 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttentive Neural Network for Named Entity Recognition in Vietnamese
Oct 31, 2018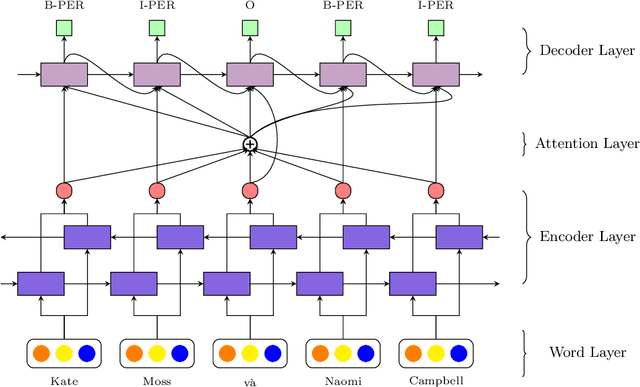
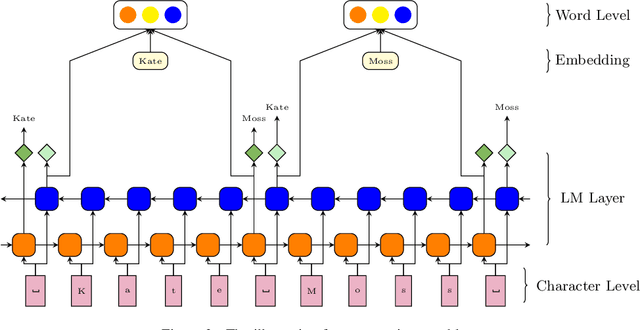
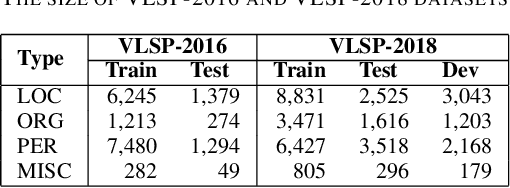
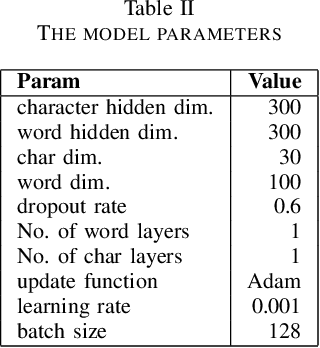
We propose an attentive neural network for the task of named entity recognition in Vietnamese. The proposed attentive neural model makes use of character-based language models and word embeddings to encode words as vector representations. A neural network architecture of encoder, attention, and decoder layers is then utilized to encode knowledge of input sentences and to label entity tags. The experimental results show that the proposed attentive neural network achieves the state-of-the-art results on the benchmark named entity recognition datasets in Vietnamese in comparison to both hand-crafted features based models and neural models.
Introducing two Vietnamese Datasets for Evaluating Semantic Models of (Dis-)Similarity and Relatedness
Apr 19, 2018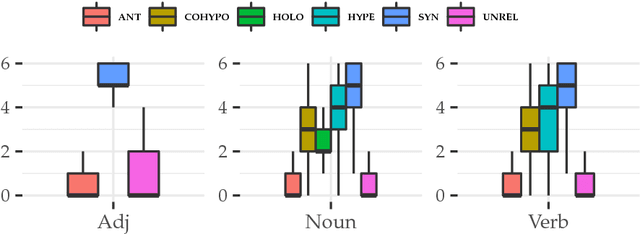
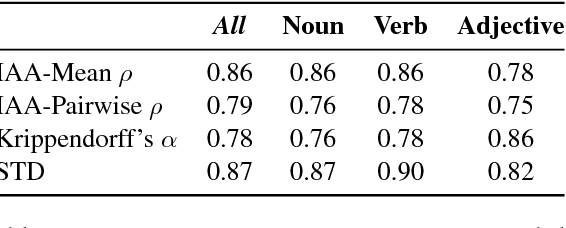
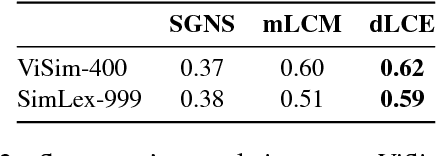
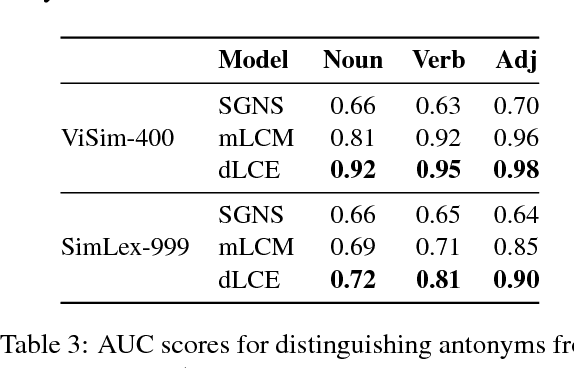
We present two novel datasets for the low-resource language Vietnamese to assess models of semantic similarity: ViCon comprises pairs of synonyms and antonyms across word classes, thus offering data to distinguish between similarity and dissimilarity. ViSim-400 provides degrees of similarity across five semantic relations, as rated by human judges. The two datasets are verified through standard co-occurrence and neural network models, showing results comparable to the respective English datasets.
