). Incorporating sentiment information into word embeddings during training gives good results for datasets that are lexically similar to the training data. With our experiments, we contribute to a better understanding of the performance of different model architectures on different data sets. Consequently, we detect novel state-of-the-art results on the SenTube datasets.
* Presented at WASSA 2017
Hierarchical Embeddings for Hypernymy Detection and Directionality
Jul 23, 2017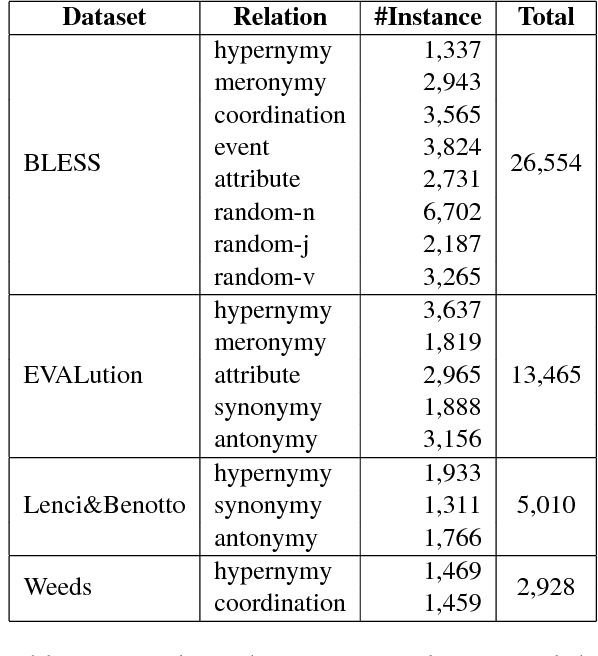
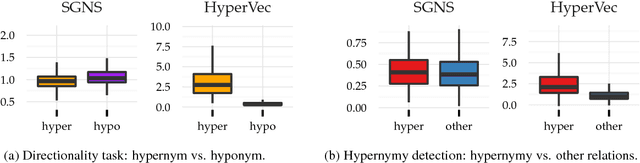
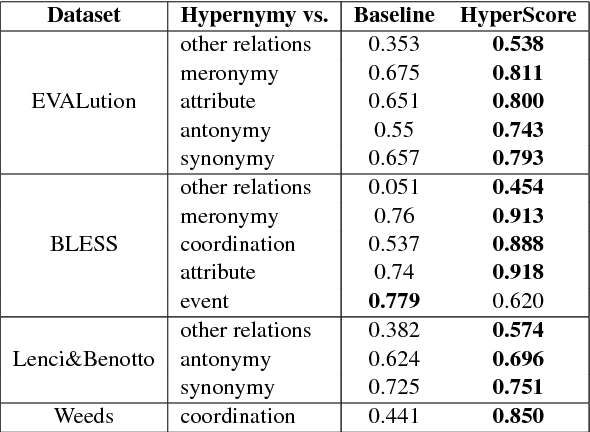
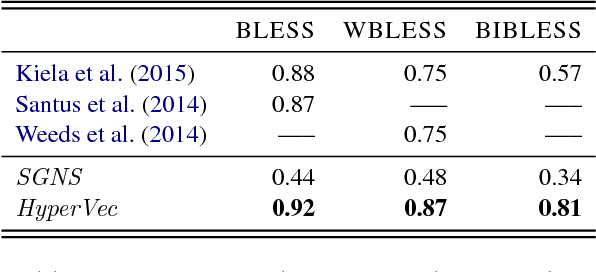
We present a novel neural model HyperVec to learn hierarchical embeddings for hypernymy detection and directionality. While previous embeddings have shown limitations on prototypical hypernyms, HyperVec represents an unsupervised measure where embeddings are learned in a specific order and capture the hypernym$-$hyponym distributional hierarchy. Moreover, our model is able to generalize over unseen hypernymy pairs, when using only small sets of training data, and by mapping to other languages. Results on benchmark datasets show that HyperVec outperforms both state$-$of$-$the$-$art unsupervised measures and embedding models on hypernymy detection and directionality, and on predicting graded lexical entailment.
German in Flux: Detecting Metaphoric Change via Word Entropy
Jun 15, 2017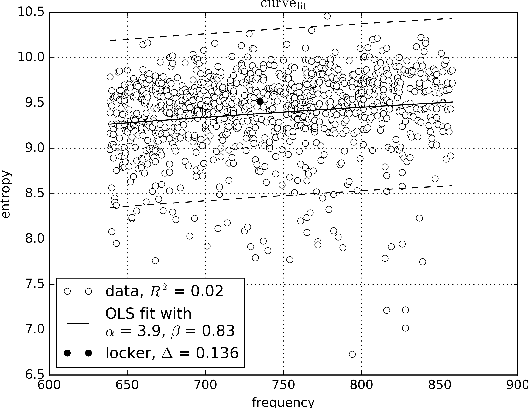
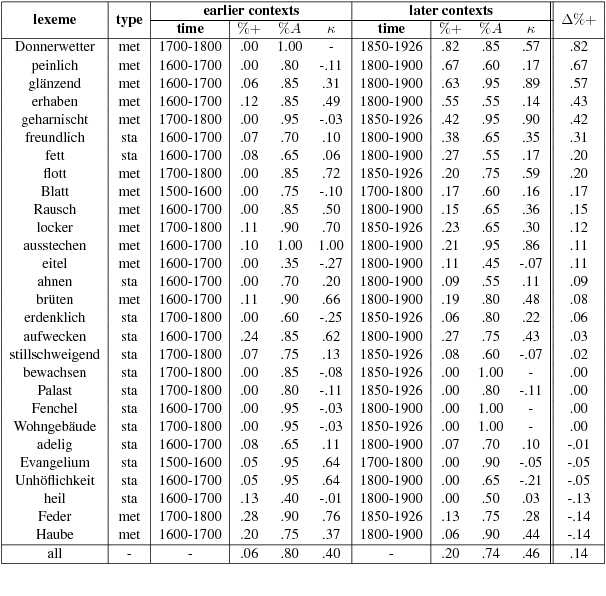

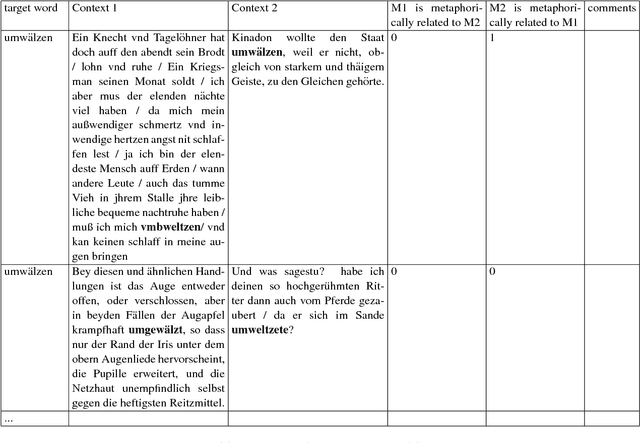
This paper explores the information-theoretic measure entropy to detect metaphoric change, transferring ideas from hypernym detection to research on language change. We also build the first diachronic test set for German as a standard for metaphoric change annotation. Our model shows high performance, is unsupervised, language-independent and generalizable to other processes of semantic change.