Hierarchical Embeddings for Hypernymy Detection and Directionality
Jul 23, 2017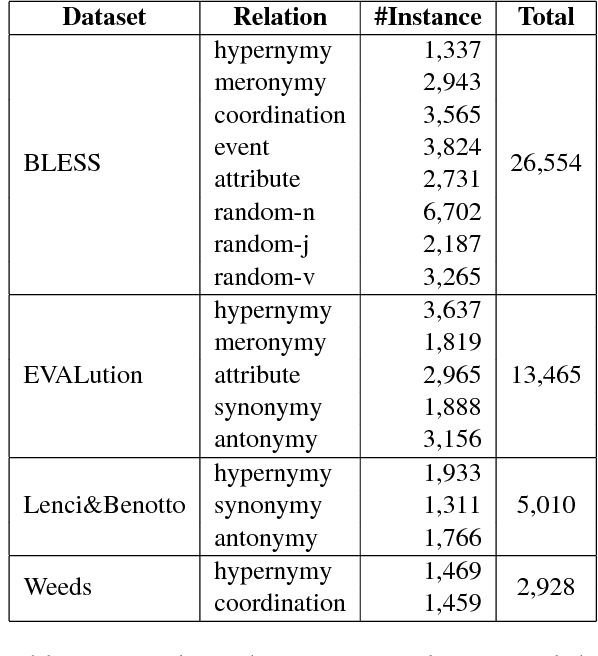
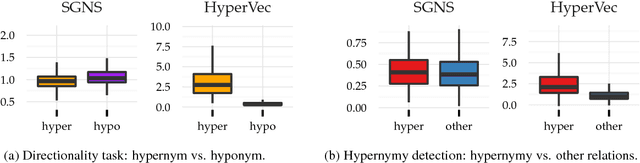
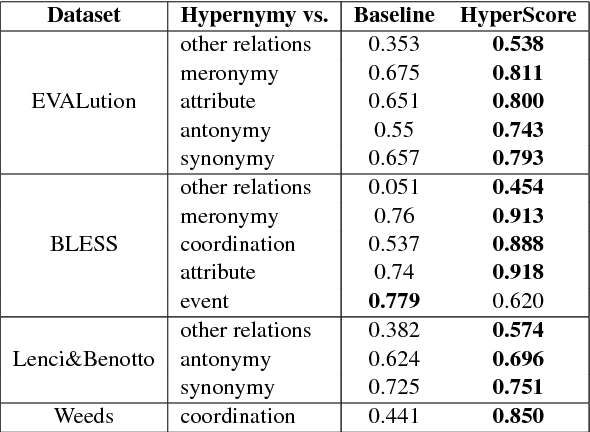
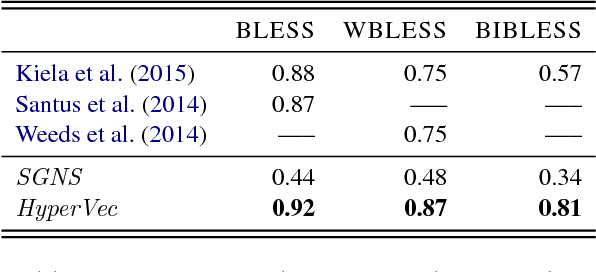
We present a novel neural model HyperVec to learn hierarchical embeddings for hypernymy detection and directionality. While previous embeddings have shown limitations on prototypical hypernyms, HyperVec represents an unsupervised measure where embeddings are learned in a specific order and capture the hypernym$-$hyponym distributional hierarchy. Moreover, our model is able to generalize over unseen hypernymy pairs, when using only small sets of training data, and by mapping to other languages. Results on benchmark datasets show that HyperVec outperforms both state$-$of$-$the$-$art unsupervised measures and embedding models on hypernymy detection and directionality, and on predicting graded lexical entailment.
Distinguishing Antonyms and Synonyms in a Pattern-based Neural Network
Jan 11, 2017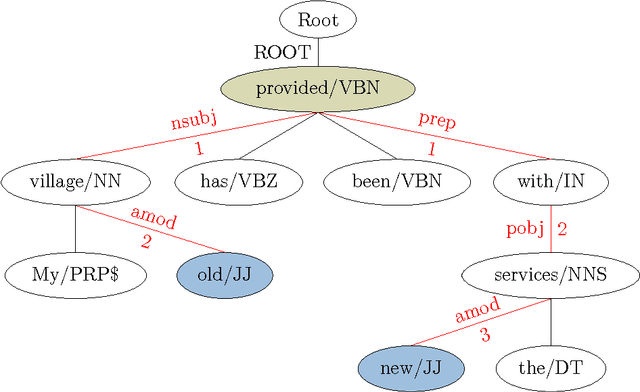
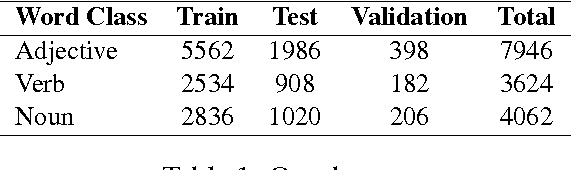
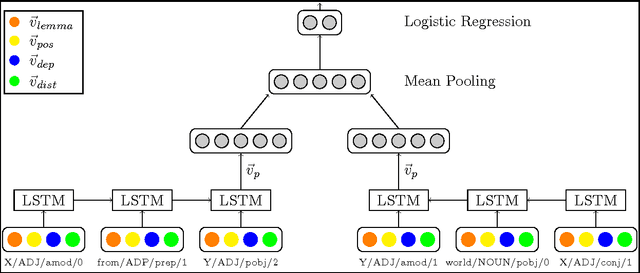
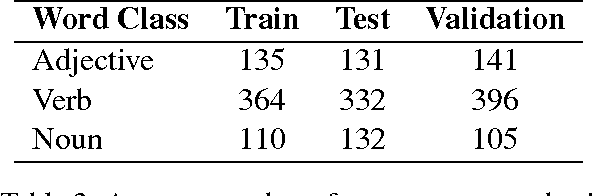
Distinguishing between antonyms and synonyms is a key task to achieve high performance in NLP systems. While they are notoriously difficult to distinguish by distributional co-occurrence models, pattern-based methods have proven effective to differentiate between the relations. In this paper, we present a novel neural network model AntSynNET that exploits lexico-syntactic patterns from syntactic parse trees. In addition to the lexical and syntactic information, we successfully integrate the distance between the related words along the syntactic path as a new pattern feature. The results from classification experiments show that AntSynNET improves the performance over prior pattern-based methods.
* EACL 2017, 10 pages
Neural-based Noise Filtering from Word Embeddings
Oct 06, 2016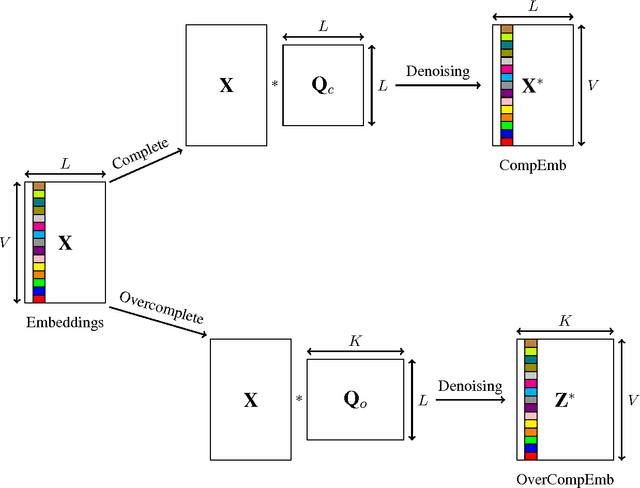
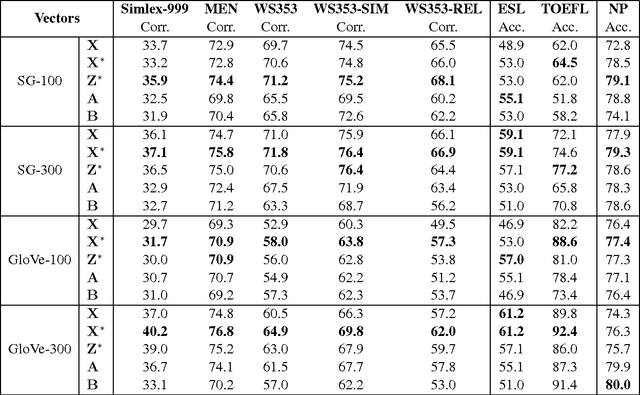
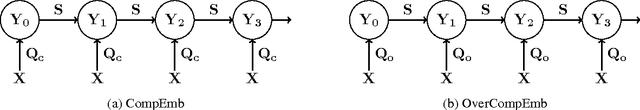
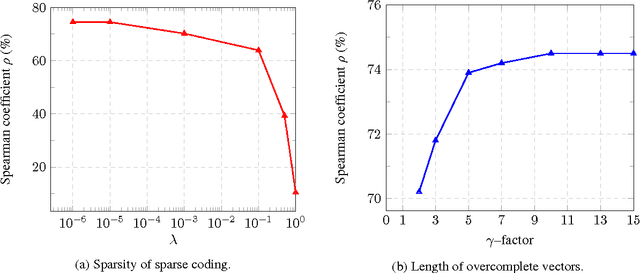
Word embeddings have been demonstrated to benefit NLP tasks impressively. Yet, there is room for improvement in the vector representations, because current word embeddings typically contain unnecessary information, i.e., noise. We propose two novel models to improve word embeddings by unsupervised learning, in order to yield word denoising embeddings. The word denoising embeddings are obtained by strengthening salient information and weakening noise in the original word embeddings, based on a deep feed-forward neural network filter. Results from benchmark tasks show that the filtered word denoising embeddings outperform the original word embeddings.
Integrating Distributional Lexical Contrast into Word Embeddings for Antonym-Synonym Distinction
May 25, 2016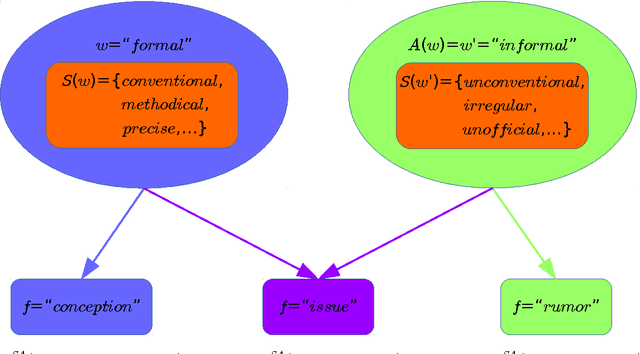
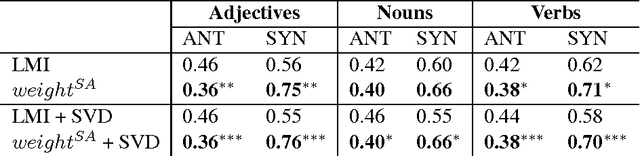
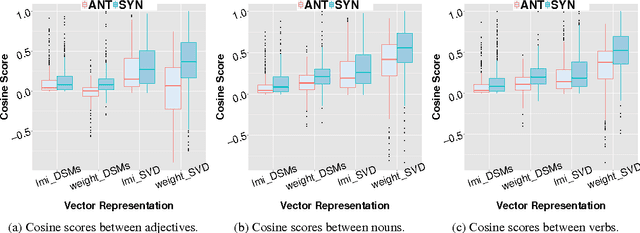

We propose a novel vector representation that integrates lexical contrast into distributional vectors and strengthens the most salient features for determining degrees of word similarity. The improved vectors significantly outperform standard models and distinguish antonyms from synonyms with an average precision of 0.66-0.76 across word classes (adjectives, nouns, verbs). Moreover, we integrate the lexical contrast vectors into the objective function of a skip-gram model. The novel embedding outperforms state-of-the-art models on predicting word similarities in SimLex-999, and on distinguishing antonyms from synonyms.